深度学习基础之数据操作
深度学习中最常用的数据是张量,对张量进行操作是进行深度学习的基础。以下是对张量进行的一些操作:
首先我们需要先导入相关的张量库torch。

元素构造(初始化)
- 使用arange创造一个行向量,也就是0轴(0维)。


默认是按顺序创建,从0开始,元素类型默认是整数,当然也可以指定为浮点数。比如:
- 可以使用张量shape属性来访问张量(沿每个轴的长度)的形状(shape)。
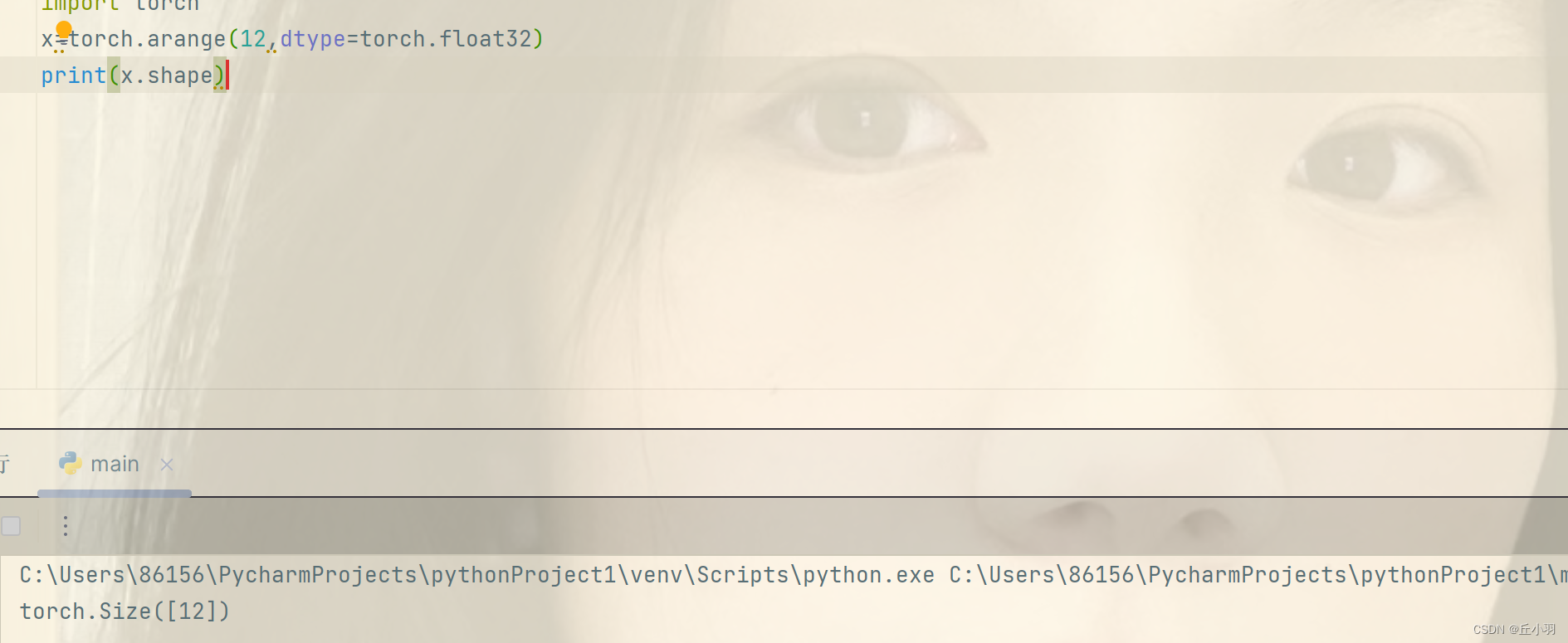
当然指的是形状,也可能不只是一个维度。
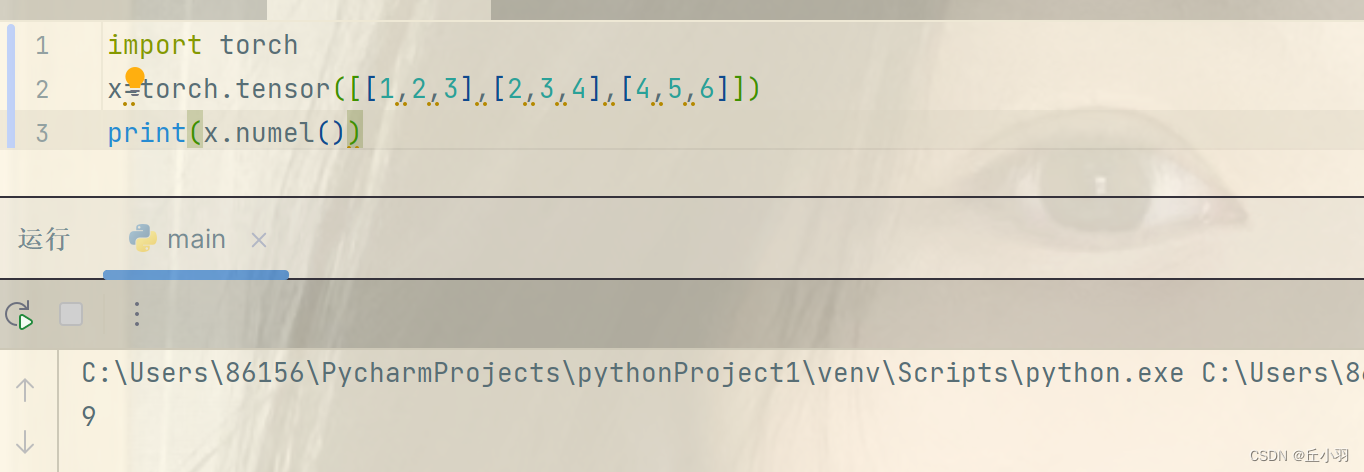
- 我们想知道张量中元素的总个数,也就是shape中所有元素的乘积,可以检查它的大小size。
