统计学-R语言-5.1
前言
从本篇文章开始介绍有关概率与分布的介绍。
随机性和规律性
当不能预测一件事情的结果时,这件事就和随机性联系起来了。
随机性和规律性是事物的正反面,是相对统一的。单个的事情可 能具有随机性。
例如,掷硬币时,我们并不能够确定硬币将正面朝上还是反面朝上。但是,当把大量的随机事件放在一起时,它们会表现出令人惊奇的规律性。
例题:
模拟扔硬币,了解随机性和规律性的相对统一
a=sample(c("H","T"),10,replace=T)
table(a)
a
H T
7 3
a=sample(c("H","T"),100,replace=T)
table(a)
a
H T
57 43
a=sample(c("H","T"),10000,replace=T)
table(a)
a
H T
5007 4993
分别扔10、100、10000次,当扔硬币的次数越来越多时,正面和反面朝上的次数越来越接近,结果可以说相当地稳定
但是规律也表现出随机性。实际上如果重复扔10次硬币,大部分 时候并不能得到和上次观察一模 一样的结果。
通过对看起来随机的现象进行统计分析,统计知识能够帮助我们把随机性归纳到可能的规律性中。
统计从如何观察事物和事物本身如何真正发生这两个方面帮助我们理解随机性和规律性的重要性因此,统计可以看做一项对随机性中的规律性的研究。
概率
对事件发生可能性大小的一种数值度量就是概率
概率(probability)是一个0~1之间的数,它告诉我们某一事件发生的机会有多大。
概率为统计推断奠定了基础。在学习完第4、5章后会知道可能永远也不能确定两个数字的差异是否超出了随机性本身所能解释的范围,但是可以确定这种差异发生的概率是大还是小。
因此,在很多情况下,我们可以得出关于我们所处的这个世界的重要结论。
用软件很容易计算概率,考虑无放回抽样的情形,如sample(1:100,5)
得到一个给定数字作为第一个样本的概率是1/100,第二个则是1/99,依此类推,则给定一个样本的概率就是1/( )
在R中,使用prod函数计算一串数字的乘积:
1/prod(100:96)
[1] 1.106868e-10
注意,这是一个在给定顺序下获得给定数字的概率。
然而,我们更感兴趣的是正确猜出5个给定的数字集合的概率(这五个数的顺序可以不同)。因此,需要计算从100个数字中选取5个的所有可能数。
从100个数字中选取5个的所有可能数,它是一个排列组合数
在R中,可以用choose函数来计算这个数字,所以上述概率可以写成:
1/choose(100,5)
[1] 1.328241e-08
有其他方法得到同样的结果。很明显,由于每种情况的概率都是相同的,我们需要做的就是输出一共有多少种这样的情形。
第一个数字有5种可能,对其中每一种情况的第二个数字又有4种可能,以此类推,从而可能的种数 ,即5!(5的阶乘)
所以选出这5个数的概率为
prod (5:1) /prod (100:96)
[1] 1.328241e-08
变量的分布
事先不知道会出现什么结果
投掷两枚硬币出现正面的数量
一个消费者对某一特定品牌饮料的偏好
随机变量是用数值来描述特定实验一切可能出现的结果,它的取值事先不能确定,具有随机性。在扔硬币的活动中,结果总是随机出现的,因此把得到的结果称为随机变量(random variable)
一般用 X,Y,Z 来表示
根据取值情况的不同分为离散型随机变量和连续型随机变量这就是是随机变量。
随机变量取哪些值,取这些值的概率有多大,这就是随机变量的概率分布,随机变量取一切可能值或范围的概率或概率的规律称为概率分布(probability distribution,简称分布) 。
一般表示为累积分布函数F (x )= 𝑃(𝑋 ≤ 𝑥),描述的是对一个给定分布小于或等于x的分布的概率。
我们为什么需要概率分布呢?
不管喜不喜欢数学课,同学们一定记得“小九九”。“小九九”是学习乘法的第一课,也是最重要的乘法口诀。千变万化的乘法运算都是从“小九九”演化而来的。
统计学也有自己的“小九九”,它是从很多典型概率问题中总结出的经验,我们称为概率分布,简称分布。它可以帮助我们解决很多常见的概率统计问题,既简洁又高效。
如果我们知道了一个随机变量的概率分布模型,就很容易确定一系列事件发生的概率。
比如一个班级学生成绩可以用均值85,标准差10 的正态分布(下面即将介绍该分布)来刻画。那么,这个班级中有百分之多少的学生比90分高?R软件的计算如下:
1-pnorm(90,mean=85,sd=10)
[1] 0.3085375
pnorm():输入的是x这一点,输出的是面积,不带参数输出的是该点右边的面积,如果后面带lower.tail=F的参数,输出的是该点左边的面积。
如果一个学生的成绩为90分,则这个班级中只有30.85%的学生是这个分数或者比这更高。
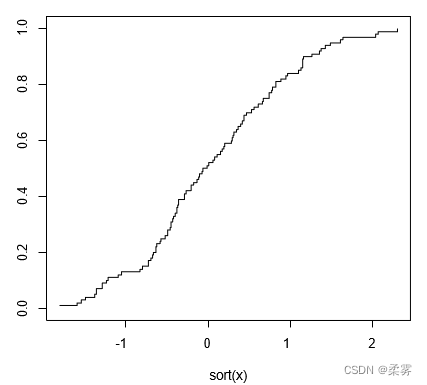
在得不到真实的累积分布函数时,可以考虑经验累积分布函数,其定义为小于等于x的数据占全部数据的比例。也就是说,如果x是第k小的观测值,那么小于等于x的数据的比例为k/n。我们可以做出一个经验累积分布函数图:
x=rnorm(100);n=length(x)
plot(sort(x),(1:n)/n,type="s",ylim=c(0,1))
plot()函数画图:
plot(x=x轴数据,y=y轴数据,main=“标题”,sub=“子标题”,type=“线型”,xlab=“x轴名称”,ylab=“y轴名称”,xlim = c(x轴范围,x轴范围),ylim = c(y轴范围,y轴范围))
plot(c(1:6),c(1:6),main="test",type=" ",xlim = c(0,7),ylim = c(0,7))
离散随机变量的所有可能取值是有限个或可列个数值,比如离散随机变量X取值为x1,x2,…,xn,那么事件X=xi发生概率p(xi)的全体就是离散型概率分布,也称为概率分布列。
随机变量X 具有概率分布, 可以用点概率 p(x)=P(X=x)或累积分布函数F(x)=P(X≤x)描述, 还可以采用表格的形式展示概率分布列。
离散型概率分布必须满足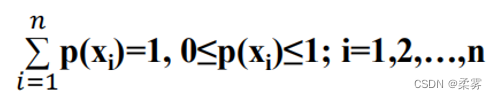
在现实中有许多广泛应用的离散型概率分布,它们可以使用一般公式来表达,只要给定随机变量的任意一个取值,就可以直接计算出概率。
离散型–二项、泊松、几何
二项分布
当观察一个独立重复二项试验时,通常对每次试验的成功或失败并不感兴趣,更感兴趣的是成功的总数,此时就是二项分布(binomial distribution)
分布可以用点概率来得到(二项分布的通用表达):
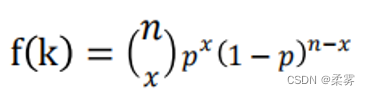
这就是已知的二项分布, 是二项系数。参数p是一次独立试验中成功的概率。
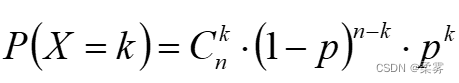
二项分布来源于伯努利试验,所谓伯努利试验就是只有两种可能结果的随机试验,比如抛硬币。当一个伯努利试验独立地重复进行n次时,就是n重伯努利试验,二项分布可以告诉我们各种可能的结果发生的概率。
n重伯努利试验满足下列条件
一次试验只有两个可能结果,即“成功”和“失败”
“成功”是指我们感兴趣的某种特征
一次试验“成功”的概率为p ,失败的概率为q =1- p,且概率p对每次试验都是相同的
试验是相互独立的,并可以重复进行n次
在n次试验中,“成功”的次数对应一个离散型随机变量X 。
重复进行 n 次试验,出现“成功”次数的概率分布,记为X~B(n,p)
设X为 n 次重复试验中出现成功的次数,X 取 x 的概率为
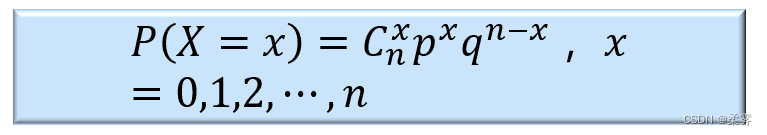

示例:
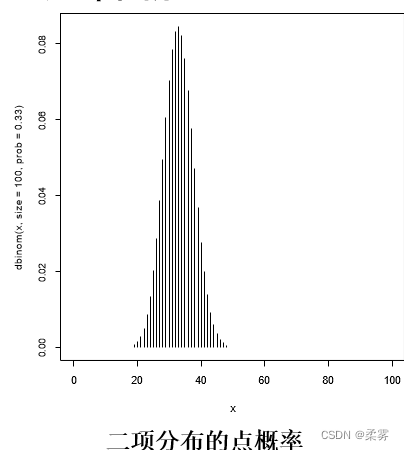
在R软件中使用下面的命令,就可以得到如下图所示的n=100,p=0.33的二项分布图形
x=0:100
plot(x,dbinom(x,size=100,prob=.33),type="h")type="h"画出针形图
#dbinom()该函数给出服从二项分布每个点的概率密度分布
注意,在画出二项分布的点概率图时,除了x,还要指定试验次数n和概率p
以上画出的分布可以理解为投掷一个公平的骰子100次,出现1点或2点的次数。
plot函数中参数type=“h”#类似直方图的线
密度函数:
dbinom(x, size, prob):x发生的概率 P(x)
分布函数:
pbinom(q, size, prob):≤q 的事件累积概率 F(q)
#x、q为实验结果;p为累积概率。
plot函数中参数type=“h”#类似直方图的线。
密度函数: dbinom(x, size, prob):x发生的概率 P(x)
分布函数:pbinom(q, size, prob):≤q 的事件累积概率 F(q)
例:已知某批鸡蛋的孵出率prob为0.9,抽取5个鸡蛋检查其孵化情况,这5个鸡蛋孵出1、2、3、4、5个小鸡的概率分别是多少?

