第三篇:大模型技术进阶之stage三步走
上一篇文章我们讲到从GPT-1到GPT-3包括Meta开源的LLaMA模型其实都只是在pretraining stage。要真正达到ChatGPT的水平还需要supervised finetuning,reward model和reinforcement learning三个stage。

Supervised Finetuning
尽管prompt的方法省去了训练的工作,但是表现不够稳定。从实际角度看Finetuning还是更加稳定。所以ChatGPT首先用少量但是高质量的(prompt, response)人工数据作为监督,来微调GPT-3 model,从而得到SFT model。

这一过程相比于base model耗时大大减少,例如Vicuna-13B模型是从LLaMA Finetuning而来。LLaMA耗费了135K GPU hours,耗费5M $。 而Vicuna-13B只需要8个A100 一天内就可以训练完成,耗费300$。这个阶段的模型也是可以部署的,同时也能取得不错的效果。因此很多公司和研究机构往往选择在这个阶段进行投入。
Reward Modeling
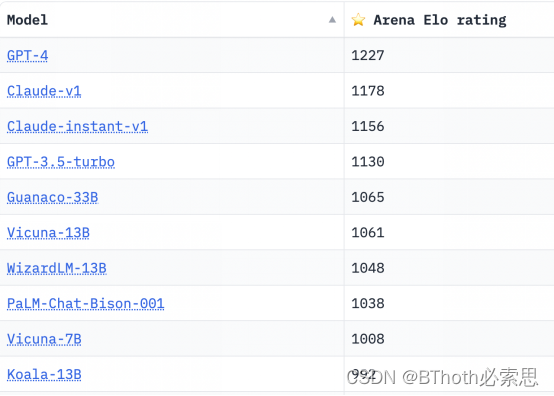
在SFT基础上,我们可以得到一个用于QA的助手模型。尽管此时模型已经从GPT模型finetune为一个专用的助手模型,但是它仅仅是具备了QA的能力,它的输出结果可能并不是最优的。那么此时openai团队对模型的输出结果进行了额外的处理。他们让模型对同一个prompt(question)输出不同三种答案,然后让人类标注员对输出的三种结果进行排序。用这个排序的结果来训练一个奖励模型,从而判断模型每次输出的质量。
为什么会输出不同结果?
看到这里可能有些熟悉Transformer架构的同学可能会问,为什么模型可以输出三个不同的结果。Transformer里面完全没有随机性的算子,例如Dropout或者random。其实在GPT输出结果的时候,有一个变量叫做temperature。因为每次推理 next token的时候,模型都会根据前文生成next token的概率分布,但是考虑到过拟合的问题,模型不会每次只输出概率最高的那个token。而是根据概率实际分布,概率性的取next token,至于控制到底是取max confidence的token还是按概率取,这个变量是由temperature控制的。
这种排序标注的先进性体现在两个方面。一方面,排序比打分更加客观,不受标注人员的标注标准不同的影响。另一方面,标注效率比打分高。所以包括ChatGPT,Stable Diffusion,Midjourney都采用了这样类似的RLHF(Reinforcement Learning from Human Feedback)的机制来对结果进行优化。然后排序结果可以通过一些算法转换为得分,我们把得分作为一个新的token放到QA后面,这样SFT模型就可以转换为一个reward model,从而为我们最终服务于增强学习的stage。
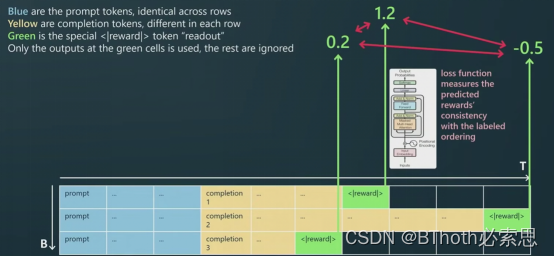
Reinforcement Learning
在上一个stage,我们有了奖励模型RM。现在我们要用RM来finetune我们的生成模型。此时训练目前从绿色变为黄色。通过赏功罚过的机制,对模型进行微调,从而得到更优的模型输出。

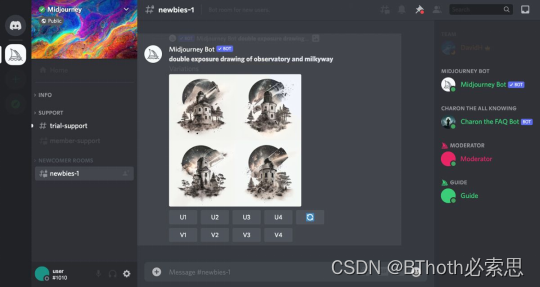
类似思路进行模型优化的还有Midjourney--11个人做到年收入1亿美元的神奇公司。目前市面上对人像生成最为真实的模型。MJ最强的不是其模型本身,而是它构建了一个良性循环的社区。用户可以免费试用他们的产品,每次生成4张图片,如果你觉得哪张照片效果好,可以花钱让MJ生成它的高清版本。这个看似平平无奇的过程,实际上就是RLHF。用户在挑选一个效果最好结果的过程就其实在给MJ进行标注数据。所以MJ的模型使用量越大,效果就越好,而且用户还会付费给他们标注数据。形成了一个良性循环。


小结
至此我们再简单回顾一下它的训练流程。在Pretrain,SFT和RL阶段训练的模型都是可以直接部署的。RM阶段的模型只是为了最后评估结果而训练的一个中间模型,不具备部署的价值。且后三个阶段的训练成本都比较低,一般公司和学校都可以承担的起。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!