新算法!直接写: EVO-CNN-LSTM-Attention能量谷优化卷积、长短期记忆网络融合注意力机制的多变量回归预测程序
适用平台:Matlab2023版及以上
能量谷优化算法(Energy valley optimizer,EVO)是2023年提出的一种新颖的元启发式算法。EVO算法的灵感来自于宇宙中粒子的行为,特别是这些粒子的稳定性和衰变过程。大多数粒子不稳定,倾向于通过分解或衰变来释放能量,而少数粒子则能无限期地保持稳定。该算法提出时间很短,目前还没有套用这个算法的文献
粒子衰变原理为EVO算法提供了基础。通过模仿粒子达到稳定状态的趋势,提高了粒子参数的性能。算法在优化问题中搜索初始候选项的最优解,并通过逐步更新的过程,寻求稳定点,类似于物理世界中粒子寻求稳定的行为,创新性较高。
优化套用:
我们利用EVO对我们的CNN-LSTM-SelfAttention卷积神经网络(CNN)结合长短期记忆网络(LSTM)融合多头自注意力机制(Multihead Self-Attention)的回归预测程序代码中的超参数进行优化;构成EVO-CNN-Attention预测模型。
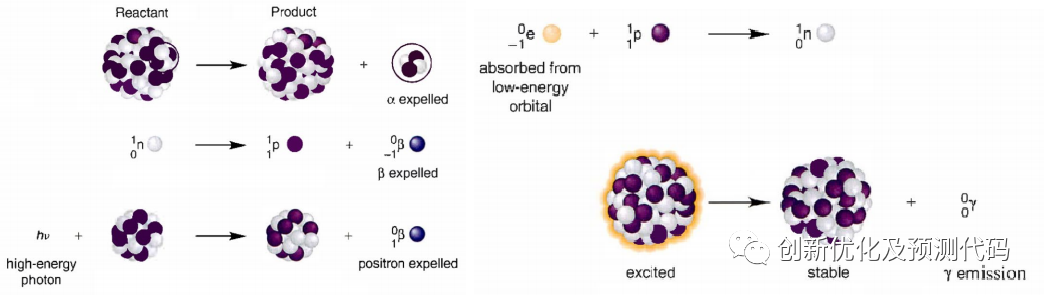
EVO算法考虑了三种衰变过程,即α衰变、β衰变和γ衰变,每种衰变类型对应于算法中不同的搜索和更新策略:
α衰变:涉及α粒子(密集且带正电)的发射,导致N(中子数)和Z(质子数)在N/Z比率中的减少。
β衰变:涉及β粒子(高速负电子)的弹射。这一过程通过减少N值和增加Z值来增加N/Z比率。
γ衰变:涉及γ射线(高能量光子)的发射。这种衰变类型不需要改变N/Z值。
EVO算法的创新点主要包括以下几个方面:
①引入了粒子衰变的概念:根据粒子衰变的物理原理,该算法模拟了粒子的衰变过程,并将衰变过程应用于解空间中的解候选者。通过衰变过程,可以根据粒子的稳定性水平来更新解向量,从而改进解候选者的性能。
②不同类型衰变模式的建模:算法中考虑了α衰变、γ衰变和β衰变三种衰变模式,并分别对它们进行了数学建模。通过生成随机数来确定发射粒子的数量和选择哪些粒子进行更新,从而模拟了粒子的衰变过程。
③基于稳定性水平的位置更新:根据粒子的稳定性水平,该算法采用了不同的位置更新方法。对于稳定性较低的粒子,采用控制性的移动方法使粒子向最佳稳定性水平的粒子靠近;对于稳定性较高的粒子,采用控制性的移动方法使粒子向邻近粒子靠近。这样可以在探索和开发之间找到一个平衡,提高算法的全局搜索能力。