- 要想改变一个张量的形状,但是不改变张量的大小,可以使用reshape函数,这个函数是将张量进行维度转化。直接见例子:

值得注意的是,这里的转化要求大小不变,比如我们的张量中一共有9个元素,那么我们只能转化为1*9,或者9*1,不能使之转化为2*4.5等。当然我们当然不是必须要计算出来每个维度的信息,如果我们需要转化为两个维度,而第一个维度已知是1,那么第二个维度可以直接用-1表示,另一个维度会自动被计算出来,我们可以省略一个维度。(最多省略一个维度)。
 维度的转化可以进行多维。
维度的转化可以进行多维。 - 有时候我们需要全0或者全1的张量,torch库中提供的有相应的函数。

- 有时候我们需要通过某个概率分布中随机采样来获得元素的值,当我们构造数组来作为神经网络中的参数的时候,我们通常随机初始化参数的值。以下是一个使用正态分布来初始化数组的代码,这里我们使用的是均值为0,标准差为1的正态分布。
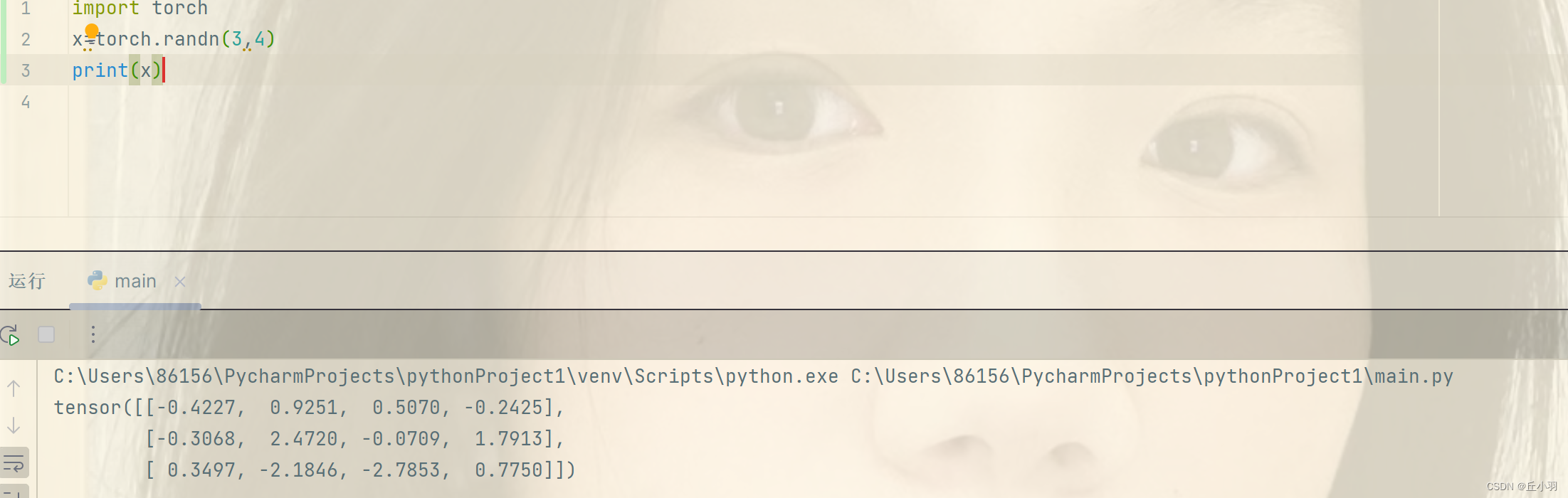
随机化的结果会因为每次运行的不同而有所不同。
当然,最简单的构造方法就是直接构造张量。这里我们使用tensor来直接构造。
运算符
- 运算中最常见的操作是加减乘除。
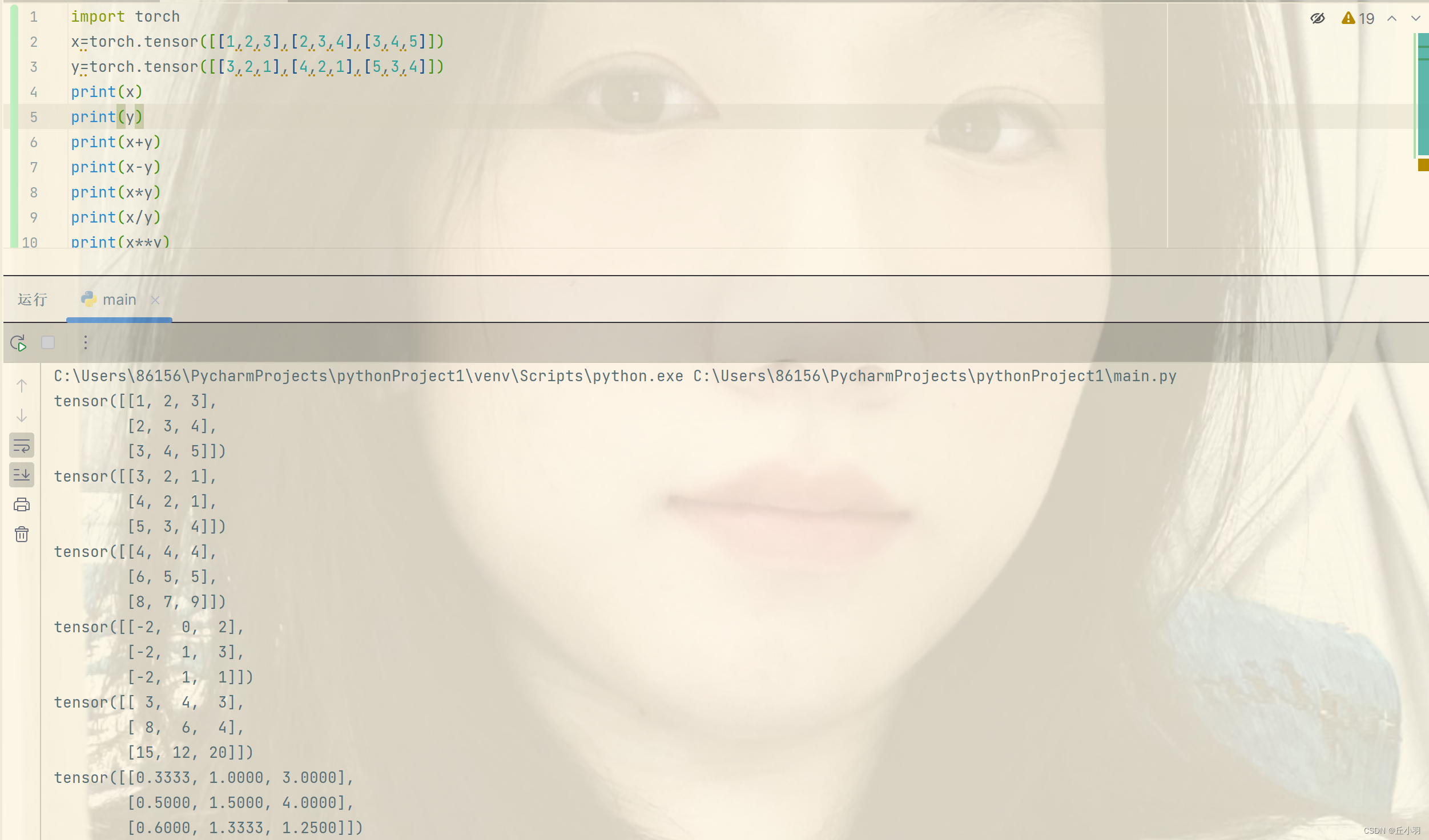 在上述结果中,除法运算默认保留四位小数。
在上述结果中,除法运算默认保留四位小数。
幂运算我们在大学线性代数中没有接触,其实就是相应位置的幂运算。
- 我们也可以把多个张量剪切到一起。连接(concatenate)对应的函数是cat。
这里dim是维度的意思,0维即是行,1维即是列,同理递推。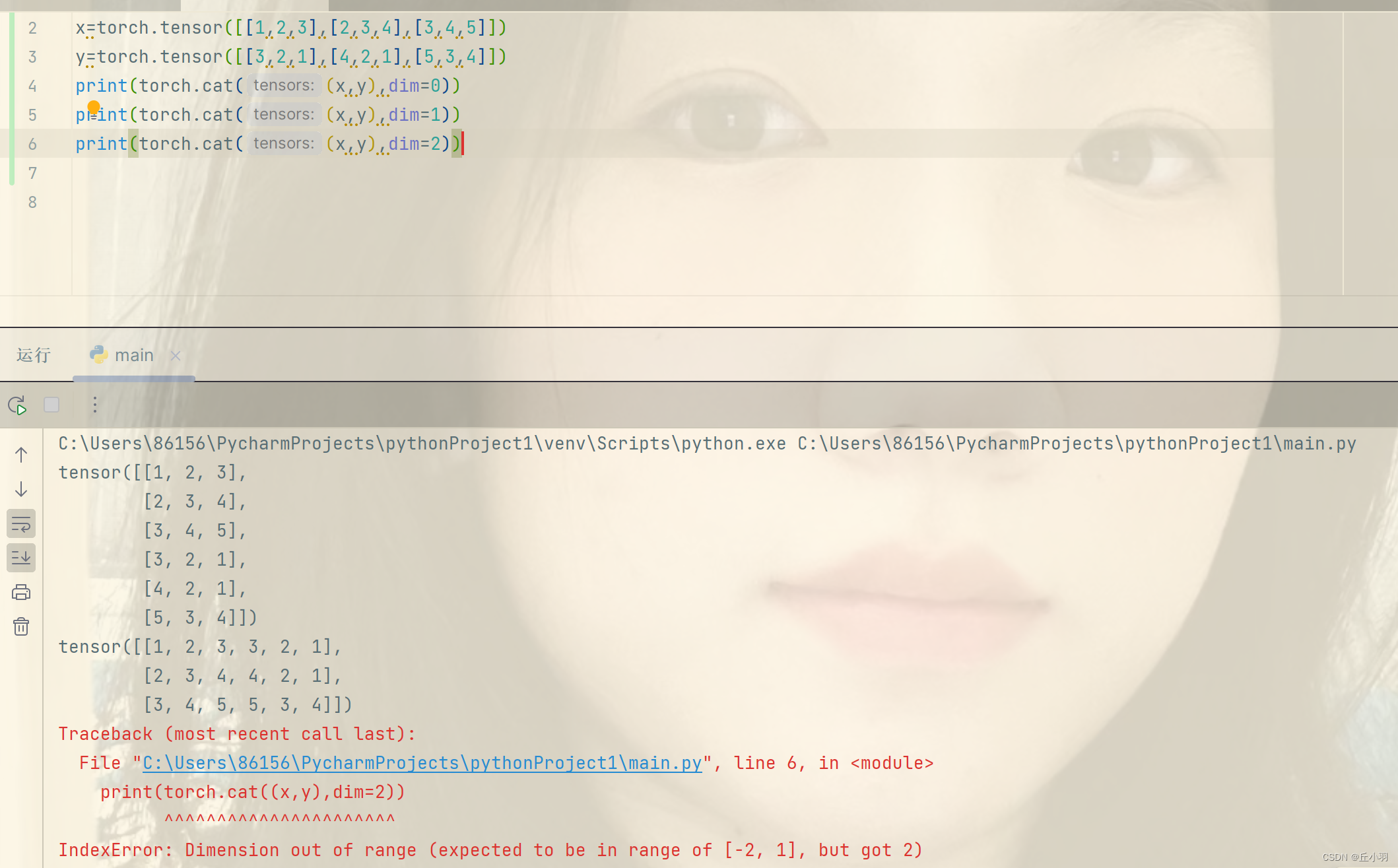
