【大数据处理】消费者行为与购物习惯数据分析及可视化
相关文章及代码下载
1. 探究的问题陈述
数据集来源:kaggle
https://www.kaggle.com/datasets/zeesolver/consumer-behavior-and-shopping-habits-dataset/data
这是一个在kaggle上的消费者行为与购物习惯的数据集。
消费者行为和购物习惯数据集提供了有关消费者在购物过程中的偏好、倾向和模式的全面洞察。该数据集包含各种变量,包括人口统计信息、购买历史、产品偏好、购物频率以及在线/离线购物行为。有了这些丰富的数据就可以研究消费者决策过程的复杂性,帮助企业制定有针对性的营销策略、优化产品供应和提高整体客户满意度。
消费者行为和购物习惯数据集详细概述了消费者的偏好和购买行为。它包括人口统计信息、购买历史、产品偏好和首选购物渠道(在线或离线)。该数据集对于旨在调整战略以满足客户需求和提升客户购物体验的企业来说至关重要,最终将促进销售额和忠诚度的提高。
数据集术语表(按列排列)
客户ID(Customer ID):分配给每位客户的唯一标识符,便于跟踪和分析客户的长期购物行为。
年龄(Age):顾客的年龄,为细分和有针对性的营销策略提供人口统计信息。
性别(Gender):客户的性别标识,是影响产品偏好和购买模式的关键人口统计变量。
购买项目(Item Purchased):顾客在交易过程中选择的特定产品或项目。
类别(Category):所购商品所属的大类或组别(如服装、电子产品、杂货)。
购买金额(Purchase Amount):交易的货币价值,以美元(USD)表示,表示所购物品的成本。
地点(Location):进行购买的地理位置,有助于了解地区偏好和市场趋势。
尺寸(Size):所购商品的尺寸规格(如适用),与服装、鞋类和某些消费品相关。
颜色(Color):与所购商品相关的颜色变体或选择,影响客户偏好和产品供应。
季节(Season):所购商品的季节相关性(如春、夏、秋、冬),影响库存管理和营销策略。
审查评级(Review Rating):顾客对所购商品满意度的数字或定性评估。
订阅状态(Subscription Status):表示客户是否选择了订阅服务,以深入了解客户的忠诚度和获得经常性收入的潜力。
运送类型(Shipping Type):指定所购商品的配送方式(如标准配送、快递),影响配送时间和成本。
折扣应用(Discount Applied):说明购买时是否应用了促销折扣,从而揭示价格敏感度和促销效果。
使用的促销代码(Promo Code Used):说明交易过程中是否使用了促销代码或优惠券,有助于评估营销活动的成功与否。
以前的购买记录(Previous Purchases):提供有关客户之前购买次数或频率的信息,有助于客户细分和保留策略。
付款方式(Payment Method):指定客户使用的付款方式(如信用卡、现金),以便深入了解首选付款方式。
购买频率(Frequency of Purchases):表示客户参与购买活动的频率,是评估客户忠诚度和终身价值的重要指标。
2. 所探究的问题
对于这个数据集我们可以调探究各种因素在决定消费者行为和购物习惯的影响性,如季节性、物品属性(大小和颜色)、和促销活动(折扣和促销码),以及客户购买前的心理决策。
是否有特定的季节,某些产品类别表现更好?
特定的商品属性或促销是否会显著影响购买金额?
利用消费者行为和购物习惯数据集,分析客户人口统计数据(年龄和性别)与他们的购买行为之间的关系。
是否有特定的产品类别或购物渠道受到特定年龄群体或性别的青睐?
如何利用这些信息来设计更有针对性的营销策略?