④考虑了衰变过程中的约束:算法中考虑了粒子的中子富集水平和稳定性边界的约束条件。根据粒子的中子富集水平,可以确定粒子进行电子俘获或正电子发射的随机移动。这样可以更好地限制粒子的移动范围,避免超出预定义的上下边界。
综上,该算法通过模拟粒子的衰变过程和考虑约束条件,实现了对解空间中解候选者性能的改进。这些数学创新点使得算法能够在探索和开发之间寻找平衡,提高全局搜索能力,从而可以应用于解决复杂的优化问题。
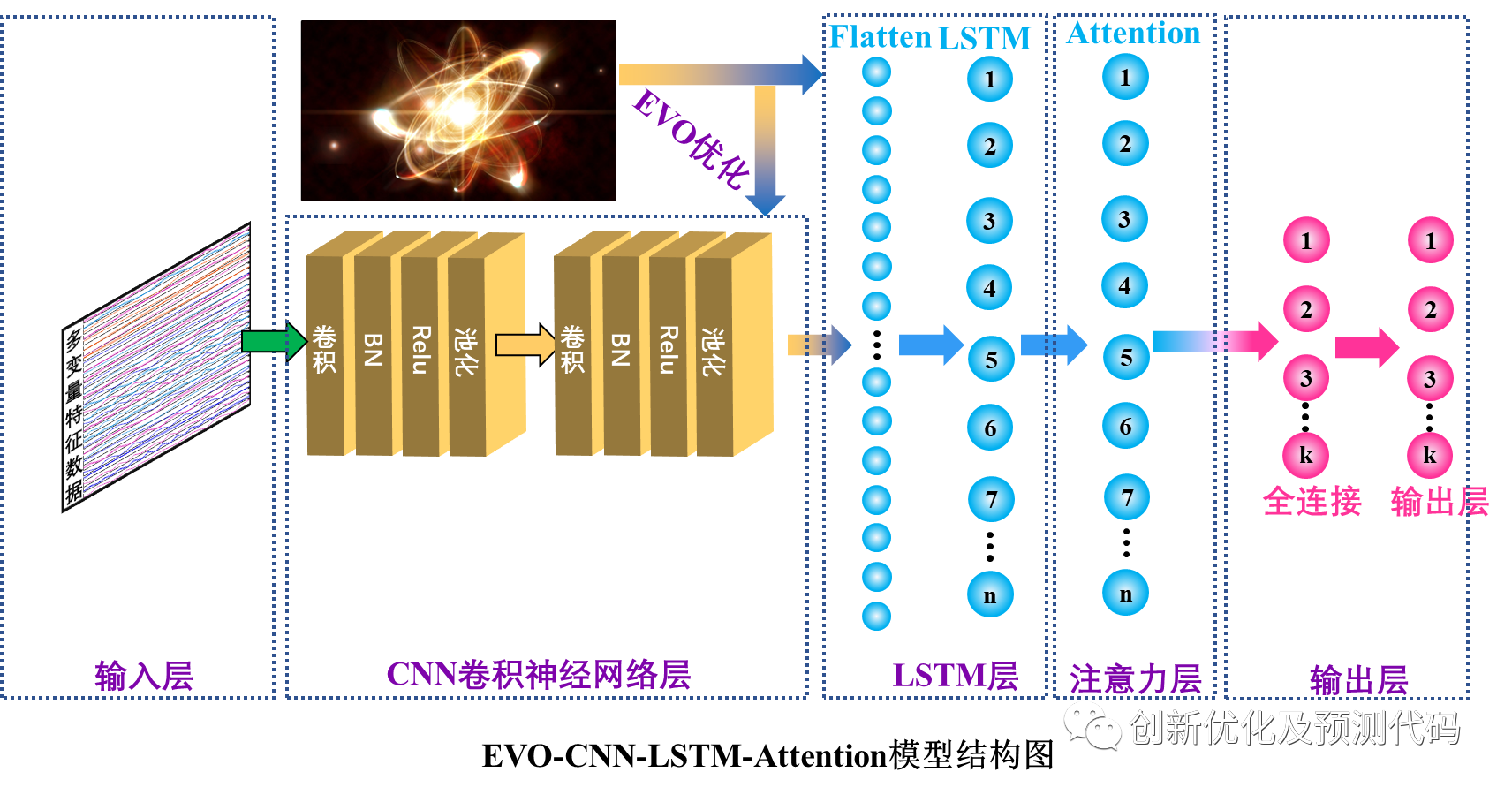
EVO-CNN-LSTM-Multihead SelfAttention预测模型的创新性:
卷积神经网络?(CNN):CNN用于捕捉序列数据中的空间相关性。它通过卷积核在输入数据上滑动,从局部区域提取特征,这有助于检测输入序列中的局部模式和特征。在CNN层之后通常会添加池化层来减小数据的空间维度,以降低计算复杂性。
长短时记忆网络?(LSTM):长短期记忆网络是一种循环神经网络(RNN)的变体,专门用于处理序列数据的建模。LSTM通过门控机制(输入门、遗忘门和输出门)来控制对过去信息的遗忘和记忆,从而有效地处理长序列依赖关系。在时序预测中,LSTM可以用于学习序列数据中的长期依赖关系,捕捉到序列中的时间演化模式。
自注意力层?(Self-Attention):Self-Attention自注意力机制是一种用于模型关注输入序列中不同位置相关性的机制。它通过计算每个位置与其他位置之间的注意力权重,进而对输入序列进行加权求和。自注意力能够帮助模型在处理序列数据时,对不同位置的信息进行适当的加权,从而更好地捕捉序列中的关键信息。在时序预测任务中,自注意力机制可以用于对序列中不同时间步之间的相关性进行建模。
EVO超参数优化:能量谷优化算法对模型中的难以确定的学习率、卷积核大小、神经元个数等参数进行寻优,使得模型的结构更加合理,提高了预测精度,对模型结构和训练参数进行优化,免除了人工选取参数环节,避免 了人为造成的不确定性因素,强化了模型的自适应 选择参数能力。
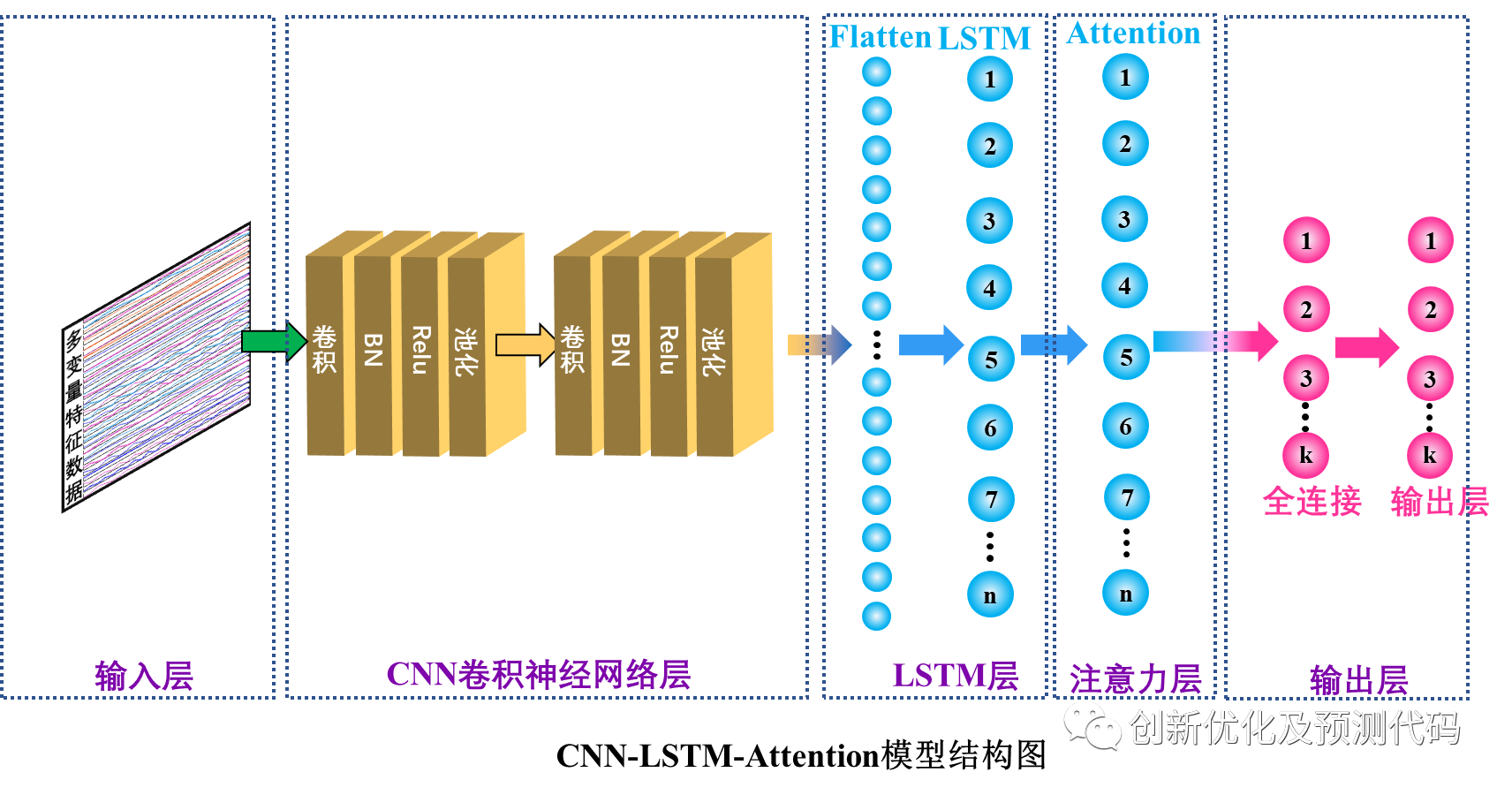