显然,维度不能超出范围。 - 还能判断对应位置元素是否相等,直接使用==判断,结果可不是返回一个数值0或1,而是返回一个张量,该张量是对应每个位置比较的结果。
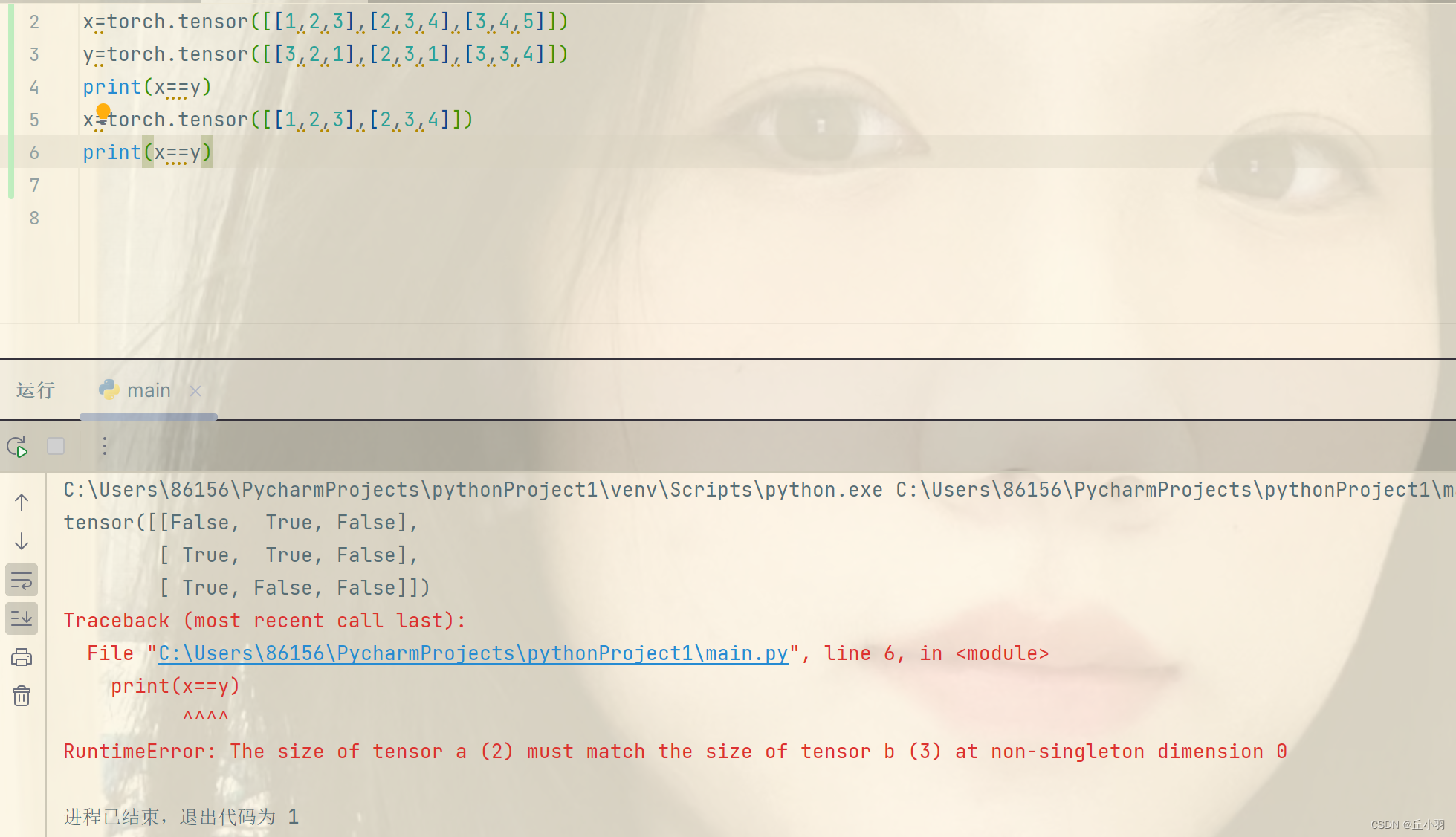
相同的问题,对于判断两个张量是否相等的运算,首先要确保这两个张量的shape(形状)要统一。
将张量中所有元素求和,会得到一个新的元素(单张量),也可以认为是维度是1。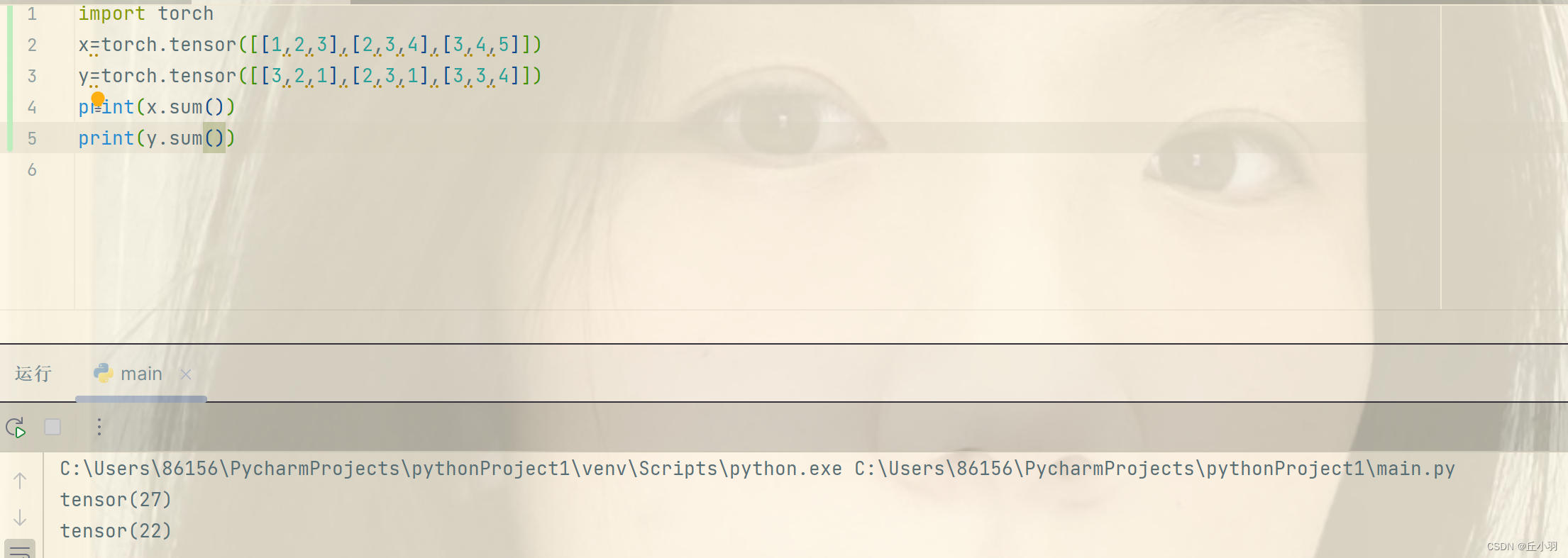
广播机制
广播机制就是通过适当复制元素来扩展一个或者两个数组,以便在转化之后两个数组具有相同的形状。但是大多数情况下,我们只会沿着维度为1 的轴进行广播。
在下图中,a的形状是2*2,没有维度是1的轴,无法进行广播,由于无法转化维度,导致不能与b相加。
接下来我们尝试用三阶张量替换广播机制中按元素操作的两个张量,看看是否符合预期。
