牵绳遛狗你我他文明家园每一天,助力共建文明社区,基于YOLOv5开发构建公共场景下未牵绳遛狗检测识别系统
遛狗是每天要打卡的事情,狗狗生性活泼爱动,一天不遛就浑身难受,遛狗最重要的就是要拴绳了,牵紧文明绳是养犬人的必修课。外出遛狗时,主人手上的牵引绳更多是狗狗生命健康的一道重要屏障。每天的社区生活中,相信大家都会或多或少的在路上遇上一些遛狗的人不讲文明不讲武德,出门就是习惯性的不牵绳子遛狗,对于自己不熟悉的狗狗来说我们自然是害怕的,频频报道的狗咬人的事件也是层出不穷,,“狗狗性格温顺不会咬人的”这一类所谓的说辞不是放纵不牵绳子的理由。

对于此类的现象是否能够从技术的角度来进行思考甚至是干预呢?我想理论上来说也是可行的,本文的主要目的就是站在不牵绳遛狗这个大背景下探索基于技术手段来分析对此类行为干预的可行性,这里主要是基于YOLOv5开发构建对应的目标检测模型,我们的设计初衷就是考虑未来这样的技术手段能够结合路边、河道、社区、门口等等的可用的视频摄像头,对于画面中出现的遛狗目标对象进行实时的智能计算分析,如果发现问题就可以通过语音播报提醒,如果还是不加改正就可以将当前的时段视频发送到相关的部门来跟进处理,当然了,这些比较偏向业务应用层面不是我们开发者所能决定的,这里主要是结合我们的所见所想来开发构建实践性质的项目。
前文我们已经进行了相应了开发实践感兴趣的话可以自行移步阅读:
《牵绳遛狗你我他文明家园每一天,助力共建文明社区,基于DETR(DEtection TRansformer)开发构建公共场景下未牵绳遛狗检测识别系统》
《牵绳遛狗你我他文明家园每一天,助力共建文明社区,基于YOLOv3开发构建公共场景下未牵绳遛狗检测识别系统》
《牵绳遛狗你我他文明家园每一天,助力共建文明社区,基于YOLOv4开发构建公共场景下未牵绳遛狗检测识别系统》
首先看下实例效果:
?
简单看下实例数据情况:

如果对如何基于YOLOv5开发构建自己的目标检测应用的话可以参考我前面的超详细教程:
《基于自建数据集【海底生物检测】使用YOLOv5-v6.1/2版本构建目标检测模型超详细教程》
这里就不再展开介绍了,接下来看下训练数据配置文件内容:
# Dataset
path: ./dataset
train:
- images/train
val:
- images/test
test:
- images/test
# Classes
names:
0: dog
1: rope
YOLOv5是一种快速、准确的目标检测模型,由Glen Darby于2020年提出。相较于前两代模型,YOLOv5集成了众多的tricks达到了性能的SOTA:
yolov5主要分为以下几部分:
Input
Backbone
Neck
Head
Input部分主要是集成了强有力的自动化数据处理和数据增强技术,可以自动padding原图自动计算最优anchor设定,采用了Mosaic数据增强融合了CutMix数据增强的方法,Mosaic数据增强由原来的两张图像提高到四张图像进行拼接,并对图像进行随机缩放,随机裁剪和随机排列。使用数据增强可以改善数据集中,小、中、大目标数据不均衡的问题,在源头端创造了足够广泛、丰富有代表性的数据集,在模型训练过程中可以降低对GPU资源的消耗量,因为随机增强技术的加持对于不同尺寸的目标或者是不均衡类别目标的检测识别能力都有所提升。
Backbone部分主要包含:Conv、C3、SPFF,Conv卷积层由卷积,Batch Normalization和SiLu激活层组成。batch normalization具有防止过拟合,加速收敛的作用。C3包含了3个标准卷积层,数量由配置文件yaml的n和depth_multiple参数乘积决定,经历过残差输出后去掉了卷积模块,激活函数换成了SiLU。
Neck部分主要是SPPF和PAN,SPPF(Spatial Pyramid Pooling - Fast )改进了原始的SPP模块,使用3个5×5的最大池化,代替原来的5×5、9×9、13×13最大池化,多个小尺寸池化核级联代替SPP模块中单个大尺寸池化核,从而在保留原有功能,即融合不同感受野的特征图,丰富特征图的表达能力的情况下,进一步提高了运行速度。PANet改进了FPN模块,在FPN的基础上又引入了一个自底向上(Bottom-up)的路径。经过自顶向下(Top-down)的特征融合后,再进行自底向上(Bottom-up)的特征融合,这样底层的位置信息也能够传递到深层,从而增强多个尺度上的定位能力。
Head部分主要用于检测目标,分别输出20*20,40*40和80*80的特征图大小,对应的是32*32,16*16和8*8像素的目标。