密度函数: dbinom(x, size, prob):x发生的概率 P(x)
分布函数:pbinom(q, size, prob):≤q 的事件累积概率 F(q)
例:电视台的某个节目,官方预估收视率为25%,当我们电话访问了1500人之后,发现收看率只有23%。官方预估的数据准确吗?
计算1500个样本中出现23%收视率的概率,概率太小就可以,以此否定官方的数据。
pbinom(1500*0.23,1500,0.25)//出现这种情况的概率是0.03836649,这么小概率的事件被我们碰到了,明显不可能,表明官方数据有水分。
二项分布是一个十分独特的分布,我们从它的分布图中可以看出些端倪。下图给出的是b(10,1/2)、b(10,1/3)、b(10,1/5)和b(10,1/10)的概率分布图,
我们观察四张图中的最高点:
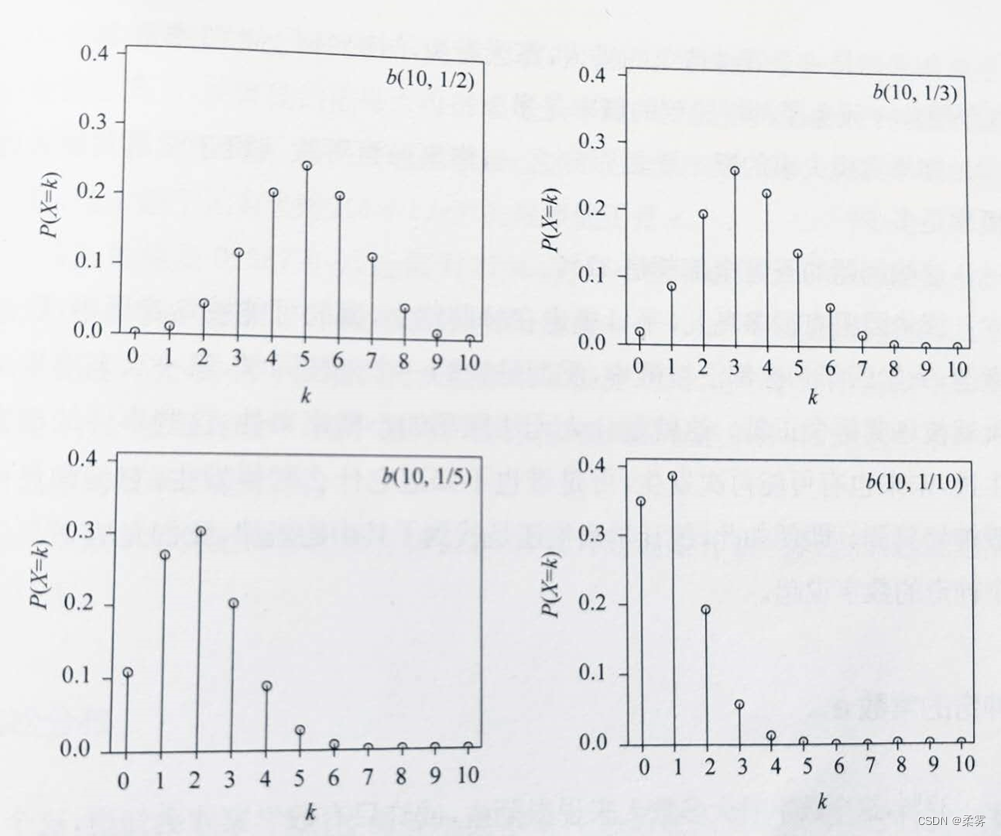
当p=1/2时,概率最高点出现在X=5的位置,概率分布关于最高点左右对称。
当P=1/3、1/5和1/10时,概率分布不再对称,最高点的位置分别出现在X=3、X=2和X=1,是不确定的。从这组分布图中可以看出,二项分布并没有固定的规律可循,只有画出概率分布图才能找到最高点,即概率的最大值。
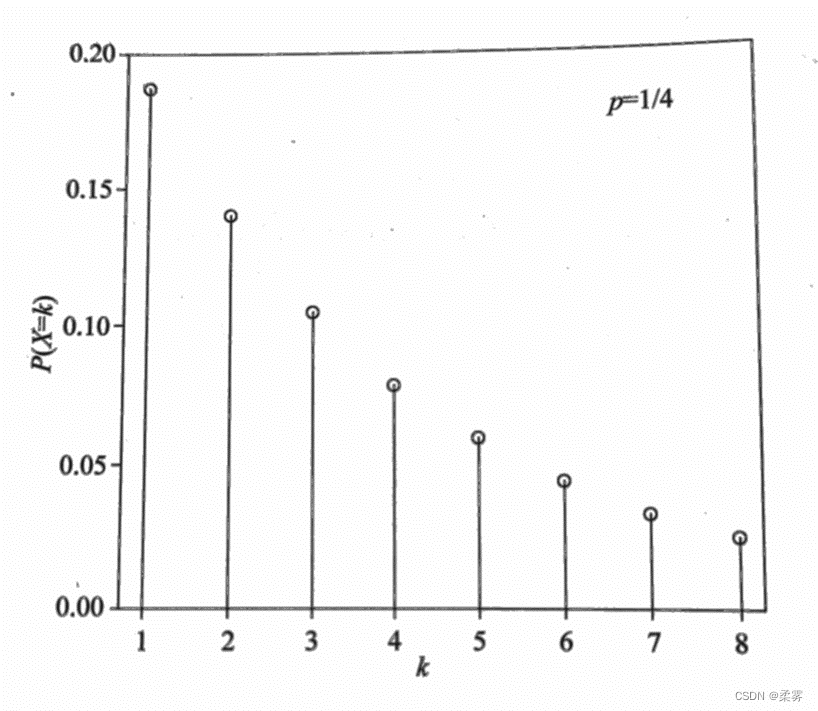
几何分布
几何分布(Geometric distribution)类似于二项分布,只是它记录的是第一次成功之前失败发生的次数。
几何分布的定义为:在n次独立重复二项试验中,试验k次才得到第一次成功的概率。即前k-1次都失败,第k次成功的概率为:
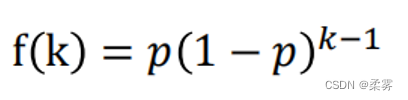
在R中画出p=0.33的几何分布图形,如下图所示:
x=0:100
plot(x,dgeom(x,prob=.33),type="h")
几何分布:n次伯努利试验,前n-1次皆失败,第n次才成功的概率。
密度函数:
dgeom(n,prob)
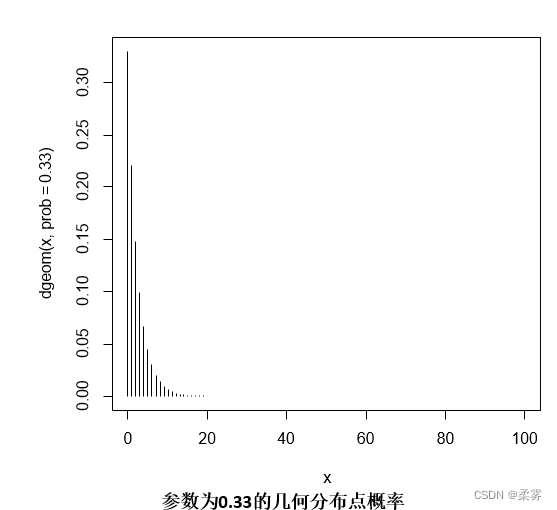
下图是几何分布的概率分布图,从图中可以明显地看出,虽然X的取值有无穷多个,但是X=1的概率是最大的,也就是说,1次成功的可能性最大。
几何分布是一个无限可列的概率分布,要计算它的期望和方差需要使用些数列求和的计算技巧,我们不细究这些计算技巧,直接给出几何分布的期望和方差。
E(X)=1/p
Var(X)=(1-p)/
几何分布的期望与我们的直觉不谋而合。比如,硬币出现反面的概率是1/2,那么平均意义上需要抛2次才会出现反面;子的六点出现的概率是1/6,那么平均意义上需要掷6次才能出现六点;中一次彩票大奖的概率是百万分之ー,那么平均意义上需要买一百万次才能中一次大奖。
泊松分布
如果你每天走在路上,被鸟粪砸中的概率刚好是1/365,你一年里一次都没被砸中的概率是多少?如果飞机失事的概率是百万分之一,你坐一百万次飞机还没遇到事故的概率是多少?