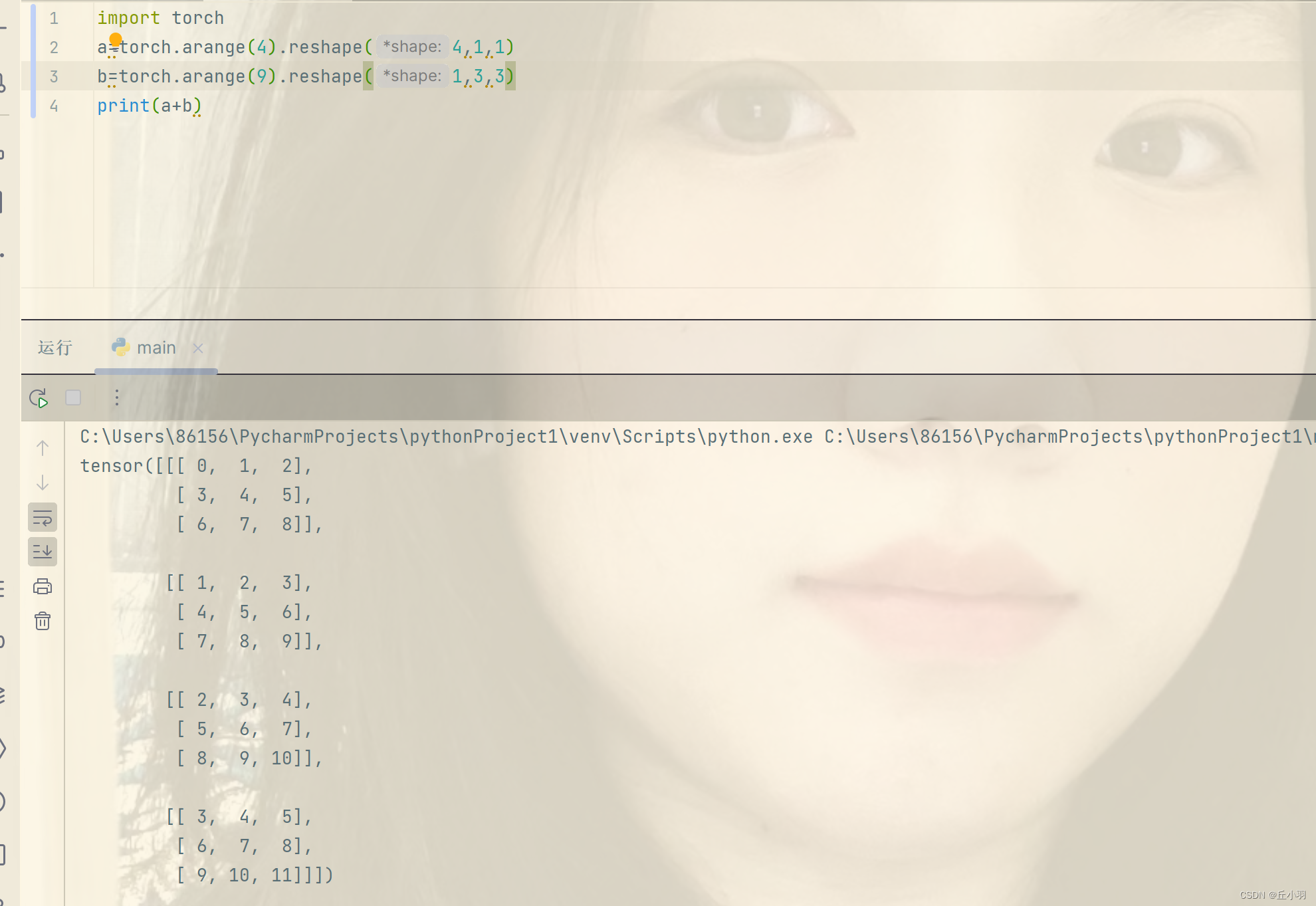
答案是肯定的,但是我们首先要确保,每个维度上都必须有至少一个1。(用于进行广播)。
索引和切片
- 用于读取元素:

如图,-1表示最后一个元素,张量经过reshape处理后有三个元素,reshape可以这样理解(第一个参数表示元素个数,后面的所有参数组成一个元素)。
第二个输出输出的是[1:3)的元素,左边参数是闭区间,右边参数是开区间。即选取 1和2。分别是第二个元素和第三个元素,元素的索引是从0开始的。
更改元素: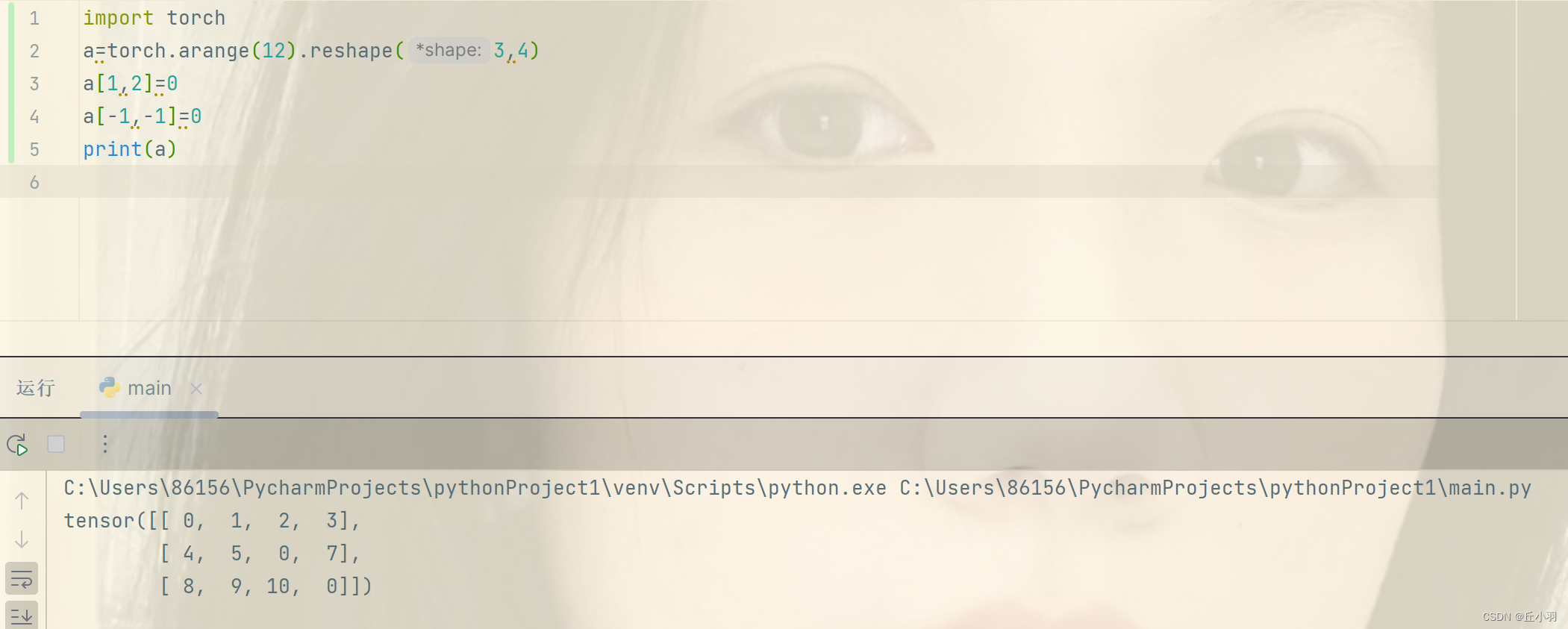
在这里,我们使第二行第三列的元素更改为0,最后一行最后一列的元素也更改为0。