结合这四种层的结构,模型首先通过CNN层来捕捉输入序列的空间特征,然后通过LSTM层来捕捉时间相关性,最后通过Self-Attention层来更好地理解序列内部的关联。这种综合结构可以更全面地处理具有时空相关性的序列数据,引入EVO优化算法,对CNN-LSTM-Attention模型参数进行寻优,使得模型的结构更加合理,提高了预测精度,构成TSOA-CNN-LSTM-Attention复合预测模型。适用于,风速预测,光伏功率预测,发电功率预测,海上风电预测,碳价预测等等。它的创新点在于综合了不同类型的神经网络层,使其适用于广泛的应用,从而提高了对序列数据的建模和分析能力。
功能:
①多变量特征输入,单序列变量输出,输入前一天的特征,实现后一天的预测,超前24步预测。
②通过EVO优化算法优化学习率、卷积核大小、神经元个数,这3个关键参数,以最小MAPE为目标函数。
③提供损失、RMSE迭代变化极坐标图;测试对比图;适应度曲线(若首轮精度最高,则适应度曲线为水平直线)。
④提供MAPE、RMSE、MAE等计算结果展示。
适用领域:
风速预测、光伏功率预测、发电功率预测、碳价预测等多种应用。
数据集格式:
前一天18个气象特征,采样时间为24小时,输出为第二天的24小时的功率出力,也就是18×24输入,1×24输出,一共有75个这样的样本。

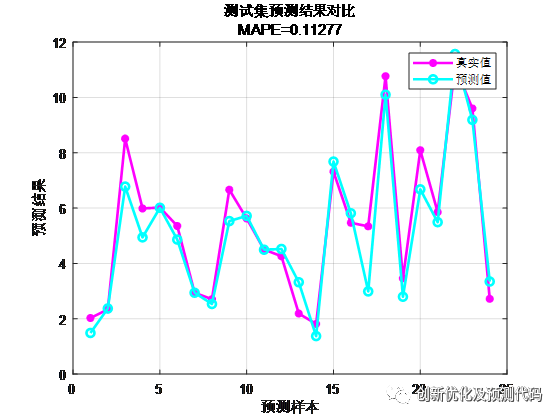
?预测值与实际值对比结果:
训练误差曲线的极坐标形式(误差由内到外越来越接近0):

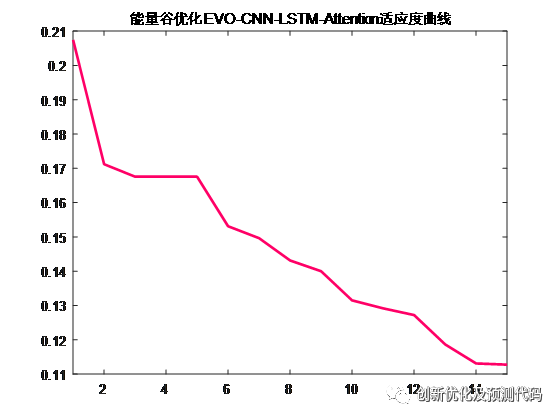
适应度曲线:
EVO部分核心代码:
完整代码:https://mbd.pub/o/bread/mbd-ZZiYm5lx
%% 能量谷优化算法EVO信息
CostFunction = @(x) objectiveFunction1(x); %% @目标函数
VarNumber = 3; %% 变量个数
VarMin = [0.001, 1, 100]; %% 变量下界(学习率,卷积核大小,神经元个数)
VarMax = [0.01, 5, 120]; %% 变量上界(学习率,卷积核大小,神经元个数)
%% 通用参数
MaxFes = 15 ; %% 最大函数评估次数
nParticles = 5 ; %% 初始候选解个数
%% 计数器
Iter=0; %% 迭代次数
FEs=0; %% 函数评估次数
%% 初始化
Particles=[]; NELs=[];tsmvalue={};
