基于LSTM的负荷预测,基于BILSTM的负荷预测,基于GRU的负荷预测,基于BIGRU的负荷预测,基于BP神经网络的负荷预测
目录
背影
摘要
代码和数据下载:基于LSTM的负荷预测,基于BILSTM的负荷预测,基于GRU的负荷预测,基于BIGRU的负荷预测,基于BP神经网络的负荷预测资源-CSDN文库 https://download.csdn.net/download/abc991835105/88768064
LSTM的基本定义
LSTM实现的步骤
GRU原理
bilstm
bigru
bp
结果分析
展望
参考论文
背影
路径坐标有一定的时间或者空间上的连续性,本文用LSTM进行预测
摘要
LSTM原理,BILSTM原理,GRU原理,BIGRU原理,BP神经网络原理,基于LSTM的负荷预测,基于BILSTM的负荷预测,基于GRU的负荷预测,基于BIGRU的负荷预测,基于BP神经网络的负荷预测
LSTM的基本定义
LSTM是一种含有LSTM区块(blocks)或其他的一种类神经网络,文献或其他资料中LSTM区块可能被描述成智能网络单元,因为它可以记忆不定时间长度的数值,区块中有一个gate能够决定input是否重要到能被记住及能不能被输出output。
图1底下是四个S函数单元,最左边函数依情况可能成为区块的input,右边三个会经过gate决定input是否能传入区块,左边第二个为input gate,如果这里产出近似于零,将把这里的值挡住,不会进到下一层。左边第三个是forget gate,当这产生值近似于零,将把区块里记住的值忘掉。第四个也就是最右边的input为output gate,他可以决定在区块记忆中的input是否能输出 。
图1 LSTM模型
图1 LSTM模型
LSTM有很多个版本,其中一个重要的版本是GRU(Gated Recurrent Unit),根据谷歌的测试表明,LSTM中最重要的是Forget gate,其次是Input gate,最次是Output gate
训练方法
为了最小化训练误差,梯度下降法(Gradient descent)如:应用时序性倒传递算法,可用来依据错误修改每次的权重。梯度下降法在递回神经网络(RNN)中主要的问题初次在1991年发现,就是误差梯度随着事件间的时间长度成指数般的消失。当设置了LSTM 区块时,误差也随着倒回计算,从output影响回input阶段的每一个gate,直到这个数值被过滤掉。因此正常的倒传递类神经是一个有效训练LSTM区块记住长时间数值的方法。
lstm的步骤
1 , LSTM的第一步是确定我们将从单元状态中丢弃哪些信息,这个策略有一个被称为遗忘门的sigmoid层决定。输入ht-1和xt遗忘门对应单元状态ct-1中每个数输出一个0到1之间的数字。1代表“完全保持”,0表示“完全遗忘”。
让那个我们回到我们的语言模型例子中尝试基于所有之前的词预测下一个词是什么。在这个问题中,单元状态中可能包括当前主题的性别,因此可以预测正确代词。当我们看到一个新的主题的性别时,我们想要忘记旧主题的性别。
=(W*[h-1,x]+b)
下一步将决定我们在单元状态中保存那些新信息。包括两个部分;第一”输入门层”的sigmoid层决定我们将更新那些值,第二,tanh层创建可以添加到状态的新候选值ct-1的向量。在下一步中,我们将结合这两个来创建状态更新。
在我们语言模型的例子中,我们想要将新主题的性别添加到单元格状态,以替换我们忘记的旧主题
=(W*[h-1,x]+b)
=tanh(W*[h-1,x]+b)
现在是时候将旧的单元状态ct-1更新为新的单元状态ct,之前的步骤已经决定要做什么,我们只需要实际做到这一点。我们将旧状态乘以ft,忘记我们之前决定忘记的事情,然后我们添加*Ct .这是新的候选值,根据我们的决定更新每个州的值来缩放。
在语言模型的情况下,我们实际上放弃了关于旧主题的性别的信息并添加新信息,正如我们在前面的步骤中所做的那样。
C=C-1+(1-)
最后,我们需要决定我们要输出的内容,此输出将基于我们的单元状态,但将是过滤版本,首先,我们运行一个sigmoid层,它决定我们要输出的单元状态的哪些部分,然后我们将单元状态设置为tanh(将值推到介于-1和1之间)并将其乘以sigmoid门的输出,以便我们只输出我们决定的部分。
对于语言模型示例,由于它只是看到一个主题,他可能想要输出与动物相关的信息,以防接下来会发生什么,例如,他输出主语是单数还是复数,一边我们知道动词应该与什么形式供轭。
O=(W[h-1,x]+b)
h=O*tanh?