当然,当我们进行有规律的大规模连续更改的时候,我们使用切片。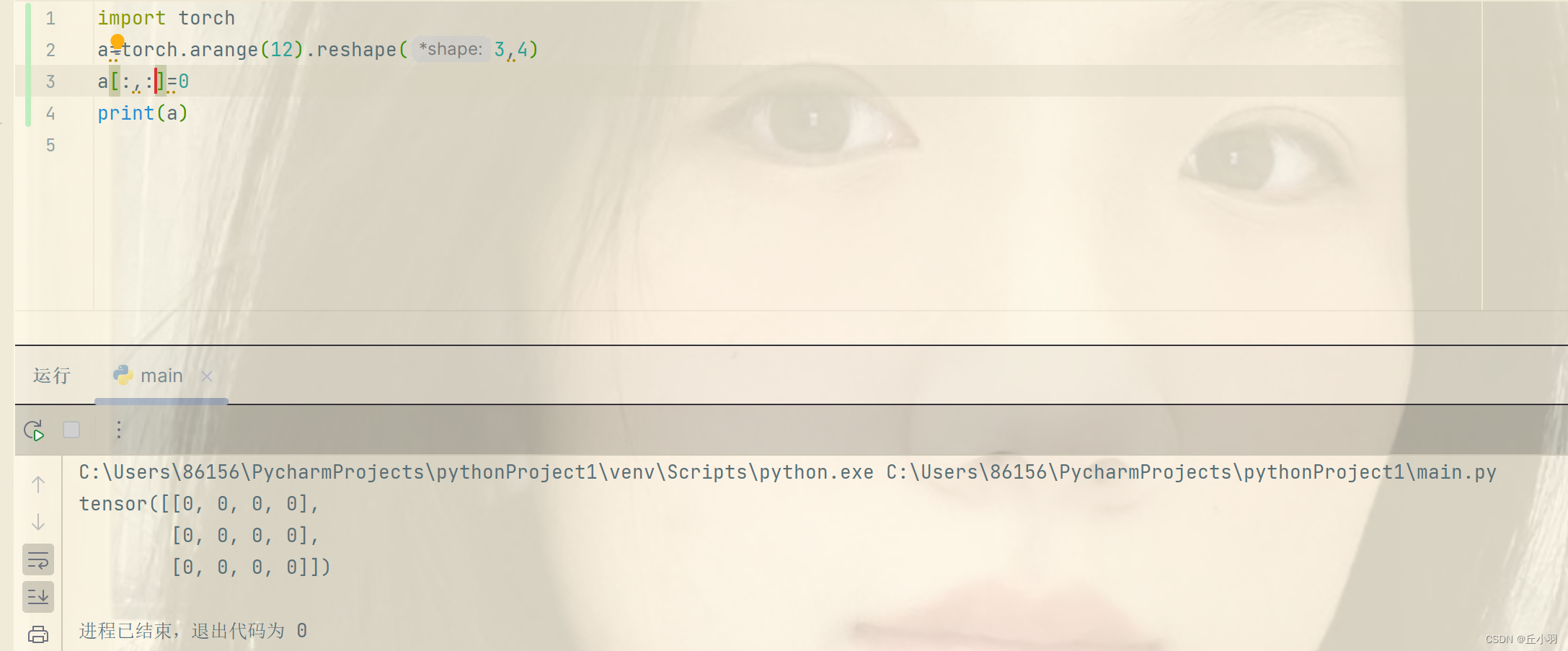
“:”表示默认,第一个参数表示是默认所有行,第二个参数表示是默认所有列。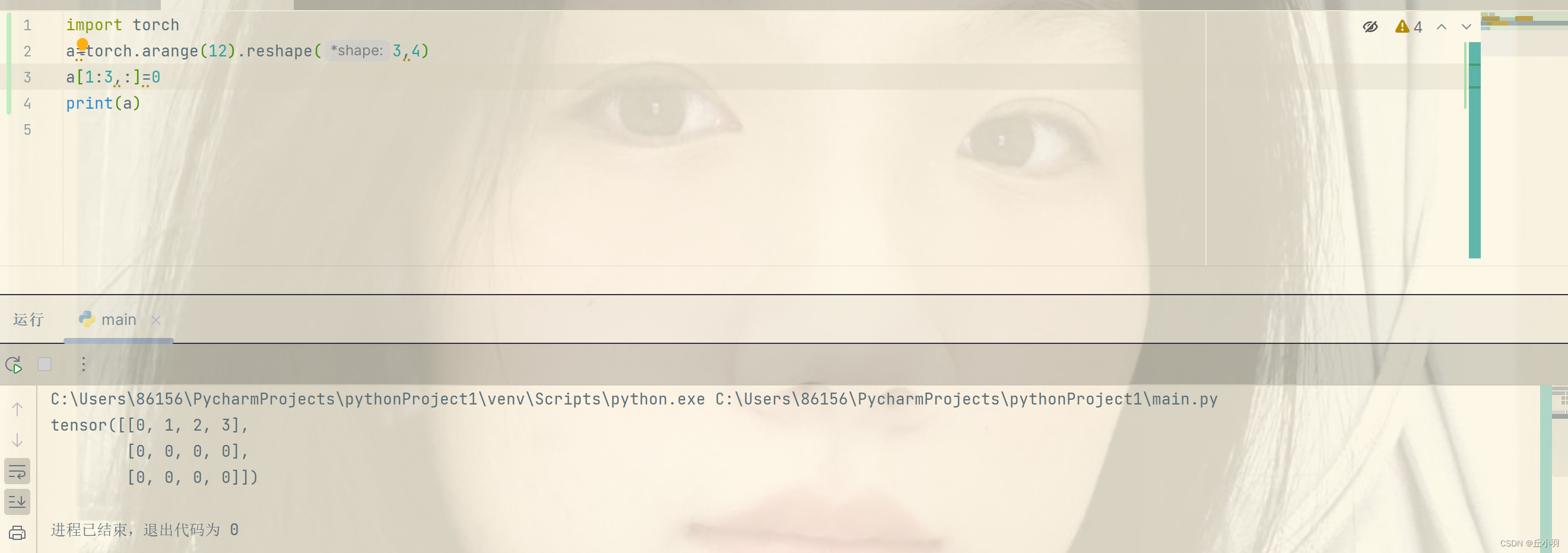
这样,我们就指定2,3行,所有列进行更改。
节省内存
首先思考一个问题:x=x+y和x+=y是否相同:
在结果上时相同的,但是在内存分配上却不相同,第一个式子是为x重新分配一个内存来存储x张量,第二个式子是在原有x张量内存的基础上进行更改。我们可以用id函数来可视化:注意这里不能使用torch.ones(3,4)来创建。只能使用ones_like来创建,或者是zero_like来创建。
为什么说重新分配内存是不可取的:
首先,在机器学习中,我们可能有数百兆的参数,并且在一秒内多次更新参数,如果不原地执行这些更新的话,会占用大量的内存。