for i=1:nParticles
Particles(i,:)=unifrnd(VarMin,VarMax,[1 VarNumber]);
[NELs(i,1),tsmvalue{i,1},Net{i,1},Info{i,1}]=CostFunction(Particles(i,:));
FEs=FEs+1;
end
% 对粒子进行排序
for a = 1:size(NELs,1)
cellNEL{a,1} = NELs(a,:);
end
Mixdata=[cellNEL,tsmvalue,Net,Info];
sortedData = sortrows(Mixdata, 1);
[NELs, SortOrder]=sort(NELs);
Particles=Particles(SortOrder,:);
BS=Particles(1,:);
BS_NEL=NELs(1); %% 最优的误差结果
WS_NEL=NELs(end); %% 最差的误差结果
BS_PD=sortedData(1,2); %% 最小误差对应的预测结果
BS_NT=sortedData(1,3); %% 最小误差对应的网络
BS_IF=cell2mat(sortedData(1,4)); %% 最小误差对应的训练曲线
valubest=sortedData(:,2);
netbest=sortedData(:,3);
infobest=sortedData(:,4);
%% 主循环
while FEs<MaxFes
Iter=Iter+1;
NewParticles=[];
NewNELs=[];
Tsmvalues={};
NewNets={};
NewInfos={};
for i=1:nParticles
Dist=[];
for j=1:nParticles
Dist(j,1)=distance(Particles(i,:), Particles(j,:));
end
[ ~, a]=sort(Dist);
CnPtIndex=randi(nParticles);
if CnPtIndex<3
CnPtIndex=CnPtIndex+2;
end
CnPtA=Particles(a(2:CnPtIndex),:);
CnPtB=NELs(a(2:CnPtIndex),:);
X_NG=mean(CnPtA);
X_CP=mean(Particles);