3. 导入的python库和模块并初始化
import csv
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import plotly.express as px
from matplotlib import style
plt.rcParams["font.sans-serif"] = ["SimHei"]
df=pd.read_csv('C:\\Users\\w\\Desktop\\vscode_project\\Consumer behavior and Shopping habits – Clustering\\shopping
_behavior_updated.csv')首先导入了所需的库和模块,并使用pandas的read_csv方法读取了一个名为'shopping_behavior_updated.csv'的CSV文件,并将数据存储在名为'df'的DataFrame对象中。并设置了一些绘图预设,指定字体及图形化后端界面的类型。
4. 数据准备和清理
首先了解要处理的数据以及每列的数据类型是否有用。数据类型可能决定了如何转换和设计功能。
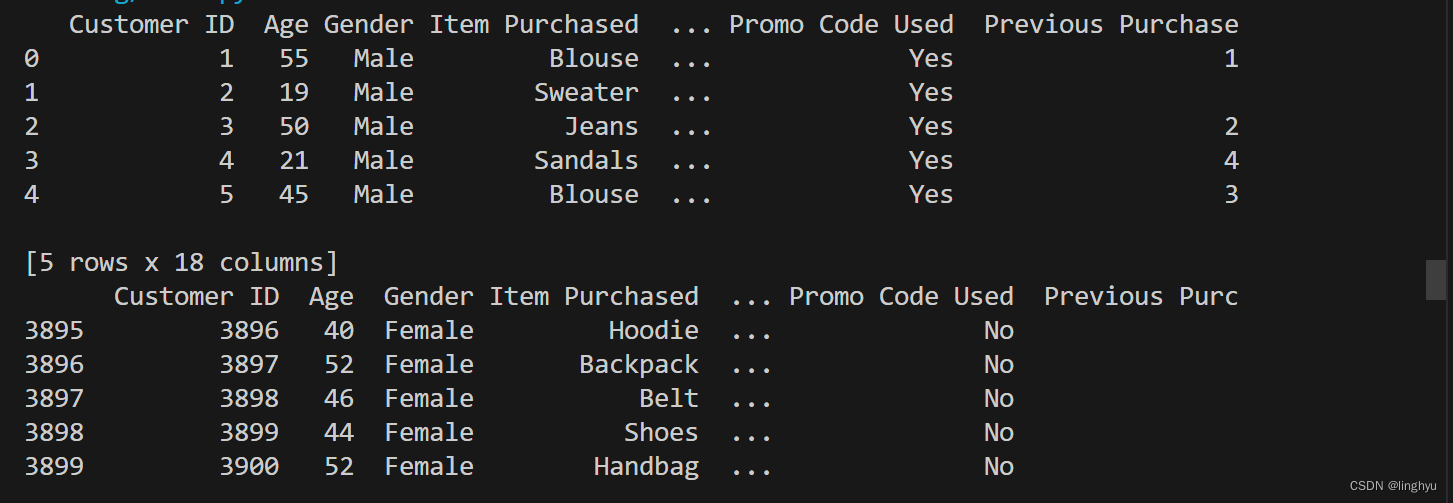
print(df.head(5))
print(df.tail(5))
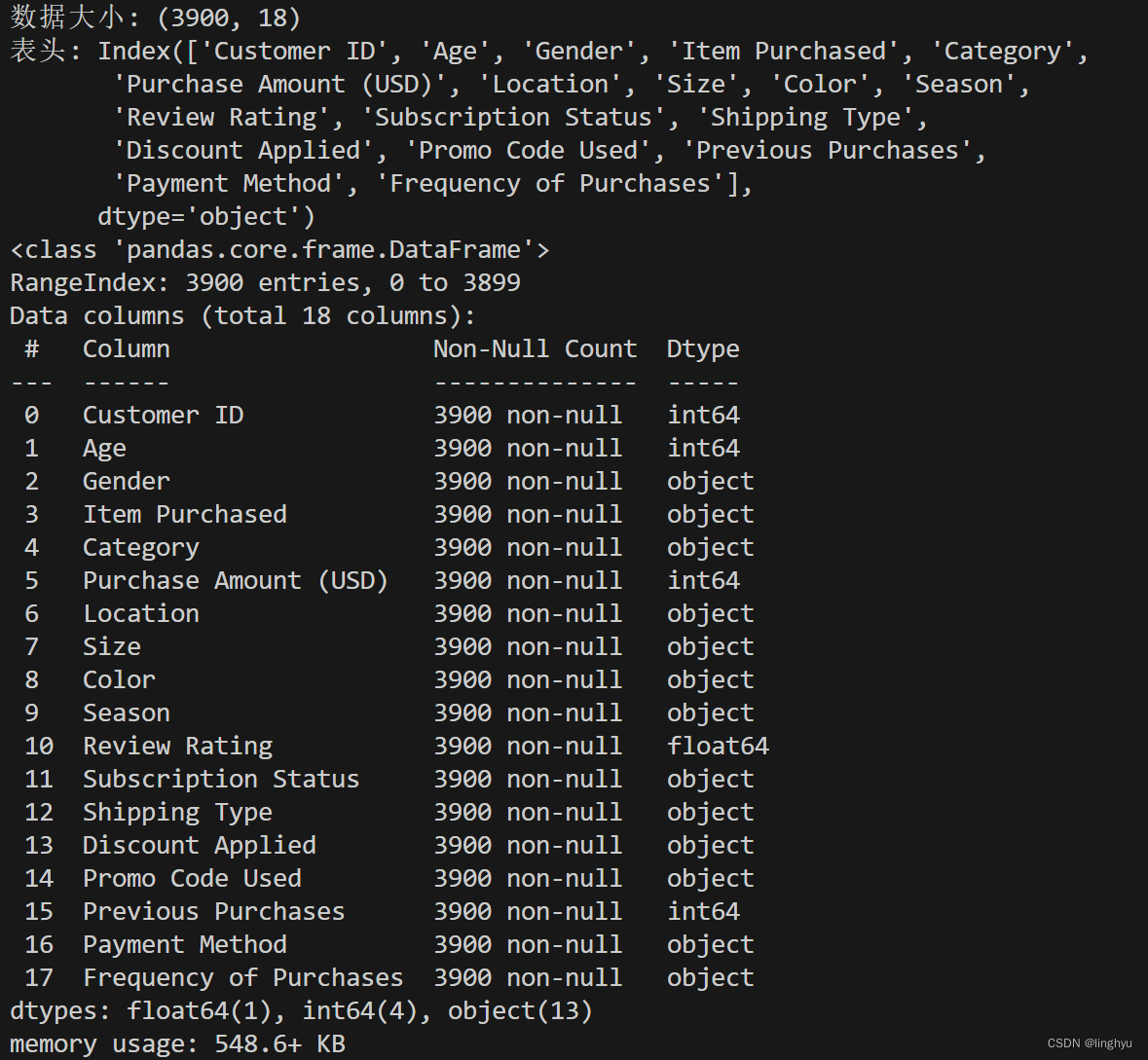
print('数据大小:', df.shape)
print('表头:', df.columns)
print('数据信息:', df.info())
print(df.apply(lambda col: col.unique()))
df.nunique()
df.isnull().sum()首先使用head()方法打印数据集的前5行数据,使用tail()方法打印数据集的后5行数据,使用shape属性打印数据集的大小,使用columns属性打印数据集的表头,使用info()方法打印数据集的信息。