其次,如果不进行原地更新,其他的引用仍然会指向旧的内存地址,这样我们的代码可能无意间引用旧的参数。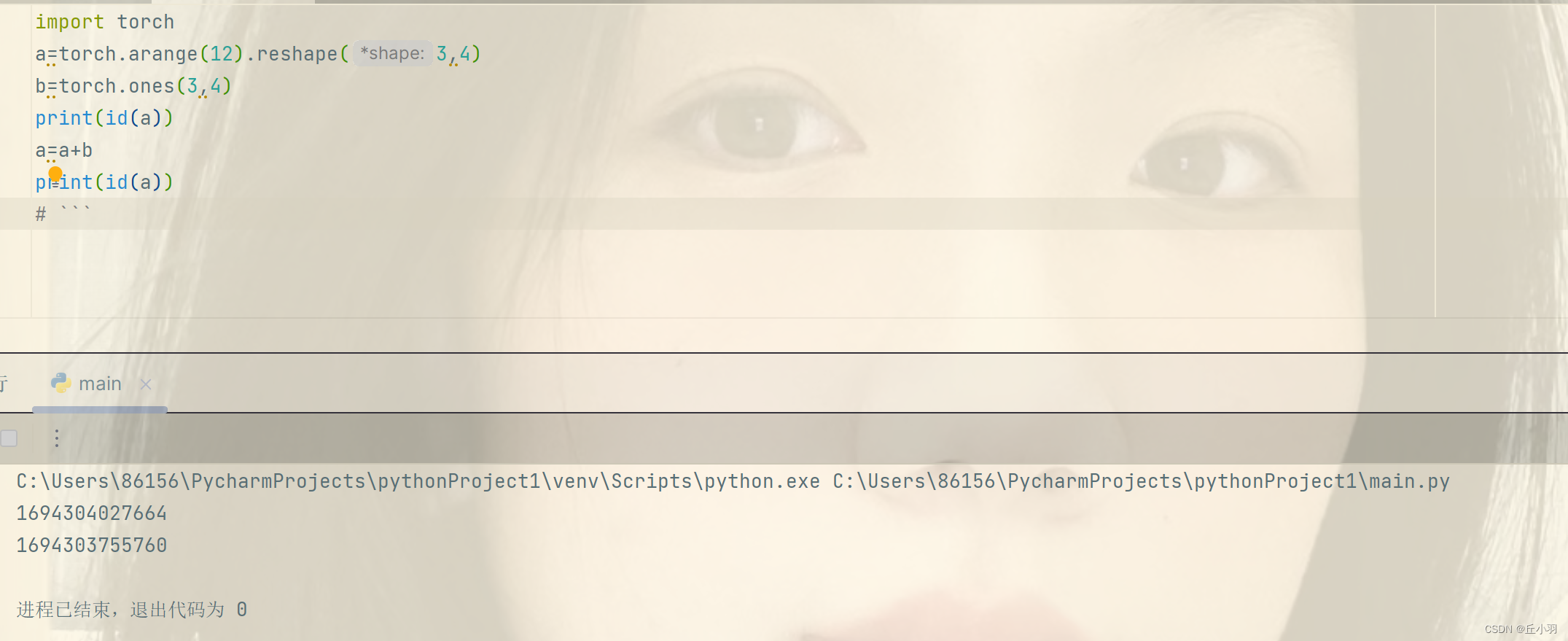

当然也可以使用a[:]=<expression>来原地更新。比如: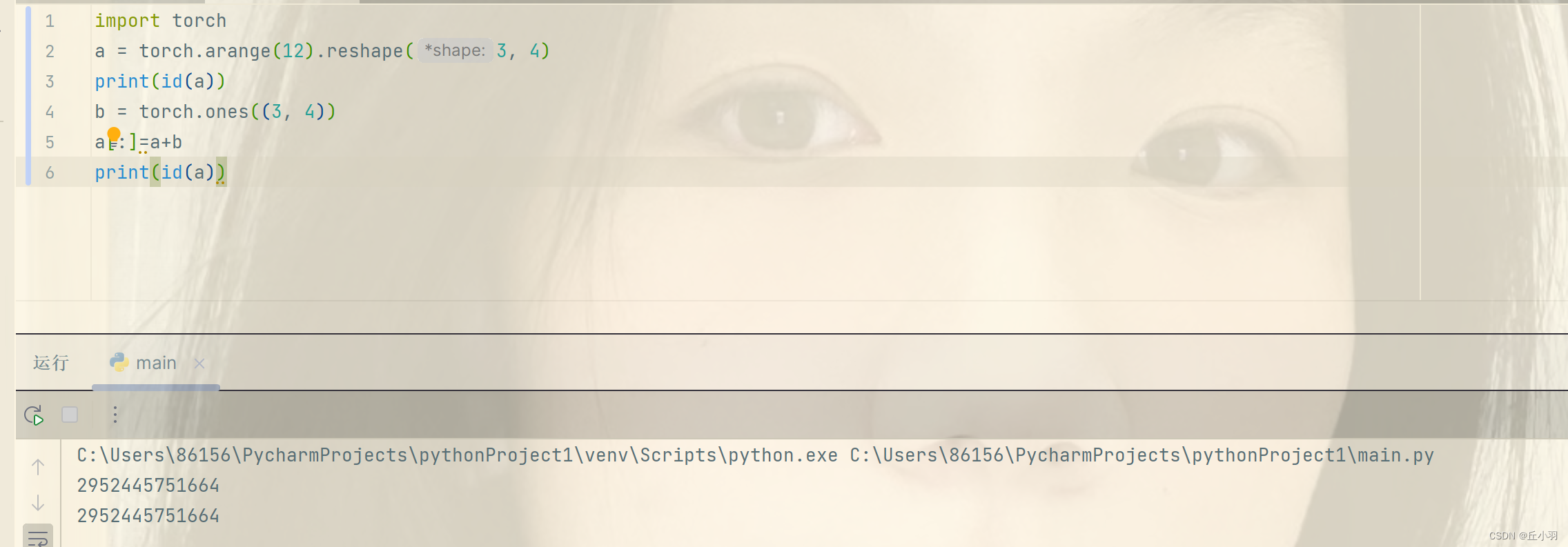
有趣的是,这里可以使用torch.ones或者torch.zeros来创建张量,并且进行+=操作的时候不报错。
转化为其他类型的Python对象
将深度学习框架(pytorch)转化为Numpy张量对象(ndarray)很容易,反之也很容易。

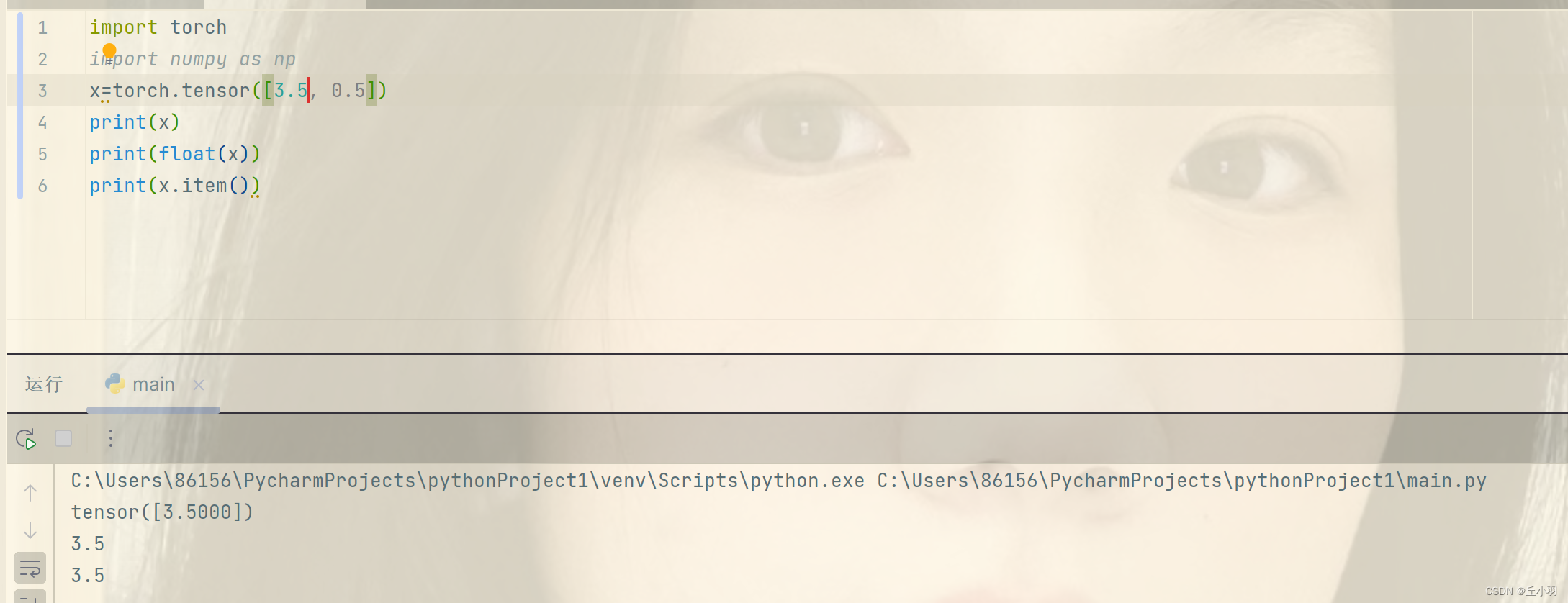
当然,张量也可以转化为标量。(仅适用于大小为1的张量)
总结:
深度学习存储和操作数据的主要接口是张量(n维数组),它提供了各种功能,包括基本数学运算,广播,索引,切片,内存节省和转化为其他Python对象。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Git 提交指定文件的部分修改
- 使用DBscan算法进行密度聚类分析
- SpringMVC简介
- 为什么学C语言和做底层的工作不好找,工资还没做Java的高?
- 算法练习Day16 (Leetcode/Python-二叉树)
- MongoDB 索引管理
- 书生·浦语大模型实战营-学习笔记6
- 算法设计与分析期末上机板子——课内题目题意与题解分析+课外知识点总结!
- “神秘巨鲸”将数十亿USDT转入交易所!花旗前高管,绕过美证监会发行比特币证券!比特币将迎来拉涨行情?
- 充电桩如何选型MOS