这些问题的答案全部都是37%
这些是让人无法预测的小概率事件,这些事件的确发生过,未来也有可能再次发生,可是谁也不知道它什么时候发生,它像幽灵般神秘莫测,即便如此,统计学家们还是找到了其中的规律,那么这个规律与我们今天要学习的这个泊松分布以及37%这个神奇的数字是相关联的。
神奇的常数e
37%,这个数字对大多数人来说很陌生,或许只有数学家才会知道,这个数字正是1/e的值。e是自然对数底,是个无限不循环小数,数值为2.7182…。提起数学中的常数,大多数人会首先想到π,其实,自然对数底e也是数学世界中十分重要的常数。
中彩票、飞机失事等小概率事件总是让人难以摸,它们很少发生,几乎无法预测,即便如此,概率统计还是有办法用数学公式来描述它们。泊松分布正是用来描述那些无法预测的小概率事件发生次数的分布,设随机变量X表示某事件发生的次数,若X服从泊松分布,则有: 
式中, λ为特定区间内事件发生(成功)的均值; 泊松分布的均值和方差都等于λ。
泊松分布(Poisson distribution)描述的是在特定区间内某种事件发生的次数,区间可以是时间、 距离、面积或者体积。下图是λ=1时的泊松分布图。
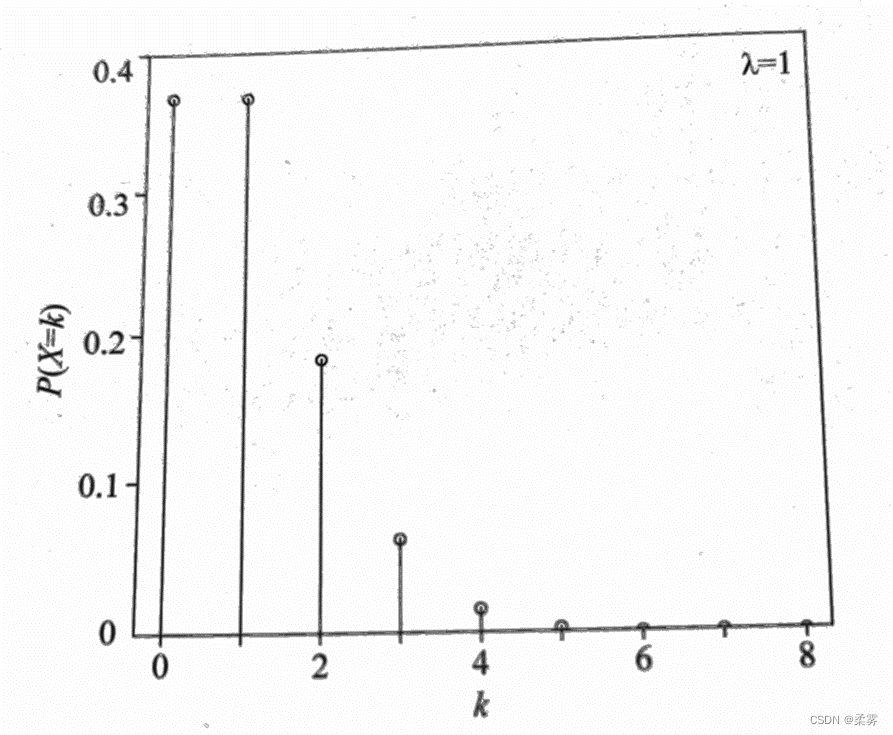
当k=0、=1时,P(X=0)=1/e,这便是小概率事件定律的数学原理(课后阅读,了解)
泊松分布在生活和科研中的应用十分广泛。比如每个小时进入银行办理业务的人数、报纸上每一页的错别字数量、某个网的点击量。网页的点击量?你肯定会对这个例子表示质疑,因为点击某个网页未必是小概率事件,如果这个网页是谷歌、百度的首页怎么办?答案是缩短时间跨度。泊松分布描述的是一个小概率事件在单位时间内发生的次数,这里的“单位时间”是可以任意指定的,对一个热门网页来说,一秒的点击量可能都有上万次,肯定算不上小概率事件,那么我们就把单位时间调整到一毫秒甚至一微秒,在那样的“单位时间”里,网页点击一定可以算作小概率事件了。另外,泊松分布所描述的事件一定是无法预测的随机事件,以网页点击来说,全球几十亿网民随时可能会点击某个网页,如此难以预测的事件一定是随机事件。
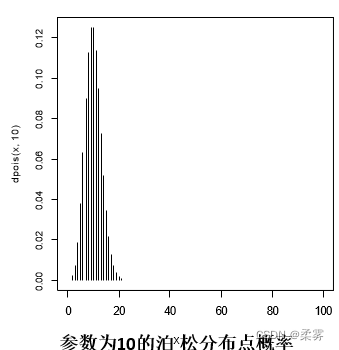
与二项分布一样,泊松分布也是一个分布族,族中不同成员的区别在于事件出现次数的均值λ不一 样。当事件发生的概率很小或者n值很大时,泊松分布是一种有限的二项分布。在求解概率题的过程中,如果n>20并且p<0.05,我们就可以用泊松来近似二项分布,这种近似会帮助我们大大简化计算过程,下图是λ=10时的泊松分布图形
x=0:100
plot(x,dpois(x,10),type="h")
连续型–均匀、正态
有些数据来自于对连续尺度的测量,比如温度、 浓度等。
连续随机变量是可以取某一个或若干个区间内任意数值的随机变量,因此是不可数的,这使得任何特定值的概率是零,所以,这里没有像离散型随机变量那样的点概率的说法,必须在某一区间内考虑相应的概率问题。
取代点概率的是密度的概念。它是指x的一个小邻域的无穷小概率除以区域的大小。此时,累积分布函数如下所示:
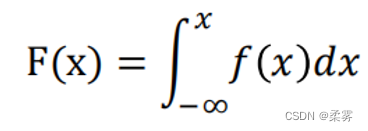
表示所有小于或等于x的值出现的概率之和。
均匀分布
常见的连续分布包括均匀分布和正态分布
均匀分布(uniform distribution) 是最简单的连续型分布,记为U(a, b),表示定义在一个比如 (a, b)这样特定的区间(通常为[0,1]),均匀分布在该区间上有常数密度1/(b?a)。
均匀分布的密度函数为:
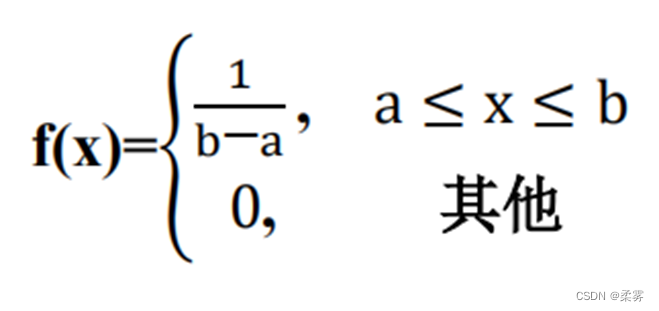