然后,使用apply()方法对每个列应用一个匿名函数,该函数返回该列的唯一值。这将让我们看到每个列的唯一值。接着,使用nunique()方法计算每个列的唯一值的数量。最后,使用isnull()方法检查数据集中的缺失值,并打印结果。
结果如下:

5. 数据分析及处理
(1)以地点Location进行分组处理:
value=len(df[df.duplicated()])
print("数据集重复数据:\n",value)
df.describe().T
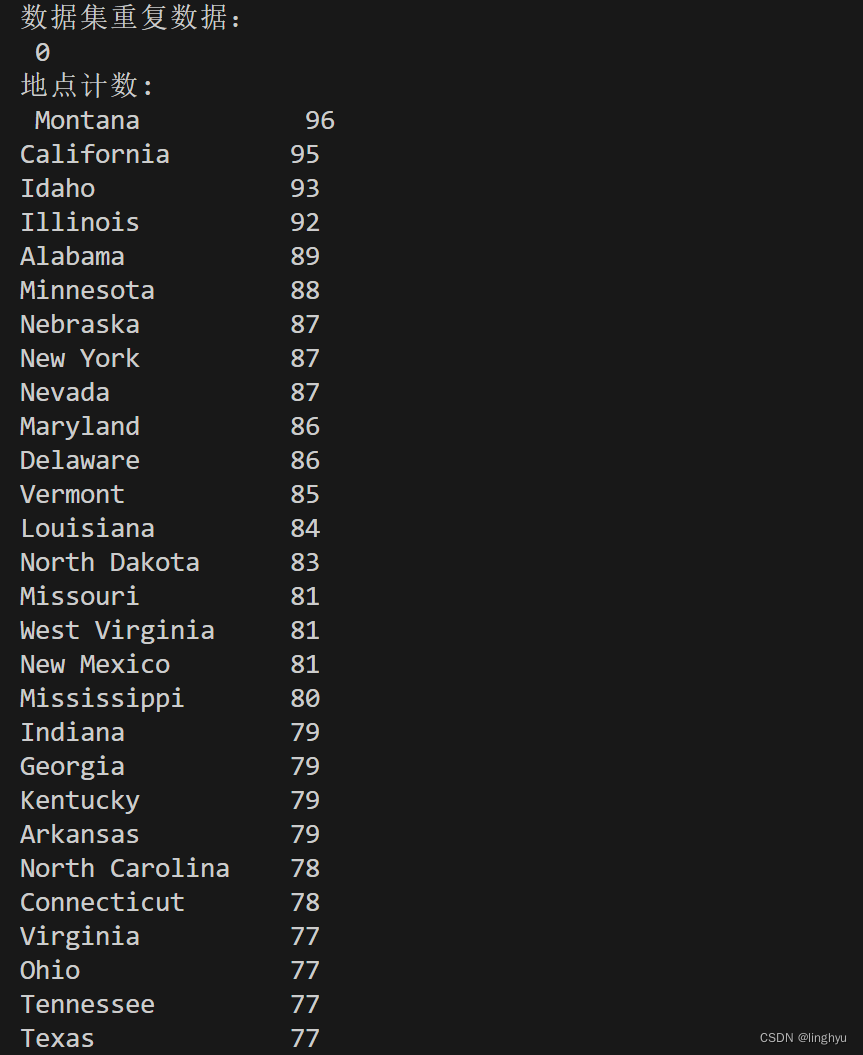
location_counts = df["Location"].value_counts()
print("地点计数:\n", location_counts)
category_counts = df.groupby("Location")["Category"].valu
e_counts()
print("类别频率:\n", category_counts)
location_purchase_stats = df.groupby("Location")["Purchase Amount (USD)"].agg(["mean", "median", "sum"])
print("购买金额统计信息:\n", location_purchase_stats)
shipping_type_counts = df.groupby("Location")["Shipping Type"].value_counts()
print("物流方式频率:\n", shipping_type_counts)
location_groups = df.groupby("Location")执行结果:


对df的进行数据分析和处理。首先,检查df中是否有重复的行。如果存在重复行,则将重复行的数量存储在value变量中,然后打印出来。
