【STM32学习】硬件CRC与传统CRC-32计算的不同点
硬件CRC与传统CRC-32计算的不同点
1、stm32的硬件CRC32与传统CRC-32有何不同?
①STM32F103的硬件CRC校验是对整个32位字进行CRC计算,传统的CRC-32是逐字节的计算。
②STM32的硬件CRC32的每个字节的位序相反,STM32是按32位,高位在先,而主流实例每字节里面是从低位起的。
③最终计算结果主流实例与0xFFFFFFFF进行了异或,而STM32并没有。
对于①的解释:
将01 02 03 04 05 06 07 08作为输入。
对于传统的CRC校验而言:01 02 03 04 05 06 07 08(8个hex数据),它是一个字节一个字节的计算。
对于硬件CRC32校验而言:0x00000001 0x00000002 … 0x00000008(8个hex数据),一个32位字一个32位字进行计算。
由此可见,计算结果肯定是不同的。
对于②③的解释,见关于STM32F4xx的硬件CRC32校验
2、解决办法
上述的链接中已经详细介绍了②③的解决方法。
// MDK使用
__asm u32 Revbit (u32 data)
{
RBIT R0, R0
BX LR
}
__asm u32 Revswap(u32 data)
{
REV R0, R0
BX LR
}
/*
RBIT:把一个32位的数据按位倒置,效果如下:
原数据 01000001 01000010 01000011 01000100,0x41424344
执行后 00100010 11000010 00100100 10000010,0x42c22482
REV:把一个32位数据的字节序改变(若芯片是小端则转为大端),效果如下
原数据 0x12345678
执行后 0x78563412
*/
对于①的解决办法:
当进行数据校验时,多数情况下,是一个uchar类型的数组。
这个数组直接输入到传统的CRC-32校验中,没有任何问题,因为它是按字节计算的。
而输入到硬件CRC中时,需要先将uchar数组按顺序拼接一个个32位字长的数据,然后输入到硬件CRC中。
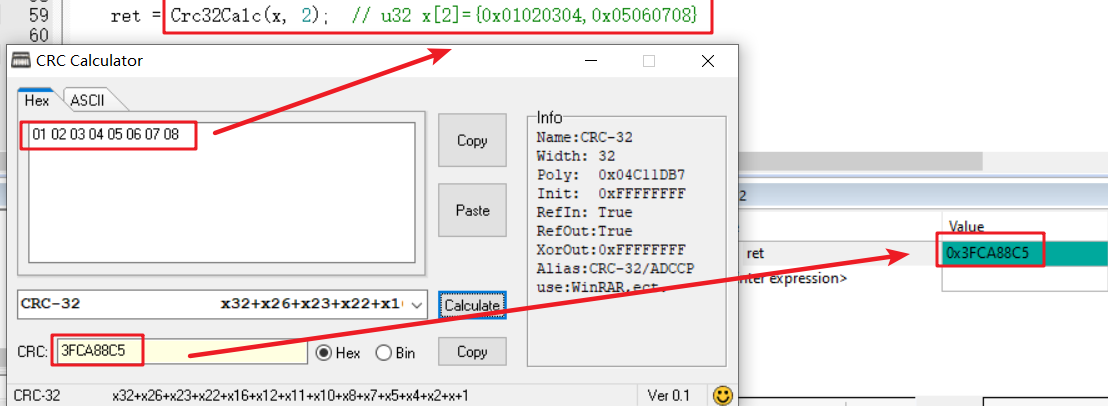
例如,若uchar数组为01 02 03 04 05 06 07 08。
8个hex数据直接输入到传统CRC-32中即可。
对于硬件CRC而言,需要将数据组织为0x01020304,0x05060708,两个hex数据输入到硬件CRC中。
但是还有一个问题,当字节长度不是4的倍数时,组织成32位字长的数据就会留有空白。
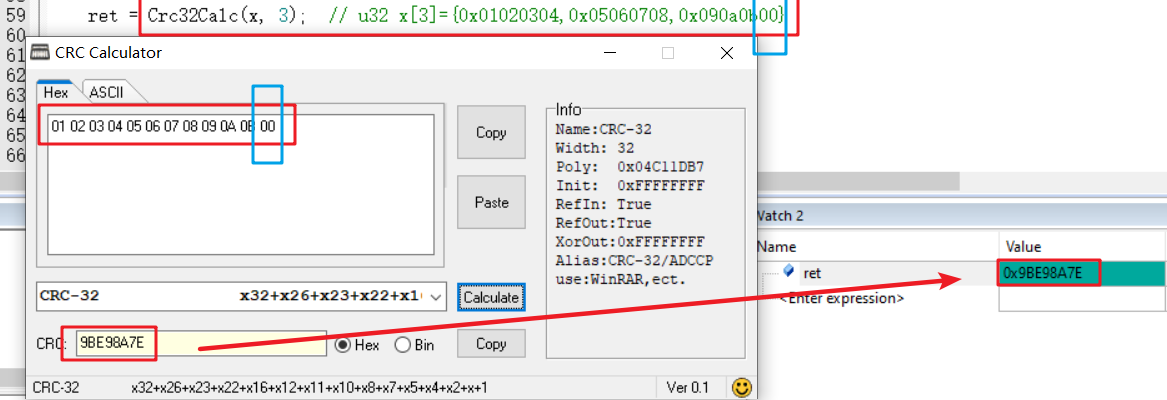
例如,uchar类型的数组为01 02 03 04 05 06 07 08 09 0a 0b,一共11个hex数据。
那么,组合成的32位字长为0x01020304,0x05060708,0x090a0b__,最后一个字节空闲。
那么怎么解决呢?我们可以做一个约定,约定两端在进行校验时,如果有空闲存在,需要进行补充。
可以约定用0x00、0xFF进行空闲的补充。
例如,下图约定使用0x00进行补充。
代码分享:
// 自己将01 02 03 04 --> 0x01020304,然后放入数组中,作为输入参数。
uint32_t Crc32Calc(uint32_t *pucBuf, uint8_t ucLen)
{
uint8_t i;
CrcReset();
for (i = 0;i<ucLen;i++)
{
CRC->DR = Revbit(Revswap(pucBuf[i]));
}
return ~(Revbit(CRC->DR));
}
// 01 02 03 04 直接存放在Uint8 aucBuf数组中,以(Uint32*)aucBuf的形式传入
uint32_t Crc32CalcA(uint32_t *pucBuf, uint8_t ucLen)
{
uint8_t i;
CrcReset();
for (i = 0;i<ucLen;i++)
{
CRC->DR = Revbit(pucBuf[i]);
}
return ~(Revbit(CRC->DR));
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- PHP 支付宝(单笔转账到银行账户接口)
- redis事务
- 微信小程序案例-03翻页时钟-3
- 深入了解 npm 命令
- 【taro react】---- 解决 taro 编译 H5 姓名脱敏导致的 iOS 部分低版本白屏问题
- 宝塔面板Linux服务器CentOS 7数据库mysql5.6升级至5.7版本教程
- 前端检测字符串中是否含有特殊字符,并返回该特殊字符
- thinkphp6.0升级到8.0
- AI in Cybersecurity
- 写一个简单的python服务测试