深度学习—常见的卷积操作和卷积神经网络
各种常见的卷积操作
0、三种模式及输出矩阵尺寸计算
W输入矩阵宽,w是卷积核的大小,p是padding的数值,stride是滑动步幅
Full 补k-1圈 :w0?=( | W | - w + 2p )/?stride + 1
Same?补若干圈:w0?= ceil( | W | / stride)padding
Valid?不补:w0?= ceil( | W | - w + 1? / stride)no padding
1、1×1卷积
一般发生在多个通道中(一个通道没有意义),相当于降维操作
作用:1)降维,例如从2626192,到262616,1×1卷积是跨通道线性组合,是通道间的信息交互;
2)增加非线性激励,只改变通道数,在输入数据分辨率/尺寸不损失的前提下,大幅增加神经网络的非线性特性。
3)减少权值个数
2、扩张卷积/膨胀卷积/空洞卷积(Dilated Convolution, Atrous Convolution)
在标准卷积中注入空洞,空洞卷积常被用于低成本地增加输出单元上的感受野,同时还不需要增加卷积的大小
空洞卷积的实际卷积核的大小/宽:k = w + ( w - 1 )*( r - 1 )? ? ?w为原始卷积和的宽,r为扩张率
优点:扩大了神经网络的感受野,捕获更多上下文信息,尤其对大尺寸的物体分割有用
缺点:局部信息丢失
3、反卷积/逆卷积/转置卷积(Deconcolution/Transposed Convolution)