接下来,使用describe()方法对df进行描述,包括列的名称、数据类型、平均值、标准差、最小值和最大值等信息。T表示将结果的行和列交换。使用value_counts()方法对df["Location"]列进行值计数,并打印结果。这将显示每个位置的频率。
使用groupby()方法对df按照Location列进行分组,然后使用value_counts()方法对Category列进行值计数。这将显示每个位置的每个类别(Category)的频率。
使用groupby()方法对df按照Location列进行分组,然后使用agg()方法对Purchase Amount (USD)列进行聚合操作,包括计算平均值、中位数和求和。这将显示每个位置的购买金额统计信息。
使用groupby()方法对df按照Location列进行分组,然后使用value_counts()方法对Shipping Type列进行值计数。这将显示每个位置的物流方式(Shipping Type)的频率。
使用groupby()方法对df按照Location列进行分组,这将返回一个GroupBy对象,可以进一步进行分组聚合操作。
(2)分析区域趋势
for location, location_data in location_groups:
??? print(f"{location}区域趋势: ")
??? # 计算该地区的平均购买量
??? avg_purchase_amount = location_data["Purchase Amount (USD)"].mean()
??? print(f"平均购买金额:${avg_purchase_amount:.2f}")
??? # 统计一下该地区最受欢迎的产品类别
??? popular_categories = location_data["Category"].value_counts().idxmax()
??? print(f"最受欢迎类别: {popular_categories}")
??? # 分析网上购物偏好