例题:
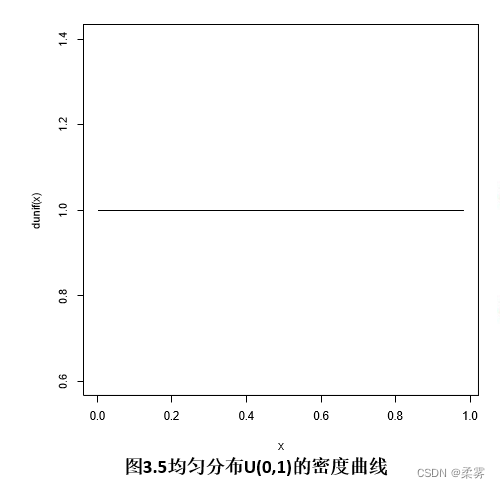
在R软件中使用下面的命令得到图3.5所示的均匀分布的密度曲线图
x=runif(100)
plot(x,dunif(x),type="l")
R语言中的runif()函数用于生成从0到1区间范围内的服从均匀态分布的随机数,每次生成的值都不一样;
均匀分布的密度函数为:
dunif(x,min,max)=1,恒定等于1/(max-min)。
plot()函数画图:
type=“1”#线型图:
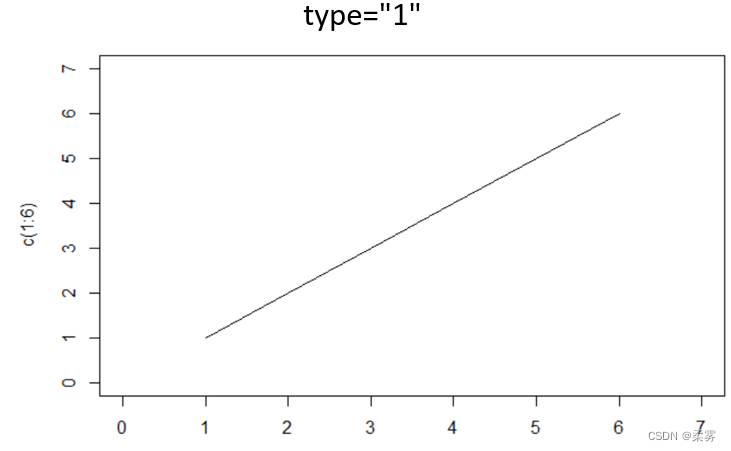
正态分布
正态分布最初由C.F.高斯(Carl Friedrich Gauss,1777—1855)作为描述误差相对频数分布的模型而提出。
描述连续型随机变量的最重要的分布
许多现象都可以由正态分布来描述 ,甚至当一个连续总体的分布未知,我们总尝试假设该总体服从正太分布进行分析。
可用于近似离散型随机变量的分布(对于二项分布的概率计算可以利用正态分布来近似)
例如: 二项分布
经典统计推断的基础(由正态分布还可以推导出其他一些重要的统计分布,如: 分布
t分布、F分布等。)
在实际生活中,最常用的连续变量的分布是正态分布(normal distribution),又称高斯分布(Gaussian distribution),它的密度函数为:
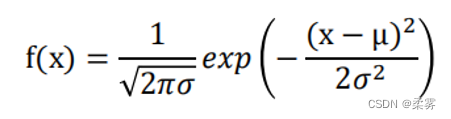
其中μ为均值,𝜎为标准差
一般把正态分布记为N(μ,σ2)。正态分布密度曲线为钟型曲线。改变μ和𝜎,密度曲线会平移和放缩
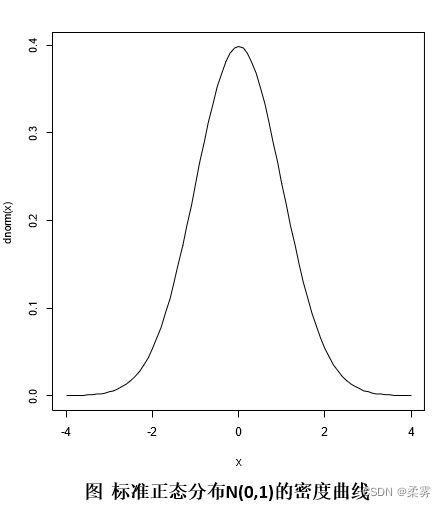
特别的,当μ = 0,𝜎 = 1时,此时的正态分布为标准正态分布N(0,1).
在R中使用下面的命令得到下图的标准正态分布密度曲线:
x=seq(-4,4,0.1)#函数seq用于产生等距数值,这里是从-4到4,步长为0.1
plot(x,dnorm(x),type="l")#type="1"示函数在点与点之间画线而不只是画出点本身来(代表线条)# dnorm还有其他参数,即均值和标准差,常默认为0和1,即默认为标准正态分布
或者使用下面的作图方法,但它需要y值可以通过x的简单函数表达式表示出来:
curve(dnorm(x),from=-4,to=4)
curve 函数常用于绘制函数对应的曲线,确定函数的表达式,以及对应的需要展示的起始坐标和终止坐标,curve函数就会自动化的绘制在该区间内的函数图像
curve函数语法格式如下:curve(expr, from = NULL, to = NULL, n = 101, add = FALSE, type = “l”, xname = “x”, xlab = xname, ylab = NULL, log = NULL, xlim = NULL, …)
主要的参数如下:
expr:函数名称或一个关于变量x的函数表达式;from,to:表示绘图的起止范围;
n:一个整数值,表示x取值的数量;
add:是一个逻辑值,当为TRUE时,表示将绘图添加到已存在的绘图中;
type:与plot函数中type含义相同;xname:用于x轴变量的名称。
xlab,ylab:x轴和y轴的标签名称。
curve(sin, -2*pi, 2*pi)
R软件中的密度函数以d(density)开头。类似地,R软件中的累积分布函数,分位数和随机数分别以p(probability)、q( quantile)和r( random)开头.