是一种上采样方法,反卷积是中间填0再卷积;普通的上采样如果用双线性插值,中间填相邻元素的差值
卷积核实际大小 :K = W + ( W - 1 )* ( stride - 1 )
4、反池化/上池化(Unpooling)与上采样(Unsampling)
池化时,保存了最大值再输入数据中的位置信息矩阵;反池化时,将对应位置上的值置为输出矩阵的对应值,其他元素置为0。
无卷积,操作简单。

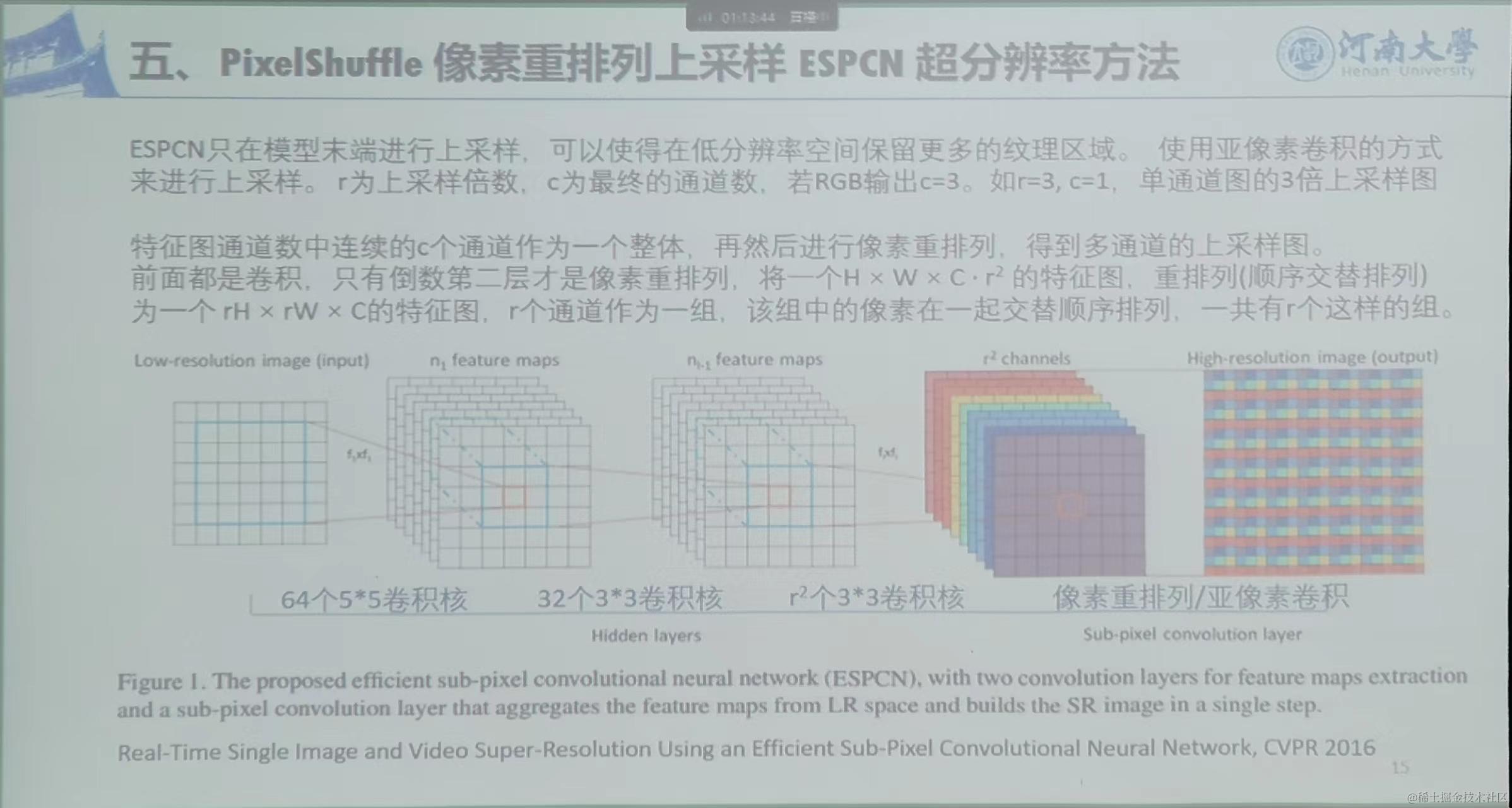
5、PixelShuffle像素重排列上采样 ESPCN超分辨率方法
6、分组卷积(AlexNet)Grouped Convolution

举例:如将所有通道分为两组,则每一组通道分别使用各自对应的D/2个卷积核,最后两组卷积特征堆叠。
作用:1)减少参数量,参数为原来的1/G
2)加快训练速度
3)有时可以正则化的效果
7、深度可分离卷积(Depthwise Separable Convolutions)
逐通道卷积(Depthwise Convolution):是一个卷积核负责一个通道,一个通道只被一个卷积核卷积。输出的通道数与输入相同,但是没有利用不同通道在相同空间位置上的特征关系。

逐点卷积:执行1×1卷积,M为输入通道数,进行单点上的特征提取。
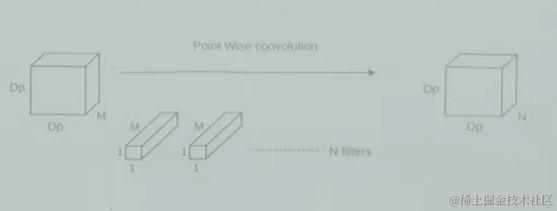