EB=mean(NELs);
SL=(NELs(i)-BS_NEL)/(WS_NEL-BS_NEL); SB=rand;
if NELs(i)>EB
if SB>SL
AlphaIndex1=randi(VarNumber);
AlphaIndex2=randi([1 VarNumber], AlphaIndex1 , 1);
NewParticle(1,:)=Particles(i,:);
NewParticle(1,AlphaIndex2)=BS(AlphaIndex2);
GamaIndex1=randi(VarNumber);
GamaIndex2=randi([1 VarNumber], GamaIndex1 , 1);
NewParticle(2,:)=Particles(i,:);
NewParticle(2,GamaIndex2)=X_NG(GamaIndex2);
NewParticle = max(NewParticle,VarMin);
NewParticle = min(NewParticle,VarMax);
[NewNEL(1,1),Tsmvalue{1,1},NewNet{1,1},NewInfo{1,1}]=CostFunction(NewParticle(1,:));
[NewNEL(2,1),Tsmvalue{2,1},NewNet{2,1},NewInfo{2,1}]=CostFunction(NewParticle(2,:));
FEs=FEs+2;
else 部分图片来源于网络,侵权联系删除!
欢迎感兴趣的小伙伴关注下方公众号或代码前的链接获得完整版代码,小编会继续推送更有质量的学习资料、文章和程序代码!

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【计算机算法设计与分析】漂亮打印问题(C++_动态规划)
- Rust采集天气预报信息并实时更新数据
- 【洛谷 P8218】【深进1.例1】求区间和 题解(前缀和)
- Linux学习教程(第十六章 Linux系统启动管理)一
- Opencv4快速入门笔记
- OWASP TOP10漏洞
- 不同的酿酒文化影响葡萄酒风格
- delorean,一个超级实用的 Python 库!
- 机器学习笔记 - 音频信号处理基础知识
- 并行开发模式:低代码缩短产品开发周期,实现跨部门高效协作