实验截止目前,本文将YOLOv5系列n、s和m这三款不同参数量级的模型均进行了开发评测,接下来依次看下模型详情:
【yolov5n】
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 2 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]【yolov5s】
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 2 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
#Backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
#Head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]【yolov5m】
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 2 # number of classes
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]在实验训练开发阶段,所有的模型均保持完全相同的参数设置,等待训练完成后,来整体进行评测对比分析。
【F1值曲线】
F1值曲线是一种用于评估二分类模型在不同阈值下的性能的可视化工具。它通过绘制不同阈值下的精确率(Precision)、召回率(Recall)和F1分数的关系图来帮助我们理解模型的整体性能.F1分数是精确率和召回率的调和平均值,它综合考虑了两者的性能指标。F1值曲线可以帮助我们确定在不同精确率和召回率之间找到一个平衡点,以选择最佳的阈值。
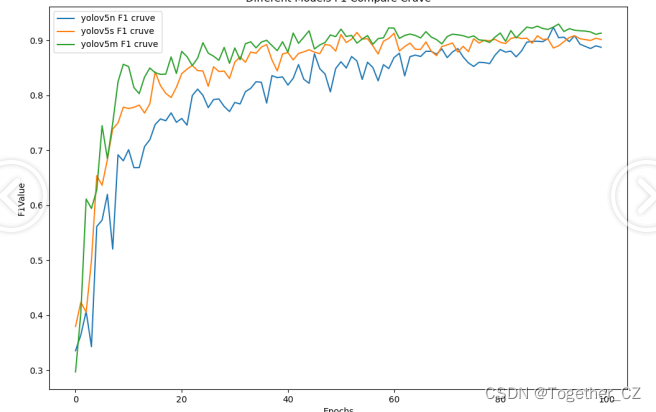
【loss曲线】

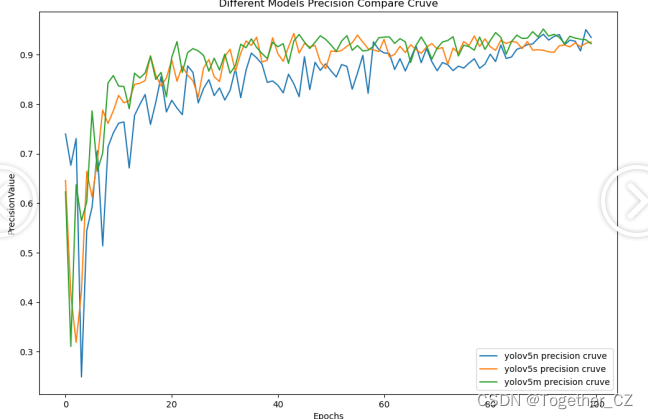
【Precision曲线】