深度可分离卷积 = 逐通道卷积 + 逐点卷积 ,前后两个步骤,其将分组卷积推向了极端,此时:分组数是输入通道数目,即每个输入通道单独卷积。
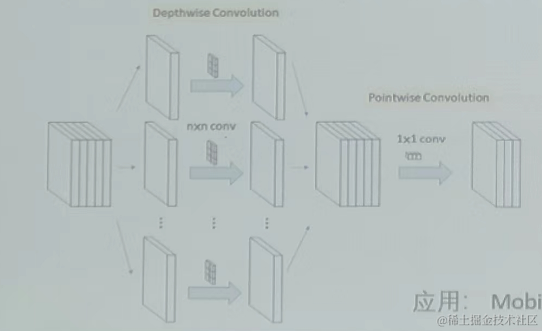
****应用:MobileNet 、移动端轻量化网络、参数少、占用资源少、运算快
卷积神经网络
1、LeNet和AlexNet卷积神经网络
LeNet
网络结构:两个卷积层,两个池化层,两个全连接层,一个输出层。
激活函数:AvgPooling、SIgmoid
两个卷积层都是5×5的窗口,两个全连接层的神经元数量分别为120和84。
创新性:卷积神经网络的开山之作,完成了CNN从0到1的过程。
AlexNet
网络结构:五个卷积层,三个池化层,两个全连接层,一个输出层。
激活函数:MaxPooling、ReLu
第一层卷积11×11窗口,以后5×5,3×3,两个全连接层的神经元数量都为4096。
创新性:两个全连接层之间使用了Dropout技术,随机将一半的隐层节点置为0(当模型参数太多,而训练样本太少时,易产生过拟合)。

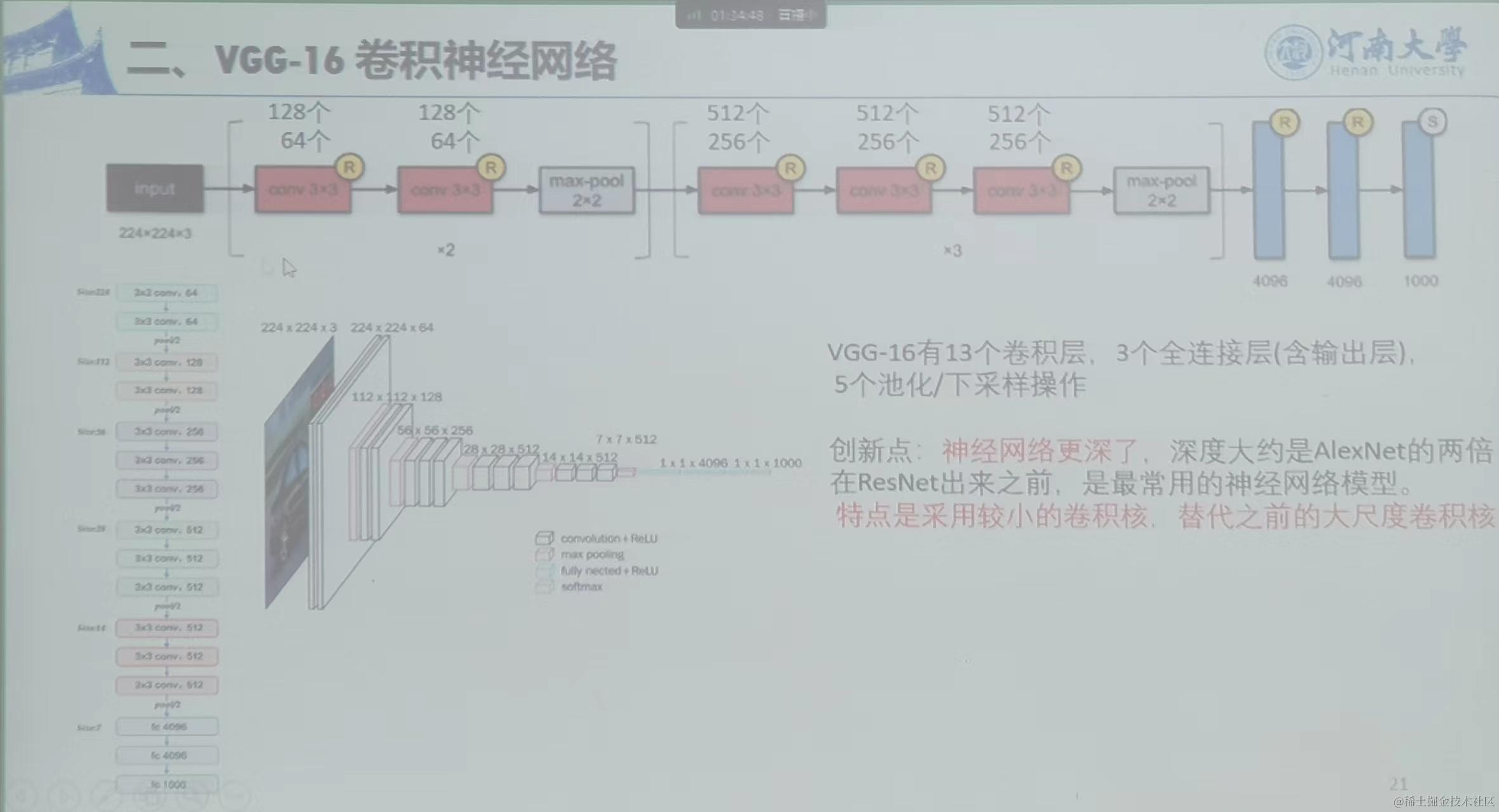
2、VGG-16卷积神经网络
特点:13个卷积层和3个全连接层,5个池化/下采样操作,3*3的卷积核(卷积核尺寸小)代替之前的大尺寸卷积,神经网络深度更深(全连接处神经元多)。
 ? ? ? ?
? ? ? ?