GRU
由于LSTM中3个门控对提升其学习能力的贡献不同,因此略去贡献小的门控和其对应的权重,可以简化神经网络结构并提升其学习效率 [1]。GRU即是根据以上观念提出的算法,其对应的循环单元仅包含2个门控:更新门和复位门,其中复位门的功能与LSTM单元的输入门相近,更新门则同时实现了遗忘门和输出门的功能 [1] [27]。GRU的更新方式如下 [27]:
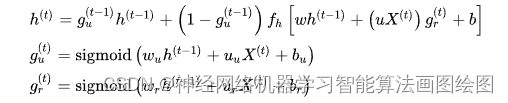 式中符号含义参考LSTM,脚标 表示更新门和复位门。对比LSTM与GRU的更新规则可以发现,GRU的参数总量更小,且参数更新顺序与LSTM不同,GRU先更新状态再更新门控,因此当前时间步的状态使用前一个时间步的门控参数,LSTM先更新门控,并使用当前时间步的门控参数更新状态。GRU的2个门控不形成自循环,而是直接在系统状态间递归,因此其更新方程也不包含内部状态 。
式中符号含义参考LSTM,脚标 表示更新门和复位门。对比LSTM与GRU的更新规则可以发现,GRU的参数总量更小,且参数更新顺序与LSTM不同,GRU先更新状态再更新门控,因此当前时间步的状态使用前一个时间步的门控参数,LSTM先更新门控,并使用当前时间步的门控参数更新状态。GRU的2个门控不形成自循环,而是直接在系统状态间递归,因此其更新方程也不包含内部状态 。
LSTM和GRU有很多变体,包括在循环单元间共享更新门和复位门参数,以及对整个链式连接使用全局门控,但研究表明这些改进版本相比于标准算法未体现出明显优势,其可能原因是门控算法的表现主要取决于遗忘门,而上述变体和标准算法使用了的遗忘门机制相近 [62]。
BILSTM
 Bi-LSTM 的模型设计理念是使 t 时刻所获得特征数据同时拥有过去和将来之间的信息,实验证明,这种神经网络结构模型对文本特征提取效率和性能要优于单个 LSTM 结构模型。值得一提的是,Bi-LSTM 中的 2 个 LSTM 神经网络参数是相互独立的,它们只共享 word-embedding词向量列表
Bi-LSTM 的模型设计理念是使 t 时刻所获得特征数据同时拥有过去和将来之间的信息,实验证明,这种神经网络结构模型对文本特征提取效率和性能要优于单个 LSTM 结构模型。值得一提的是,Bi-LSTM 中的 2 个 LSTM 神经网络参数是相互独立的,它们只共享 word-embedding词向量列表
BIGRU
bigru神经网络是类似于bilstm神经网络,是有2 个 LSTM 神经网络参数是相互独立的,它们只共享 word-embedding词向量列表,来完成训练的
BP神经网络参数设置及各种函数选择
参数设置
1,最大迭代次数net.trainParam.epochs,一般先设置大,然后看训练收敛情况,如果提前收敛,最大迭代次数就改小,以到达训练目标为目的设置。
2,学习率net.trainParam.lr,一般设置0.01–0.5,数据越多,数据噪声越大,数据越难拟合,数值一般需要越小,设置太大,容易过早停止收敛。
3,学习目标net.trainParam.goal,根据训练测试的情况进行调整,过大容易过拟合,测试效果差,过小达不到想要的效果。
4,最大丢失次数net.trainParam.max_fail,既联系不收敛次数,达到这个次数后BP神经网络停止迭代,终止训练,主要目的是防止过拟合,太小容易过早停止迭代,太大容易过拟合,默认是6,需要依据训练测试情况和学习目标,妥协调整。
5,隐含层数,常见的是三个隐含层以内,再多也没有看到有明显的优势,数据好拟合,一个隐含层就足够,数据难拟合,更多层,收敛效果一般也没有明显改善。
6,隐含层神经元个数,按经验公式设置,试凑法调整。
训练函数
trainr 随机顺序递增更新训练函数
trainrp 带反弹的BP训练函数
trains 顺序递增BP训练函数
trainscg 量化连接梯度BP训练函数
trainbrBayes 规范化BP训练函数
trainc 循环顺序渐增训练函数
traincgb Powell-Beale连接梯度BP训练函数
traincgf Fletcher-Powell连接梯度BP训练函数
traincgp Polak-Ribiere连接梯度BP训练函数