其中x和q是由数值型变量构成的向量,p是由概率构成的向量,n是随机产生的个数;
mean是要计算正态分布的均值,缺省值为0,sd是计算正态分布的标准差,缺省值为1
其中dnorm返回值是正态分布的概率密度函数;其中pnorm返回的是正态分布的分布函数;其中qnorm返回的是给定概率p后的下分位点;其中rnorm返回的是由n个正态分布随机数构成的向量。
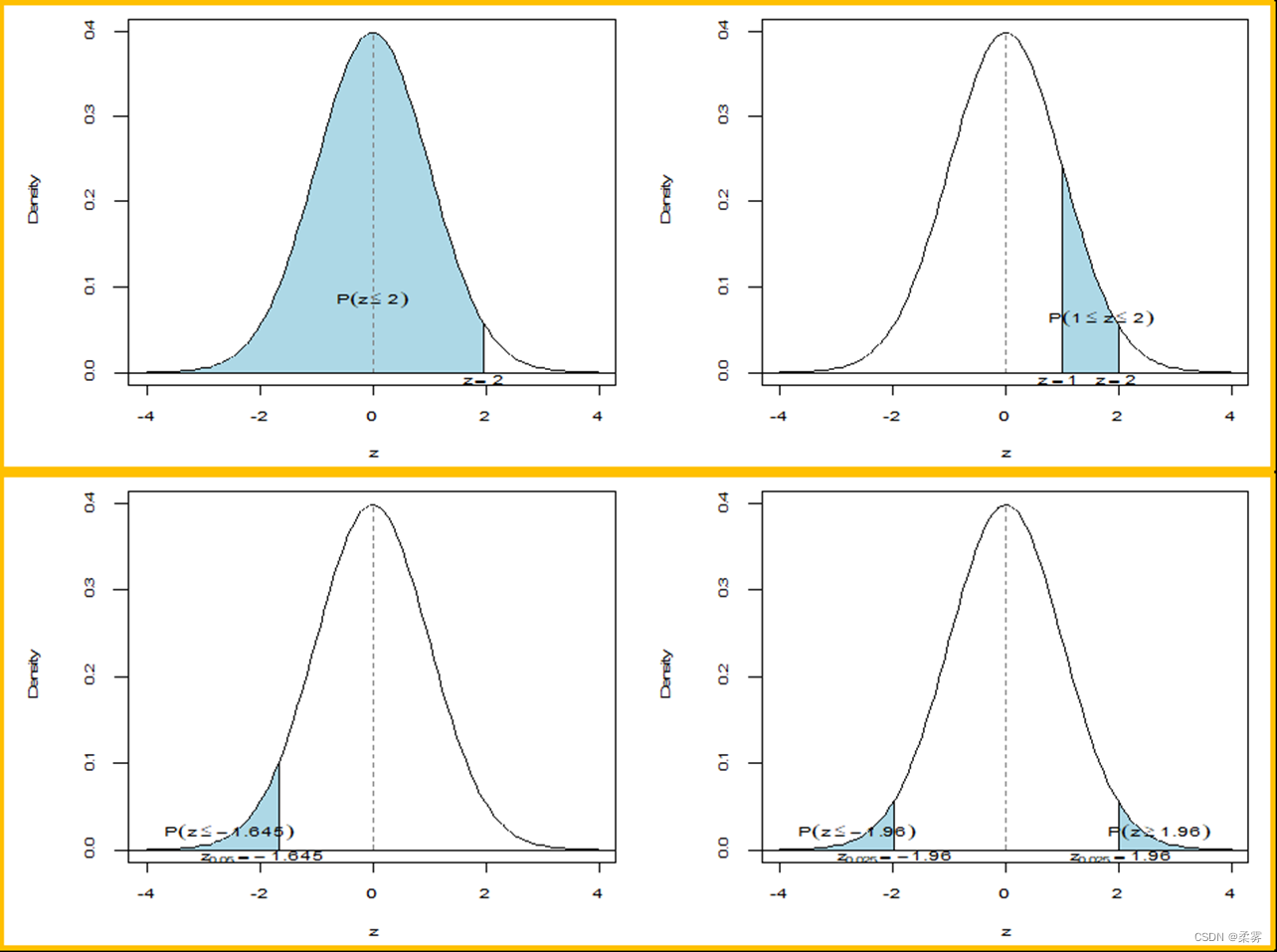
下图是标准正态分布N(0,1)的概率分布曲线,在图中还标注了随机变量X的值落在[-1,1]、[-2,2]和[3,3]区间的概率大小,X的值处于[-3,3]区间的概率达到了99.7%,接近100%!这个特性叫作“3𝜎法则”,它可以拓展到所有的正态分布,即服从正态分布N(μ,σ2)的随机变量的值几乎一定会落在[μ-3𝜎,μ+3𝜎 ]这个区间内。
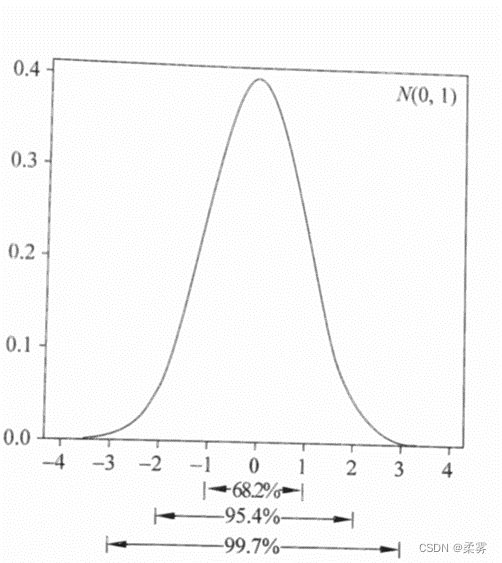
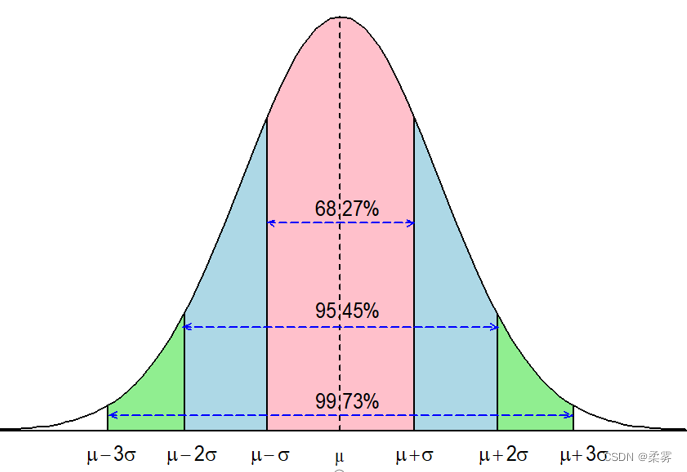
经验法则总结了正态分布在一些常用的区间上的概率:
图显示,正态随机变量落入其均值左右各1个标准差范围内的概率是68.27%
落入其均值左右各2个标准差范围内的概率是95.45%,落入其均值左右各3个标准
差范围内的概率是99.73%。
其它统计分布–χ2分布、t分布、F分布
有些随机变量是统计学家为分析的需要而构造出来的。比如,样本方差除以总体方差得到服从 分布的随机变量,样本均值标准化后形成一个服从t分布的随机变量,两个样本方差比形成一个服从F分布的随机变量。
χ2分布,F分布,t分布,这些分布都是由正态分布推导而来的,它们在推断统计中具有独特的地位和用途。
χ2分布
由正态变量导出的分布之一是χ2 分布(chi square distribution,卡方分布)
如果 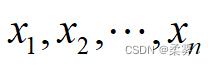
是独立的标准正态分布变量,则 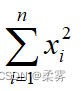
服从自由度为n的χ2分布,记为χ2(n)。 这里的自由度n指包含的独立变量个数
更一般,若干个独立的χ2分布变量的和也服从χ2分布,其自由度等于那些χ2分布变量自由度之和
由于χ2分布变量为正态变量的平方和,所以它不会取负值
χ2分布也是一族分布,由该族成员的自由度来区分。
示例如下:
绘制不同自由度分布曲线的R代码如下:
x=c(seq(0,20,length=1000)); y2=dchisq(x,2);y3=dchisq(x,3)
y9=dchisq(x,9)#dchisq(n,df)代表自由度为df的χ2分布
plot(x,y2,type="l",xlab="",ylab="",lty=1,main=expression(paste(chi^2," 分布")))
lines(x, y3, type="l", xlab="", ylab="",lty=2)
lines(x,y9,type="l",xlab="",ylab="",lty=3)
labels = c("df=2","df=3","df=9")
atx = c(2,4,10) ; aty = c(0.45,0.2,0.12)
text(atx, aty, labels = labels)
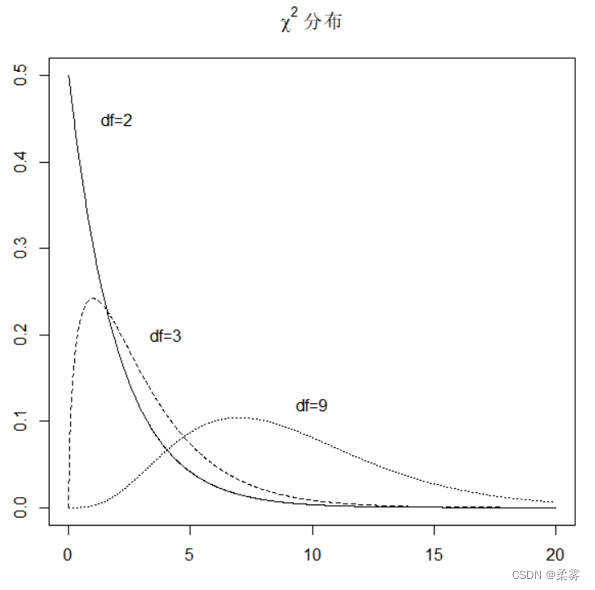
为三个不同自由度的χ2分布密度曲线图可以看出:随着自由度的增大,图像趋于对称。
或者使用下面的代码来绘制不同自由度分布曲线:
不同自由度的c2分布
par(mfrow=c(2,3), mai=c(.6,.6,.2,.1))
n=5000