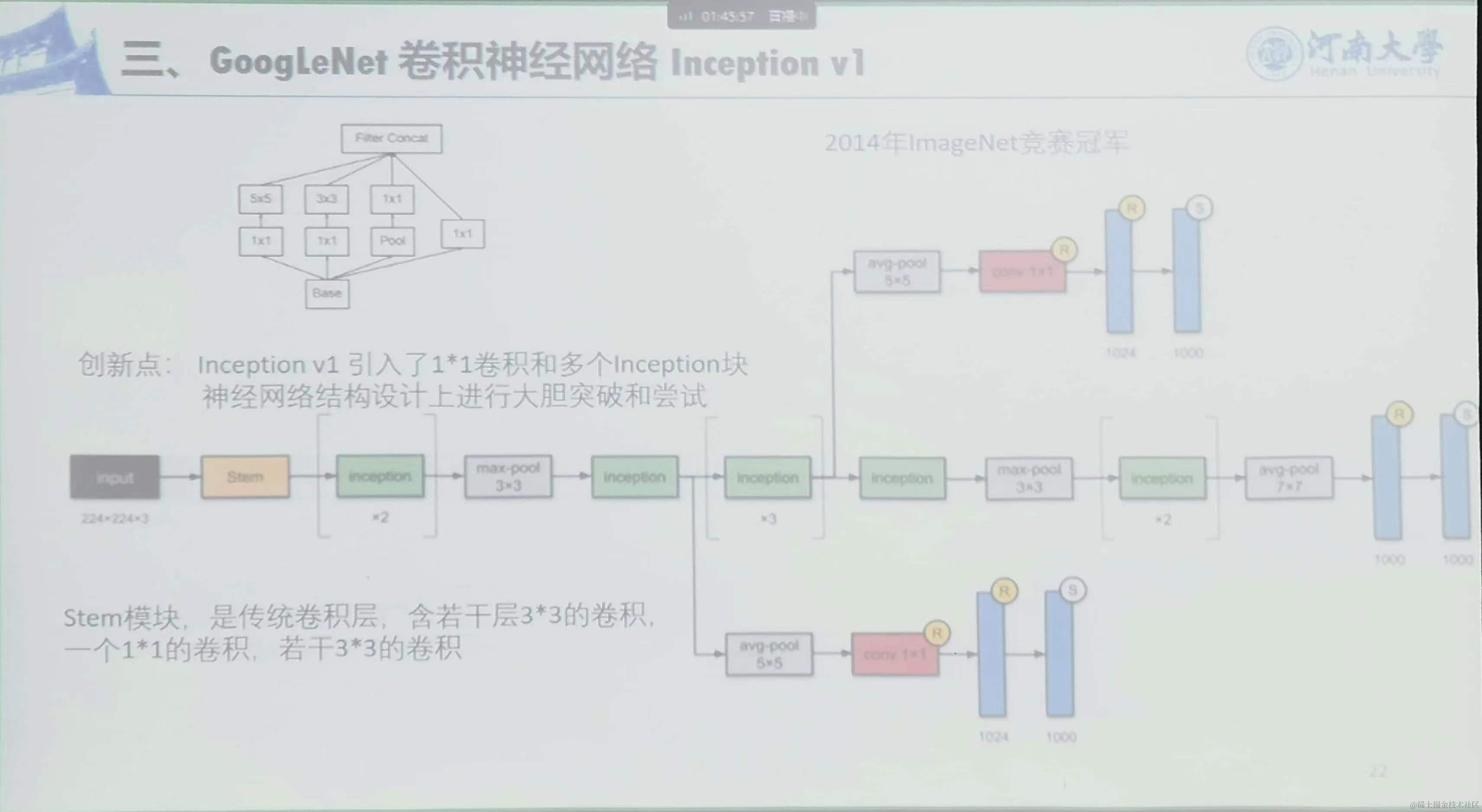
3、GoogleLeNet卷积神经网络 Inception V1
创新点:Inception V1引入了1*1卷积和多个Inception块;神经网络结构设计上进行分支设计
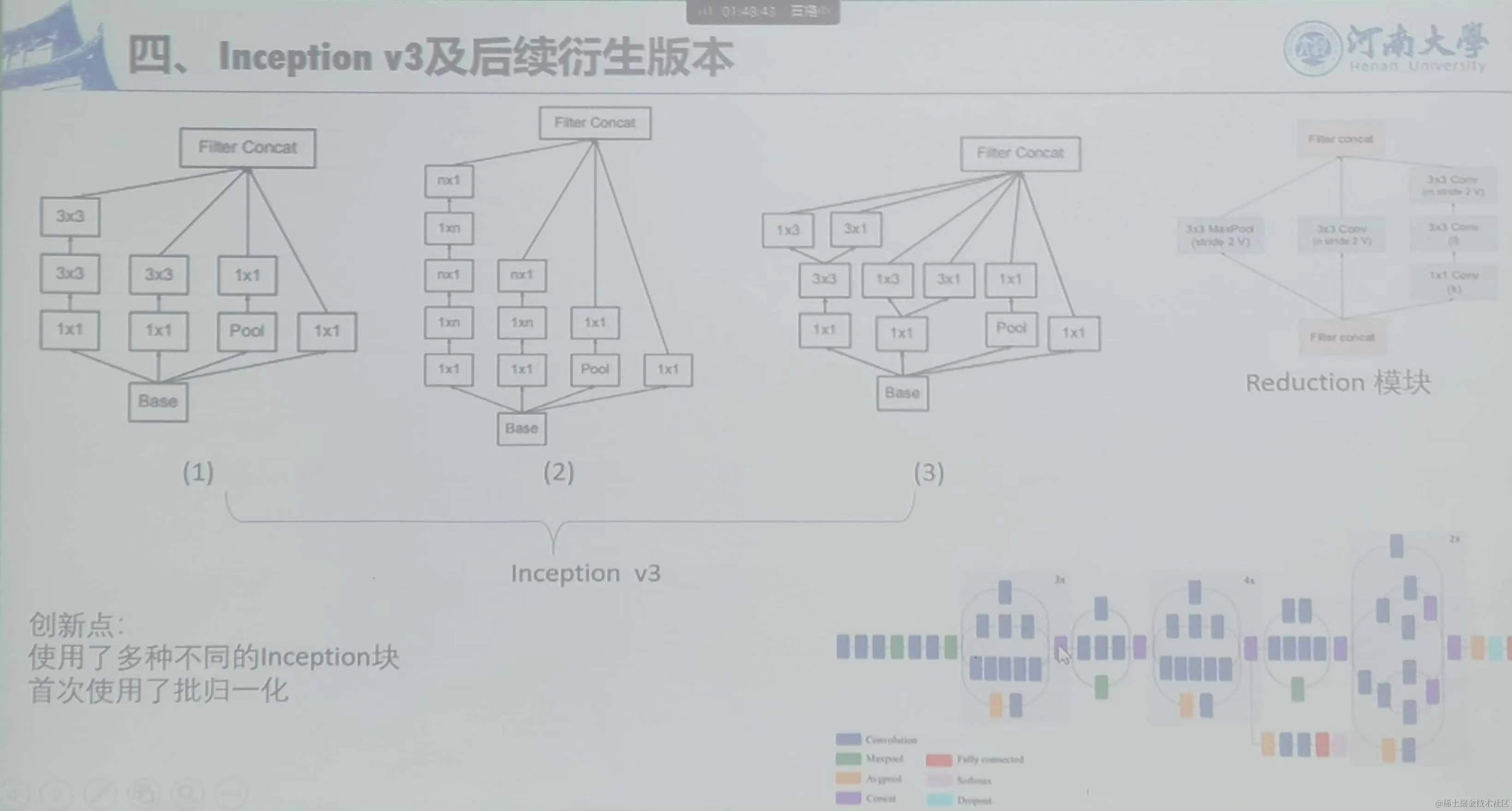
4、Inception V3及后续版本
使用了多种不同的Inception块,首次使用了批归一化。
5、RestNet及后续版本