traingda 自适应lrBP的梯度递减训练函数
traingdx 动量及自适应lrBP的梯度递减训练函数
trainlm Levenberg-Marquardt BP训练函数
trainoss 一步正切BP训练函数
传递函数:
logsig S型的对数函数
dlogsig logsig的导函数,有些MATALB版本不可用
tansig S型的正切函数
dtansig tansig的导函数,有些MATALB版本不可用
purelin 纯线性函数
dpurelin purelin的导函数,有些MATALB版本不可用
学习函数
learngdm 梯度下降栋梁学习函数
learngd 基于梯度下降法的学习函数
性能函数
mse 均方误差函数
msereg 均方误差规范化函数
显示函数
plotperf 绘制网络的性能
plotes 绘制一个单独神经元的误差曲面
plotep 绘制权值和阈值在误差曲面的位置
errsurf 计算单个神经元的误差曲面
前向网络创建函数
newffd 创建存在输入延迟的前向网络
newcf 创建级联前向网络
newff 创建前向BP网络
BP神经网络训练窗口详解
训练窗口例样

训练窗口详解
如根上图所示分为四个部分:
1,Neural Network
这里显示的是输入层神经元个数大小,中间层数量以及每层的神经元个数。
2,Algorithms
Data Division:Random。这表示使用随机指数将目标分成三组,分别作为train,validation,test。
Training:levenberg-Marquardt。这表示学习训练函数为trainlm。
Performance:Mean Squared Error。这表示性能用均方误差来表示。
Calculations: MEX。该网络保存为mex格式
3,Progress
Epoch:该网络允许的迭代次数最大为500,实际迭代31次
Time:运行时间。
Performance:该网络的最大误差为1.96,目标误差为0.0001,实际误差为0.00475,可在Plots中的Performance中详细查看
Gradient:该网络的最大梯度为1.83,阈值梯度为1e?7 1e^{-7}1e ?7。
Validation Checks:最大验证失败次数。(解释:比如默认是6,则系统判断这个验证集误差是否在连续6次检验后不下降,如果不下降或者甚至上升,说明training set训练的误差已经不再减小,没有更好的效果了,这时再训练就没必要了,就停止训练,不然可能陷入过拟合。)
4,Plots
Performance:这里可以点进去,看train, validation和test的性能。

Training State:记录Gradient和Validation Checks。

Regression:通过绘制回归线来测量神经网络对应数据的拟合程度。

Plot Interval:训练窗口更新次数,等于10的时候,每迭代10次更新一次
?基于LSTM的负荷预测,基于BILSTM的负荷预测,基于GRU的负荷预测,基于BIGRU的负荷预测,基于BP神经网络的负荷预测
部分代码
clc
clear
close all
load maydata.mat
out=1;
m=3000;
n=randperm(length(num));
input_train =num((1:m),1:3 )‘;%
output_train = num(1:m,3+out)’;%
input_test = num(m+1:end,1:3)‘;%
output_test = num(m+1:end,3+out)’;%
[inputn,inputps]=mapminmax(input_train,-1,1);%训练数据的输入数据的归一化
[outputn,outputps]=mapminmax(output_train,-1,1);%训练数据的输出数据的归一化de
inputn_test=mapminmax(‘apply’,input_test,inputps);
pan=3;
%% Define Network Architecture
% Define the network architecture.