df=c(2,5,10,15,20,30)
for(i in 1:6){
x<-rchisq(n,df[i])
hist(x,xlim=c(0,60),prob=T,col='lightblue',xlab=expression(chi^2),ylab="Density",
main=paste("df =",df[i]))
curve(dchisq(x,df[i]),lwd=1.5,col=2,add=T)
}
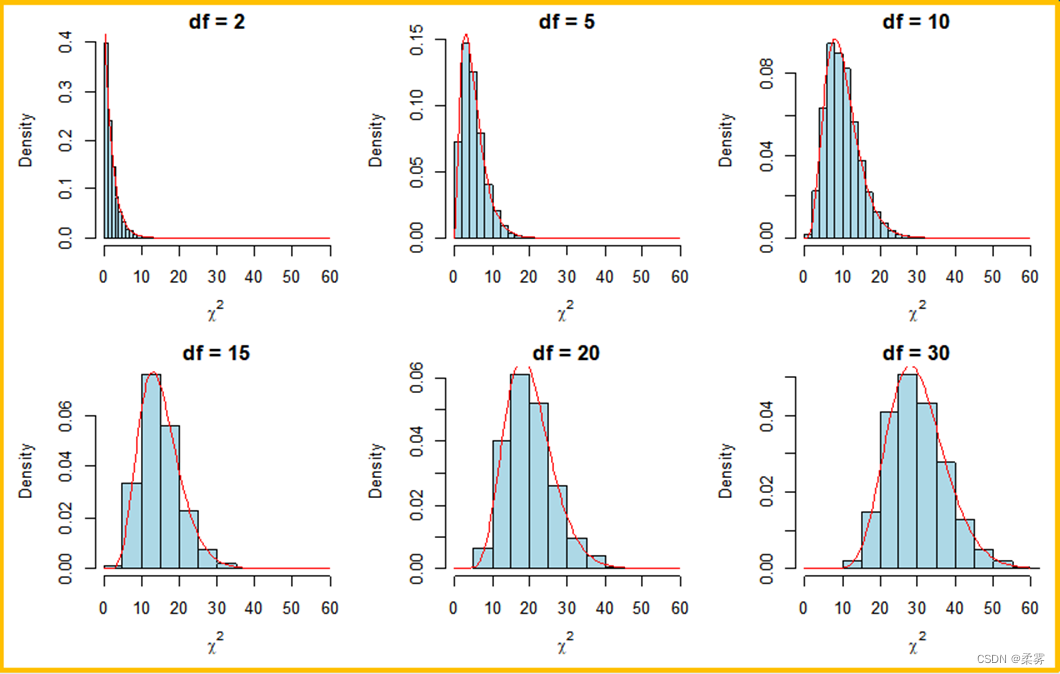
在总体方差的估计和非参数检验中会用到χ2 分布。χ2分布的概率即为曲线下面积。利用R函数可以计算给定χ2值和自由度df时χ2分布的累积概率和给定累积概率与自由度时相应的χ2值。
pchisq(x,df)为分布函数,计算X≤某一值的累积概率;
qchisq(p,df)为分位数函数,计算给定累积概率p、自由度df时的分位数。
计算:
(1)自由度为15,χ2 值小于10的概率;
pchisq(10,df=15)
(2)自由度为25,χ2值大于15的概率;
1-pchisq(20,df=25)
(3)自由度为10,χ2分布右尾概率为0.05时的反函数值 #计算 χ2分布
qchisq(0.95,df=10)
t分布
在统计推断中往往希望利用样本均值减去总体均值再除以均值的总体标准差来得到标准正态变量
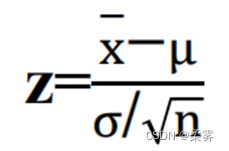
但是在实际应用中,σ往往未知,常常用样本标准差s来代替未知的总体标准差σ,这时得到的变量
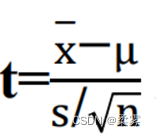
就不再服从标准正态分布。
它的密度曲线看上去有些像标准正态分布,但是中间瘦一些,而且尾巴厚一些,这种分布称为t分布(t-distribution,或学生t分布,Student’s t)。
假定有一个正态分布N(μ,σ2)的样本,样本标准差为s,样本均值为x,样本量为n,那么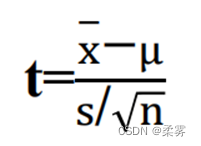
就服从自由度为(n-1)的t分布,记为t(n-1)
不同样本量通过标准化所产生的t分布也不同, 这样就形成了一族分布
t分布族中的成员是以自由度来区分的。有k个自由度的t分布用t(k)表示,也有用t(k)或tk表示的。
t分布还可以根据χ2分布以及正态分布导出:
如果X是N(0,1)变量,Y是χ2(n)变量,且X和Y独立
那么t=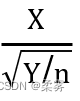 为有n个自由度的t分布,记为t~t(n)。
为有n个自由度的t分布,记为t~t(n)。
随着自由度增大,分布逐渐趋于正态分布。
绘制对应于不同自由度的t分布于标准正态分布曲线的R代码(dt(df) 1、10)。
x = seq(-5,5,by=.1)#seq()生成范围是-5~5,步长为0.1的数据
par(mfrow=c(1,1))
plot(x,dnorm(x),type='l',xlab="",ylab="")#dnorm(x, mean = 0, sd = 1, log = FALSE) 的返回值是正态分布概率密度函数值
lines(x,dt(x,df=1),lty=2)#dt()函数用来做t分布,df是自由度
lines(x,dt(x,df=10),lty=3)
labels = c("N(0,1)","t(1)","t(10)")
atx = c(1.5, -0.6,-1.2) ; aty = c(0.35,0.16,0.3)
text(atx, aty, labels = labels)
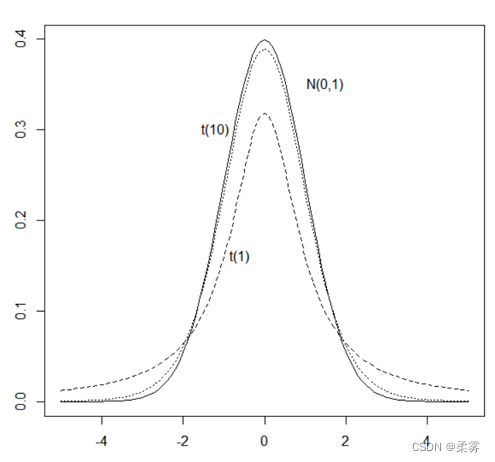