创新点:使用了残差块–捷径连接,在输入激活函数前,将前层网络的输入与当前层网络层的输出进行结合,数据可以跨层连接。
网络越深,梯度就越容易出问题,捷径连接的方式一定程度上缩短了损失的反向传播路径,减小了梯度风险。

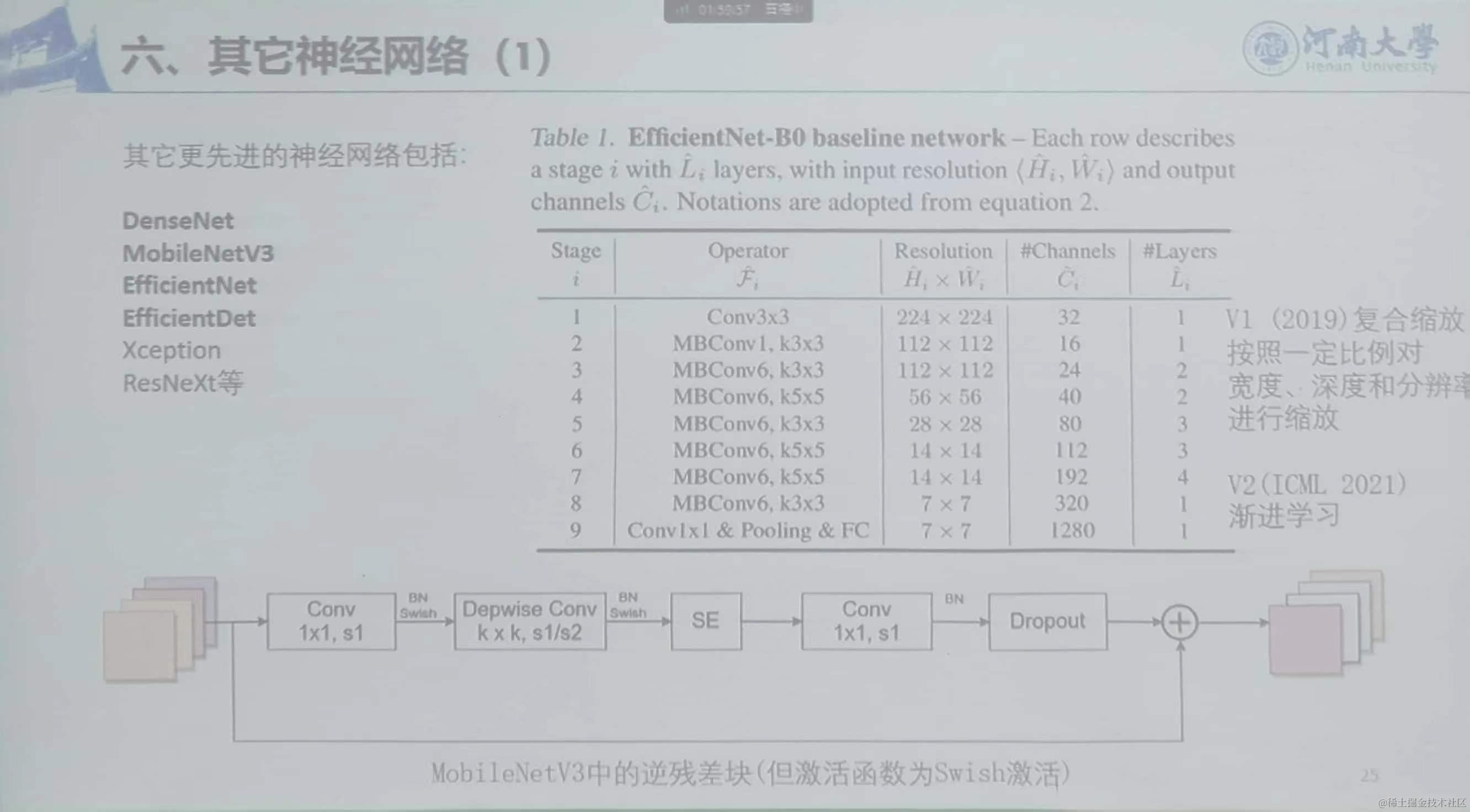
6、其他神经网络
EfficientNet-B0:注意力机制,激活函数是Swish
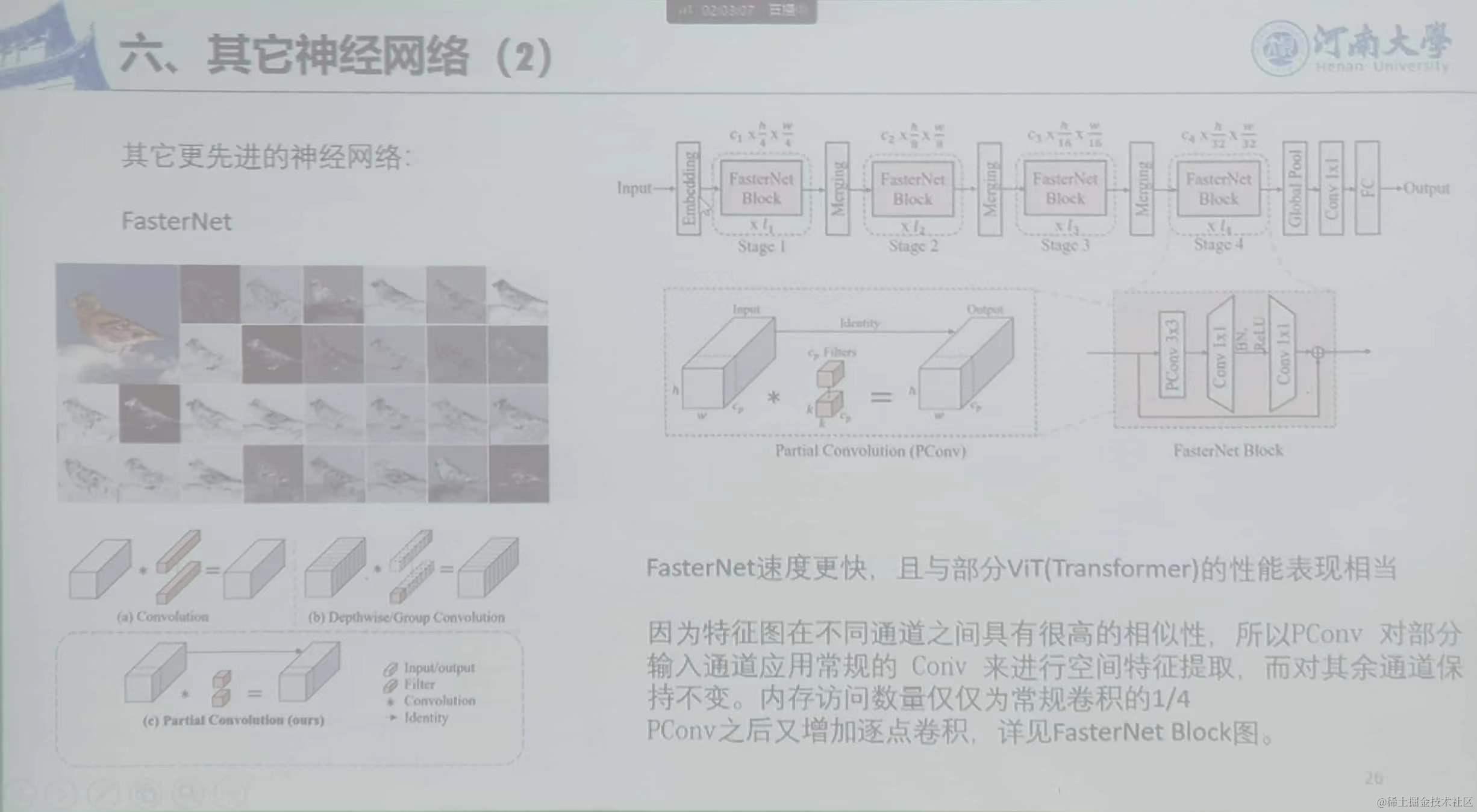
