Kafka 如何保证高可用?
Kafka?的基本架构组成是:由多个?broker?组成一个集群,每个?broker?是一个节点;当创建一个?topic?时,这个?topic?会被划分为多个?partition,每个?partition?可以存在于不同的?broker?上,每个?partition?只存放一部分数据。
这就是天然的分布式消息队列,就是说一个?topic?的数据,是分散放在多个机器上的,每个机器就放一部分数据。
在?Kafka?0.8?版本之前,是没有?HA?机制的,当任何一个?broker?所在节点宕机了,这个?broker?上的?partition?就无法提供读写服务,所以这个版本之前,Kafka?没有什么高可用性可言。
在?Kafka?0.8?以后,提供了?HA?机制,就是?replica?副本机制。每个?partition?上的数据都会同步到其它机器,形成自己的多个?replica?副本。所有?replica?会选举一个?leader?出来,消息的生产者和消费者都跟这个?leader?打交道,其他?replica?作为?follower。写的时候,leader?会负责把数据同步到所有?follower?上去,读的时候就直接读?leader?上的数据即可。Kafka?负责均匀的将一个?partition?的所有?replica?分布在不同的机器上,这样才可以提高容错性。
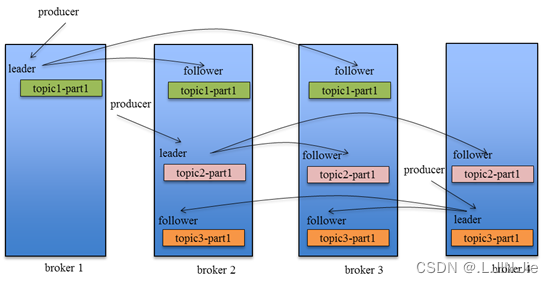 拥有了?replica?副本机制,如果某个?broker?宕机了,这个?broker?上的?partition?在其他机器上还存在副本。如果这个宕机的?broker?上面有某个?partition?的?leader,那么此时会从其?follower?中重新选举一个新的?leader?出来,这个新的?leader?会继续提供读写服务,这就有达到了所谓的高可用性。
拥有了?replica?副本机制,如果某个?broker?宕机了,这个?broker?上的?partition?在其他机器上还存在副本。如果这个宕机的?broker?上面有某个?partition?的?leader,那么此时会从其?follower?中重新选举一个新的?leader?出来,这个新的?leader?会继续提供读写服务,这就有达到了所谓的高可用性。
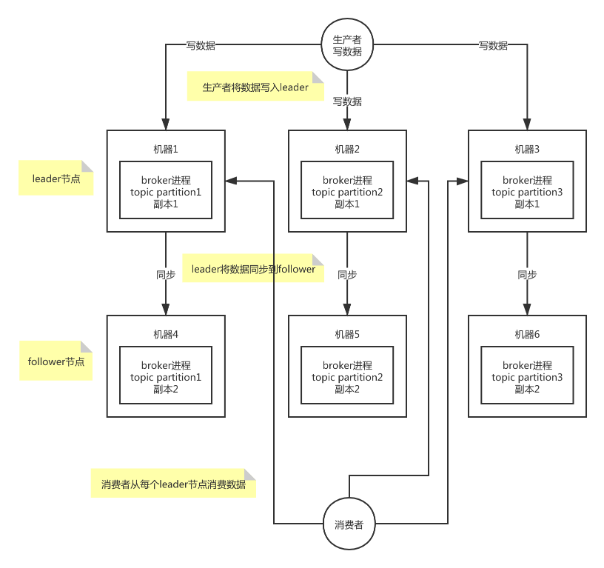
写数据的时候,生产者只将数据写入?leader?节点,leader?会将数据写入本地磁盘,接着其他?follower?会主动从?leader?来拉取数据,follower?同步好数据了,就会发送?ack?给?leader,leader?收到所有?follower?的?ack?之后,就会返回写成功的消息给生产者。
消费数据的时候,消费者只会从?leader?节点去读取消息,但是只有当一个消息已经被所有?follower?都同步成功返回?ack?的时候,这个消息才会被消费者读到。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!