numFeatures = size(num(:,1:pan),2);%输入层维度
numResponses = size(num(:,end),2);%输出维度
% 200 hidden units
numHiddenUnits = 200;%第一层维度
% a fully connected layer of size 50 & a dropout layer with dropout probability 0.5
layers = [ …
sequenceInputLayer(numFeatures)%输入层
gruLayer(numHiddenUnits,‘OutputMode’,‘sequence’)%第一层
fullyConnectedLayer(100)%链接层
dropoutLayer(0.3)%遗忘层
fullyConnectedLayer(numResponses)%链接层
regressionLayer];%回归层
% Specify the training options.
% Train for 60 epochs with mini-batches of size 20 using the solver ‘adam’
maxEpochs = 80;%最大迭代次数
miniBatchSize = 1;%最小批量
% the learning rate == 0.01
% set the gradient threshold to 1
% set ‘Shuffle’ to 'never’every-epoch
options = trainingOptions(‘adam’, … %解算器
‘MaxEpochs’,maxEpochs, … %最大迭代次数
‘MiniBatchSize’,miniBatchSize, … %最小批次
‘InitialLearnRate’,0.001, … %初始学习率
‘GradientThreshold’,inf, … %梯度阈值
‘Shuffle’,‘every-epoch’, … %打乱顺序
‘Plots’,‘training-progress’,… %画图training-progress
‘Verbose’,1); %不输出训练过程
%% Train the Network
net = trainNetwork(inputn,outputn,layers,options);%开始训练
%% Test the Network
y_pred = predict(net,inputn_test,‘MiniBatchSize’,1)‘;%测试仿真输出
y_pred=(mapminmax(‘reverse’,y_pred,outputps))’; %反归一化
R2 = R_2(output_test,y_pred)
[MSE, RMSE, MBE, MAE ] =MSE_RMSE_MBE_MAE(output_test,y_pred)
error1 = y_pred’-output_test;%误差
figure
plot(y_pred,‘r-o’)
hold on
plot(output_test,‘k-*’)
hold on
ylabel(‘y’)
legend(‘gru预测值’,‘实际值’)
set(gca,‘fontsize’,12)
error1=y_pred-output_test;
figure
plot(error1,‘k-*’)
ylabel(‘误差’)
set(gca,‘fontsize’,12)
gruy_pred = y_pred;
gruerror = error1;
grup = [R2 MSE, RMSE, MBE, MAE];
save grudata.mat gruy_pred gruerror grup output_test
结果图











结果分析
从图中可以看出来,基于长短期神经网络LSTM的路径跟踪 ,预测准确,泛发性好
展望
长短期神经网络在处理有时间关联性的问题方面,拥有独特的优势,预测结果更平滑,稳定,并且可调参,LSTM可以和其他是算法结合,比如粒子群优化LSTM参数,DBN+LSTM,等
参考论文
百科
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- k8s service的使用
- 【教学类-45-05】X-Y之间的三连加减题混合 (横向排列)(44格:11题“++ ”11题“--”11题“ +-”11题“ -+” )
- Python 对象属性和类属性
- 2023年12月25日:串口发出控制命令
- 为实例方法创建错误的引用(js的问题)
- 使用Portainer让测试环境搭建飞起来
- UI自动化测试框架搭建 —— yaml文件管理定位元素
- 【数据倾斜笔记】
- linux 设备驱动之tty 线路设置
- 使用css实现 Typora markdown 标题自动编号