精确率曲线(Precision-Recall Curve)是一种用于评估二分类模型在不同阈值下的精确率性能的可视化工具。它通过绘制不同阈值下的精确率和召回率之间的关系图来帮助我们了解模型在不同阈值下的表现。精确率(Precision)是指被正确预测为正例的样本数占所有预测为正例的样本数的比例。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。
【Recall曲线】
召回率曲线(Recall Curve)是一种用于评估二分类模型在不同阈值下的召回率性能的可视化工具。它通过绘制不同阈值下的召回率和对应的精确率之间的关系图来帮助我们了解模型在不同阈值下的表现。召回率(Recall)是指被正确预测为正例的样本数占所有实际为正例的样本数的比例。召回率也被称为灵敏度(Sensitivity)或真正例率(True Positive Rate)。
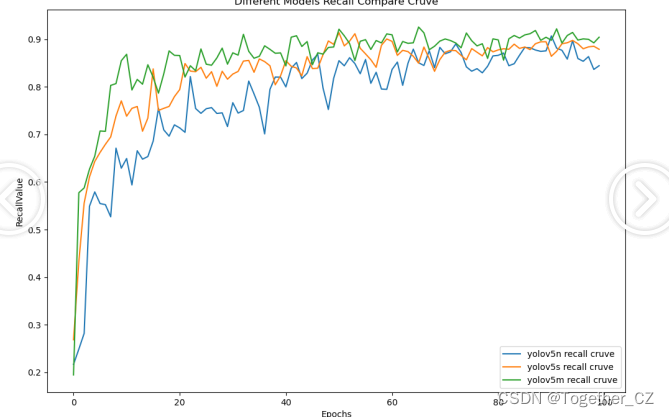
从三款模型的实验评估结果上来看:n系列的模型效果最差,s系列次之,s和m系列模型很接近没有明显的差距,这里我们最终选择使用m系列的模型来作为我们的基准检测模型。
接下来我们以m系列基准模型为例看下详细的结果:
【数据分布可视化】
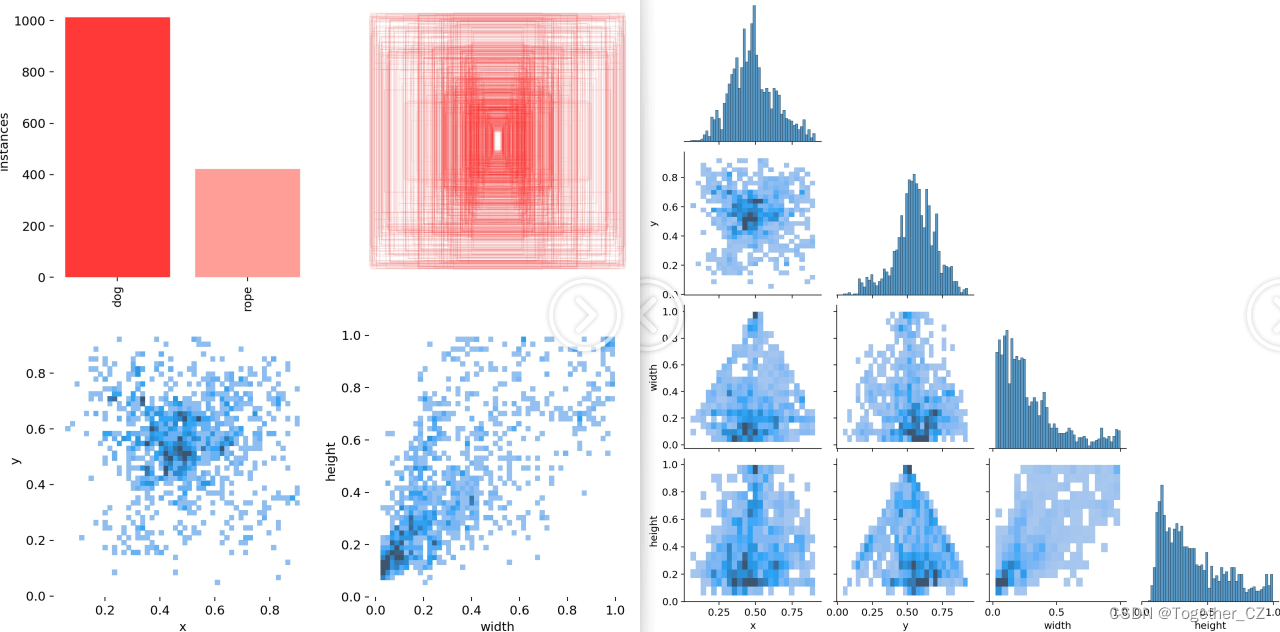
【训练可视化】

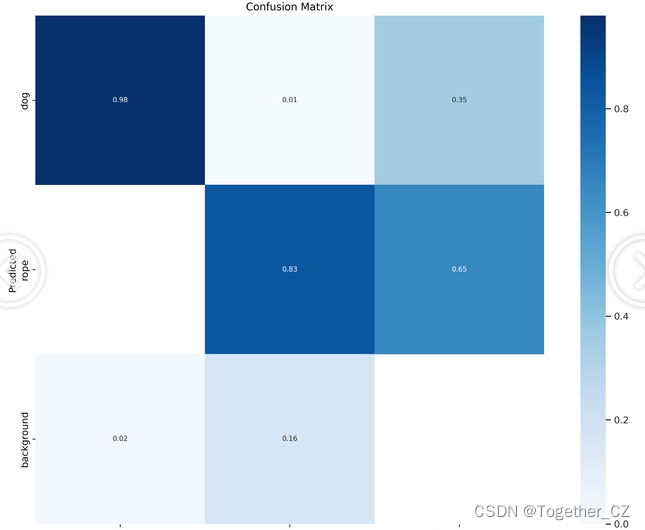
【混淆矩阵】
【Batch实例】

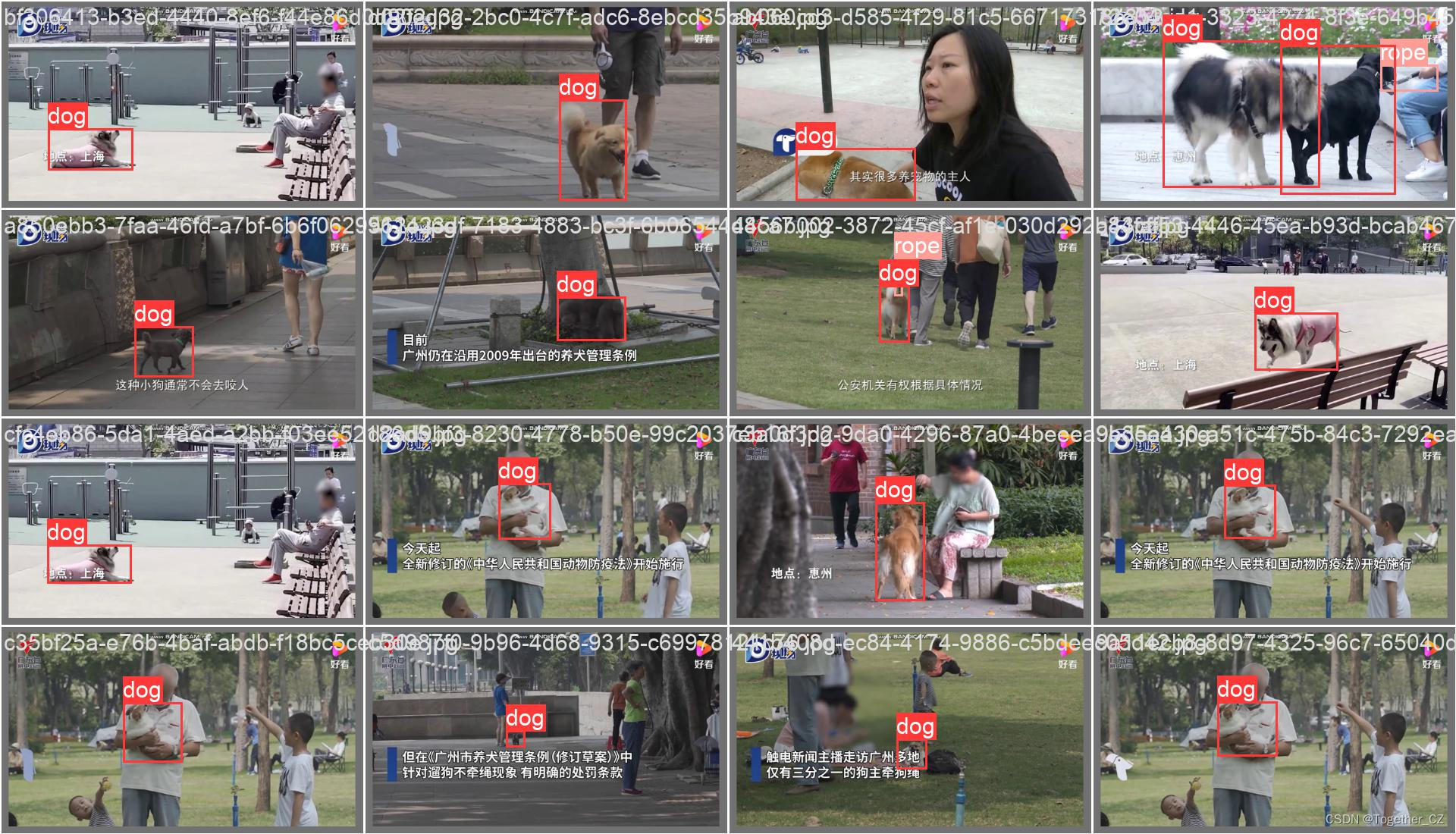
离线推理实例如下所示:

感兴趣的话也可以随着文章动手做一下构建一个属于自己的目标检测系统吧。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Matlab 之数据分布拟合
- EasyExcel导出多个sheet 并完成对指定sheet页进行操作
- idea下项目Tomcat启动日志乱码解决方案
- MyBatis-逆向工程
- 【嵌入式——QT】QAbstractTableModel继承
- 易点易动有效管理固定资产出入监控,助力企业降低固定资产丢失率
- 在css中如何实现表单验证效果
- php之pdf使用
- TinyLlama-1.1B(小羊驼)模型开源-Github高星项目分享
- 2.1 DATA PARALLELISM