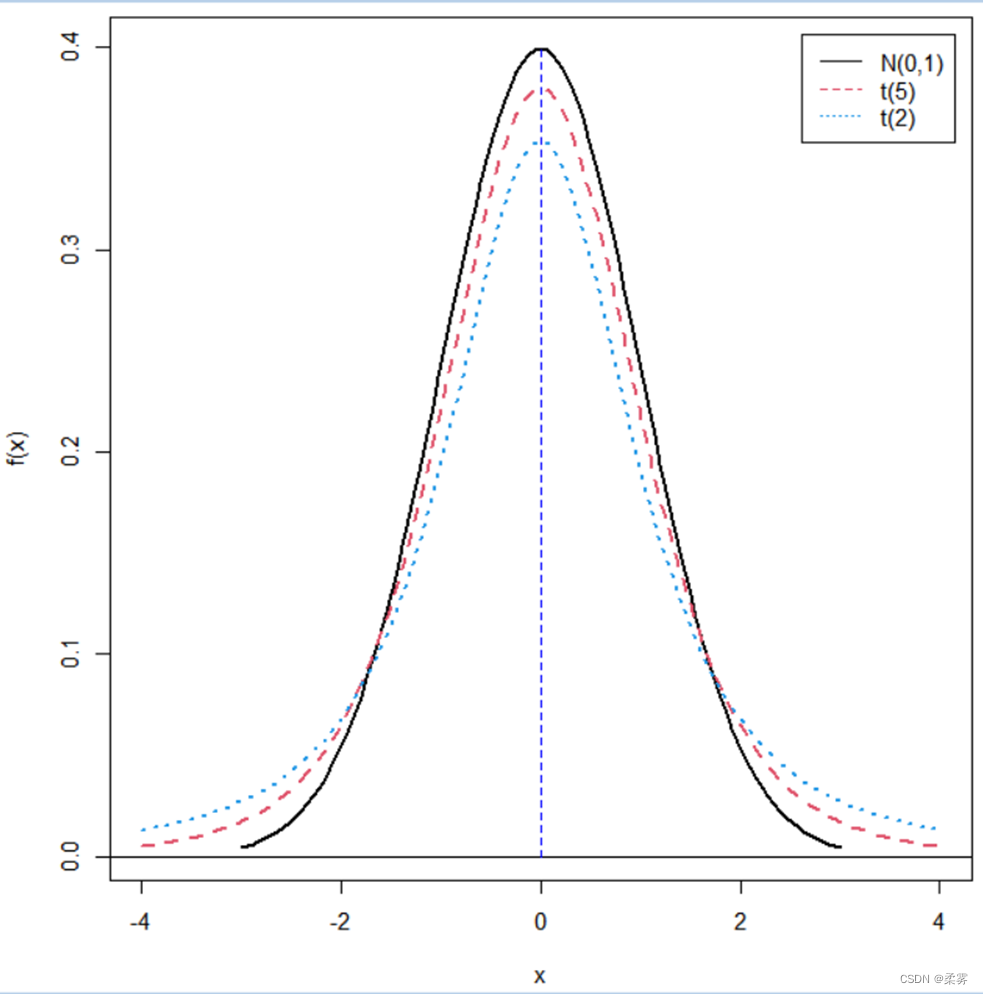
该图展示了标准正态分布 N(0,1)和自由度分别为1和10的t分布的密度函数曲线
可以看出:
t分布两边尾巴比较长。但是当自由度增加时,它的分布就逐渐接近标准正态分布
在t分布中,如果自由度趋于无穷,那么t分布就是标准正态分布。因此,在大样本情况下,可以用标准正态分布来近似t分布
用另外一种方法绘制对应于不同自由度的t分布于标准正态分布曲线的R代码(提示:使用curve()函数,绘制标准正态分布曲线以及自由度为2为5的t分布曲线)
par(mai=c(0.75,0.75,0.1,0.1),cex=0.9)
curve(dnorm(x,0,1),from=-3,to=3,xlim=c(-4,4),ylab="f(x)",lty=1,lwd=2,col=1)
abline(h=0)
segments(0,0,0,0.4,col="blue",lty=2,lwd=1.5)
curve(dt(x,5),from=-4,to=4,add=TRUE,lty=2,col=2,lwd=2)
curve(dt(x,2),from=-4,to=4,add=TRUE,lty=3,col=4,lwd=2)
legend(x="topright",legend=c("N(0,1)","t(5)","t(2)"),lty=1:3,inset=0.02,col=c(1,2,4))
当正态分布标准差未知时,在小样本条件下对总体均值的估计和检验要用到t分布。t分布的概率即为曲线下面积。
计算:(1)自由度为10,t值小于-2的概率;(2)自由度为15,t值大于3的概率;(3)自由度为25,t分布右尾概率为0.025时的t值
计算t分布的概率和分位数
pt(-2,df=10)
1-pt(3,df=15)
qt(0.975,df=25)

F分布
两个独立 分布变量在除以它们各自自由度之后 的比为F分布变量。如果X是 变量,Y是 变量,且X和Y独立,则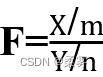 服从自由度为(m, n)的F分布,记为F(m,n)。
服从自由度为(m, n)的F分布,记为F(m,n)。
性质:如果F变量服从F(m,n)分布,那么1/F服从。
F(n,m)分布,因为1/F=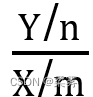 。
。
绘制对应于不同自由度的F分布曲线的R代码:(df(),配以两个自由度)
2,30 10,30 20,30
x=c(seq(0,5,length=1000));#seq()生成1000个数,数的范围是0~5
y2=df(x,2,30);y3=df(x,10,30);y4=df(x,20,30);#df()做F分布,配以两个自由度
plot(x,y2,type="l",xlab="",ylab="",lty=1,main="")#lty线条类型
lines(x,y3,type="l",xlab="",ylab="",lty=2)#在原有图形上再画
lines(x, y4, type="l", xlab="", ylab="",lty=3)
labels = c("F(2,30)", "F(10,30)", "F(20,30)")
atx = c(0.2, 1,1.6) ; aty = c(0.8,0.7,0.95)
text(atx, aty, labels = labels)
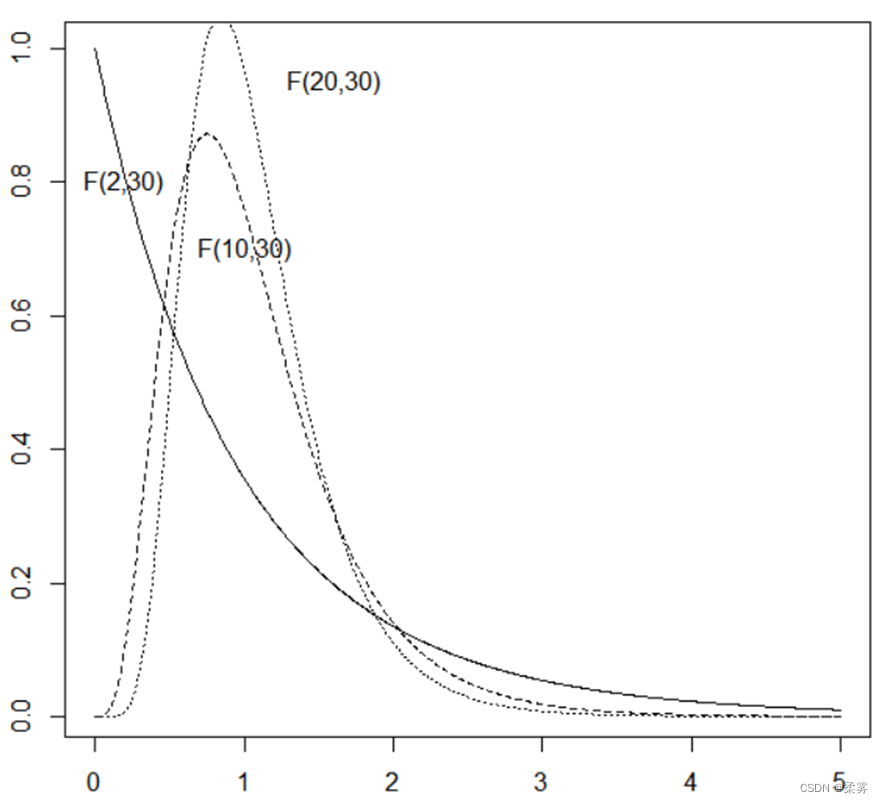
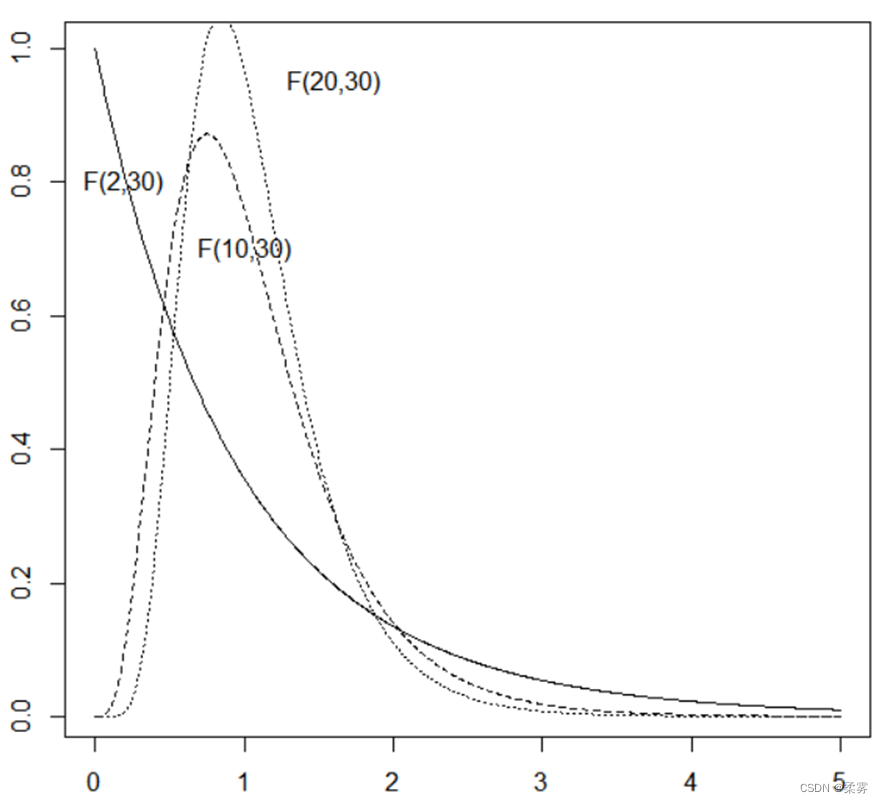
为不同自由度组合情况下的F分布密度曲线图
可以看出:
当第二个自由度相同时,第一个自由度越小,
