Zookeeper(一)特性与节点数据
CAP&Base理论
CAP理论
? ? ? ? 1、一致性(Consistency): 在分布式环境中,一致性是指数据在多个副本之间是否能够保持一直的特性;
? ? ? ? 2、可用性(Availability):每次请求都能获得正确的响应,但不保证获取的数据为最新数据;
? ? ? ? 3、分区容错性(Partition tolerance):分布式系统在遇到任何网络分区故障的时候,任然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障;
这三个中最多只能同事满足两项,P是必须满足的,因此只能是CP(一致性)和AP;zookeeper保证的是CP,eureka实现的是AP;
Base理论
BASE是Basically Available(基本可用)、Soft-sate(软状态)和Eventually Consistent(最终一致性);
1、基本可用:分布式系统出现故障,允许损失部分可用性(降级);
2、软状态:中间状态;中间状态不影响系统的可用性。这里的中间状态是指不同的数据备份节点之间的数据更新可以出现延时的数据最终一致性;
3、 最终一致性:个数据节点经过一段时间达到一致性;
Base理论是对CAP理论的一个权衡,核心思想是:我们无法做到强一致性,可以根据业务特性采用最终一致性策略处理;
Zookeeper写入是强一致性,读取是顺序一致性;
客户端将数据写入任意一个节点都会转到leader中去写入,leader节点写入成功以后,follower节点靠分布式事务保证大多数节点写入成功以后返回;
少数读取非一致性问题Zookeeper提供了读取之前到leader拉去最新数据的操作(sync);
Zookeeper中有版本号的概念;
Zookeeper
概念
Zookeeper是一个开源分布式协调框架,主要用来解决分布式一致性问题;
本质上他也是一个分布式的小文件管理系统(文件系统+监听机制);
设计者本身是基于观察者模式设计的分布式服务管理框架;一但数据发生变化,zookeeper可以将变化通知到注册的观察者;
配置文件详解
# zookeeper时间配置中的基本单位(毫秒)
tickTime=2000*
# zookeeper时间配置中的基本单位(毫秒)tickTime=2000允许follower初始化连接到leader最大时长,它表示tickrime时间倍数即:initLimit * ticktime
initLimit=10
#允许follower与leader数据同步最大时长,它表示tickTime时间倍数
syncLimit=5
#zookeper数据存储目录及目志保存目录(如果没有指明dataLogDir,则日志也保存在这个文件中,次会存储类似mysql中的事务日志,换成固态硬盘存储路径可优化性能)(tmp目录尽可能替换否则可能会被当成临时文件删除)
dataDir=/tmp/zookeeper
#对客户端提供的端口号
clientPort=2181
#单个客户端与zookeeper最大并发连接数
maxclientCnxns=60
#保存的数据快照数量,之外的将会被清除
autopurge.snapRetainCount=3
#自动触发清除任务时间间隔,小时为单位。默认为0,表示不自动清除。autopurge.purgeInterval=1
安装启动略过
数据模型
Zookeeper数据模型是层次模型,层次模型常见于文件系统。层次模型和key-value模型是两种主流的数据模型;
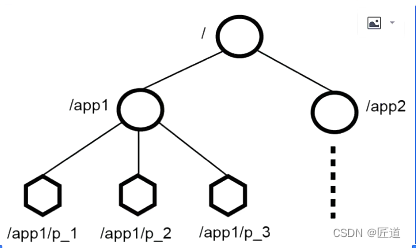
1、每个节点只允许存储1m数据;
节点分类
1、持久节点:这样的节点在创建之后及时发生Zookeeper集群宕机或者client宕机也不会丢失;
2、临时节点:client宕机或者client在指定的timeout时间内没有给集群发送消息,节点就会丢失;
3、持久顺序节点:除了具备持久性之外,名字具备顺序性;
4、临时顺序节点:除了具备临时节点的特点意外,名字具备顺序性;
5、容器节点:当容器中没有任何子节点,该容器节点会被zk定期删除;
6、TTl节点:带过期时间节点;
节点状态重要信息
1、cZxid:节点创建事务id;
2、ctime:节点创建时间;
3、mZxid:节点被修改的事务id,每次修改节点都会更新mZxid(保证事务特性的关键信息)
4、pZxid:节点列表最后一次修改的事务id,增减删除节点时修改;?
5、dataVersion:数据版本信息
6、ephemeralOwner:临时节点存储sessionId(客户端链接为长链接)的属性,不是临时节点则为0;
监听机制
1、一个监听事件是一个一次性的触发器(3.6版本后增加永久性监听);
2、zookeeper采用了watcher机制实现数据发布订阅功能
3、watcher机制事件上与观察者模式类似;
watcher的过程:
1、客户端向服务端注册watcher
2、服务端实践触发watcher
3、客户端回调watch二得到触发时间情况
特点:
一次性、客户端顺序回调、轻量级、时效性
使用场景
1、注册中心
2、数据发布/订阅
3、负载均衡
4、明明服务
5、分布式协调通知
6、集群管理
7、Master选举
8、分布式锁
9、分布式队列
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 外汇网站主要业务逻辑梳理
- 对Java Stream 进行二次封装
- 已解决:UnicodeDecodeError: ‘gb2312‘ codec can‘t decode byte 0xe5 in position 1
- redis原理(四)数据安全之数据持久化
- 文心一言4.0使用指南
- Spring Boot项目集成Mybatis-Plus
- 数据分析-24-母婴产品电商可视化分析(包含代码数据)
- 202402读书笔记|《当你老了》——灰蒙曙光比爱情温柔,清晨露珠比希望更可爱
- 什么是变量预解析
- 【教程】代码混淆详解