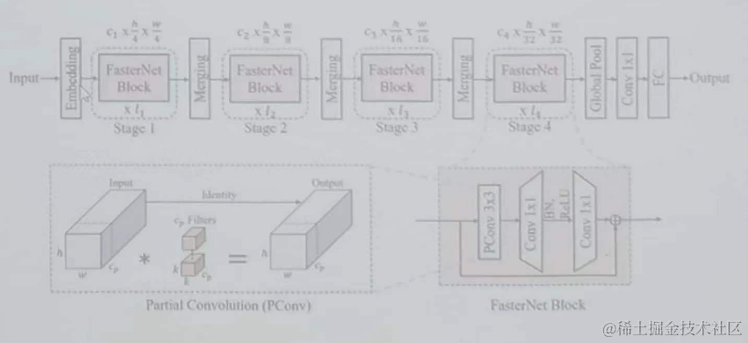
FasterNet:速度更快,因为特征图在不同通道之间具有很高的相似性,所以PConv对部分输入通道应用常规的Conv来进行空间特征提取,而对其余通道保持不变。内存访问数量仅为常规卷积的1/4。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- ceph、gluster、longhorn选型对比
- windows10-tdengine的安装及使用
- NVIDIA Isaac Sim 入门教程(一)
- DAY12--learning English
- 隐藏服务器IP的正确使用方式
- javaSwing+MySQL 房屋租赁系统(附源码)
- oracle 12 查询数据库锁
- Spring Redis Client使用Hessian序列化HINCRBY命令的Bug
- 每日算法打卡:四平方和 day 9
- 新手怎么做短视频小说推文?