峰越靠近左边
F分布不以正态分布为其极限,总为正偏分布。
用另外一种方法绘制对应于不同自由度的F分布曲线的R代码
(提示:使用curve()函数,绘制自由度分别为(10,20)、(5,10)、(3,5)的F分布曲线)
不同自由度的F分布
par(mai=c(0.75,0.75,0.1,0.1),cex=0.9)
curve(df(x,10,20),from=0,to=5,xlim=c(0,5),xlab="F",ylab="f(x)",lty=1,lwd=3,col=1)
curve(df(x,5,10),from=0,to=5,add=TRUE,lty=2,lwd=3,col=2)
curve(df(x,3,5),from=0,to=5,add=TRUE,lty=3,lwd=3,col=4)
abline(h=0);abline(v=0)
legend(x="topright",legend=c("F(10,20)","F(5,10)","F(3,5)"),lty=1:3,inset=0.02,col=c(1,2,4))
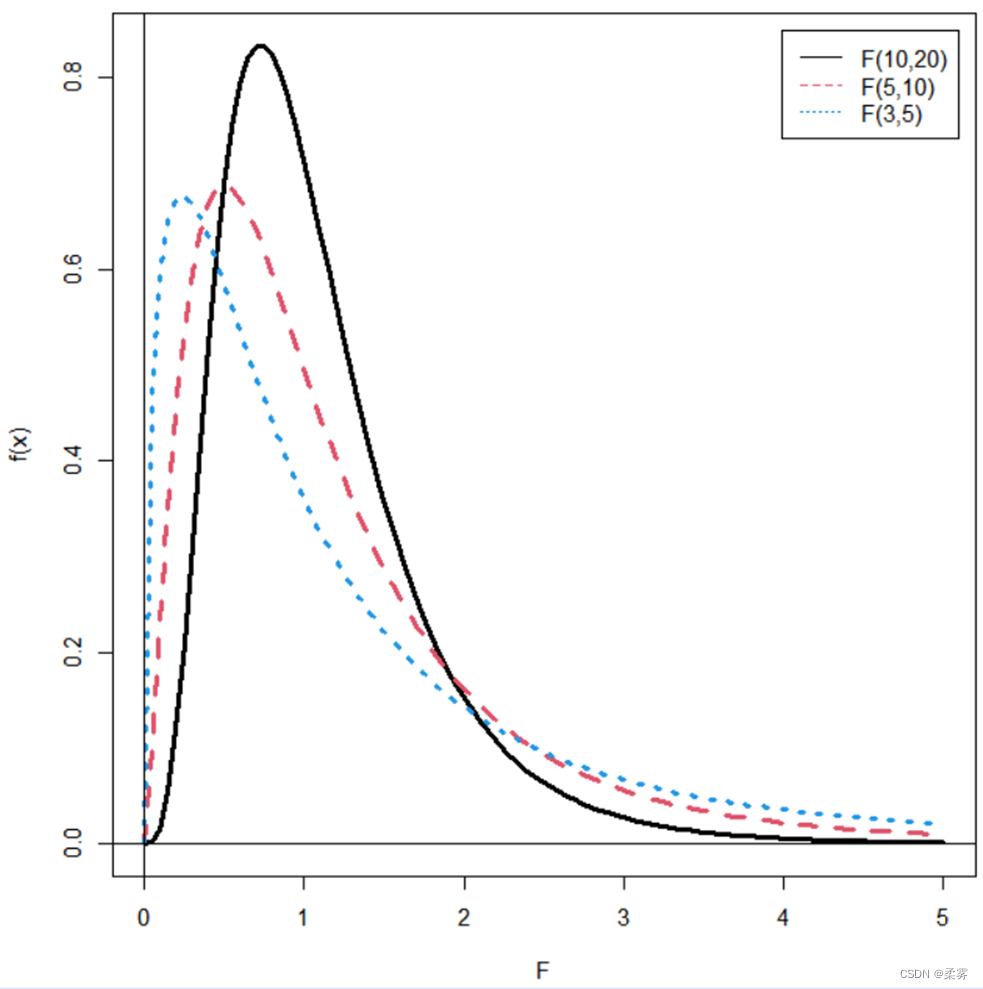
F分布通常用于比较不同总体的方差是否有显著差异。F分布的概率即为曲线下面积。利用R函数,可以计算给定F值与自由度df1和df2时F分布的累积概率以及给定累积概率与自由度df1,df2时的相应F值。
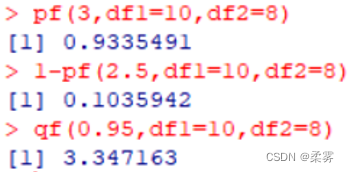
计算:(1)分子自由度为10,分母自由度为8,F 值小于3的概率;(2)分子自由度为10,分母自由度为8,F 值大于2.5的概率;(3)分子自由度为10,分母自由度为8,F 分布累积概率为0.95时的F 值
计算F分布的概率和分位数
pf(3,df1=10,df2=8)
1-pf(2.5,df1=10,df2=8)
qf(0.95,df1=10,df2=8)
练习
1、已知一批产品的不合格品率为6%、从中有放回地抽取5个。求5个产品中:(提示:仿照42页)
(1)没有不合格品的概率;
dbinom(0,5,0.06)
(2)恰好有1个不合格品的概率:
dbinom(1,5,0.06)
(3)有3个及3个不合格品的概率。
pbinom(3,5,0.06)

2、计算下列概率
(1)X~N(50,102),求P(X≤40)和P(30≤X≤40)
pnorm(40,mean=50,sd=10) #P(X≤40)
pnorm(40,mean=50,sd=10)-pnorm(30,mean=50,sd=10) #P(30≤X≤40)
(2)Z~N(0,1),求P(Z≤2.5)和P(-1.5≤Z≤2)
pnorm(2.5,mean=0,sd=1) #P(Z≤2.5)
pnorm(2,mean=0,sd=1)-pnorm(-1.5,mean=0,sd=1) #P(-1.5≤Z≤2)
(3)标准正态分布累积概率为0.025时的反函数值z。
qnorm(0.025,mean=0,sd=1)

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【电商数据采集】电商数据分析+电商API接口接入
- 卷烟器市场调研:到2028年的复合年增长率将达到 1.9%
- 全国计算机等级考试| 二级Python | 真题及解析(12)
- 07 HXCommon
- 为何PostgreSQL性能优于MySQL?
- Kali Linux安装Xrdp远程桌面工具结合内网穿透实现远程访问Kali桌面
- ssm“北斗系统+物联网”的智慧冷链物流管理系统(开题+源码)
- 模型稳定性评估 简介
- 计算机专业大学生就业指南网设计与实现-附源码061355s
- 设备注册的多种方式