??? online_shopping = location_data["Shipping Type"].apply(lambda x: "Online" if "Express" in x or "Standard" in x else "Offline")
??? online_percentage = (online_shopping.value_counts() / len(online_shopping)) * 100
??? print(f"网上购物偏好:")
??? print(online_percentage)
??? print("\n")创建一个location_groups迭代器,其中每个元素是一个元组,包含Location和Location_data两个部分。for循环遍历每个元组,使用`mean()`方法计算该地区的平均购买量,并将结果存储在avg_purchase_amount变量中。使用str.format()将结果格式化,并打印。
使用value_counts()方法统计该地区最受欢迎的产品类别,并将结果存储在变量中。同样结果格式,并打印。
创建一个名为online_shopping的新列,其中包含该地区用户的购物方式。使用apply()方法将Shipping Type列的值应用一个匿名函数,该函数检查值是否包含"Express"或"Standard",如果是,则将其转换为"Online",否则转换为"Offline"。之后计算online_shopping列中每个值的出现次数,然后除以总行数,以获得百分比。将结果存储在online_percentage变量中。使用apply()方法将结果转换为百分比,然后使用value_counts()方法计算每个值的出现次数,最后使用apply()方法将结果转换为百分比。
打印出在线购物偏好,即online_percentage变量的结果。
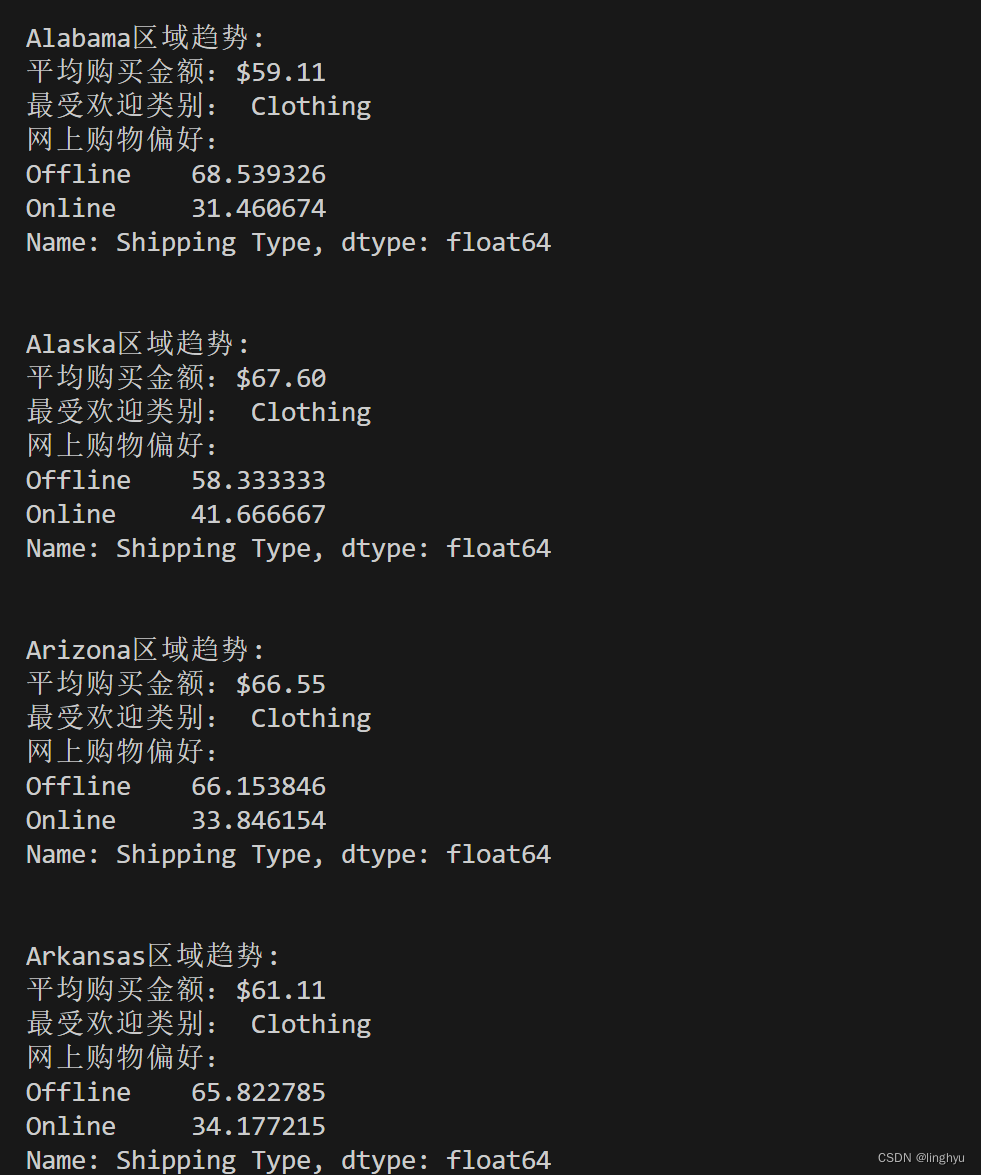
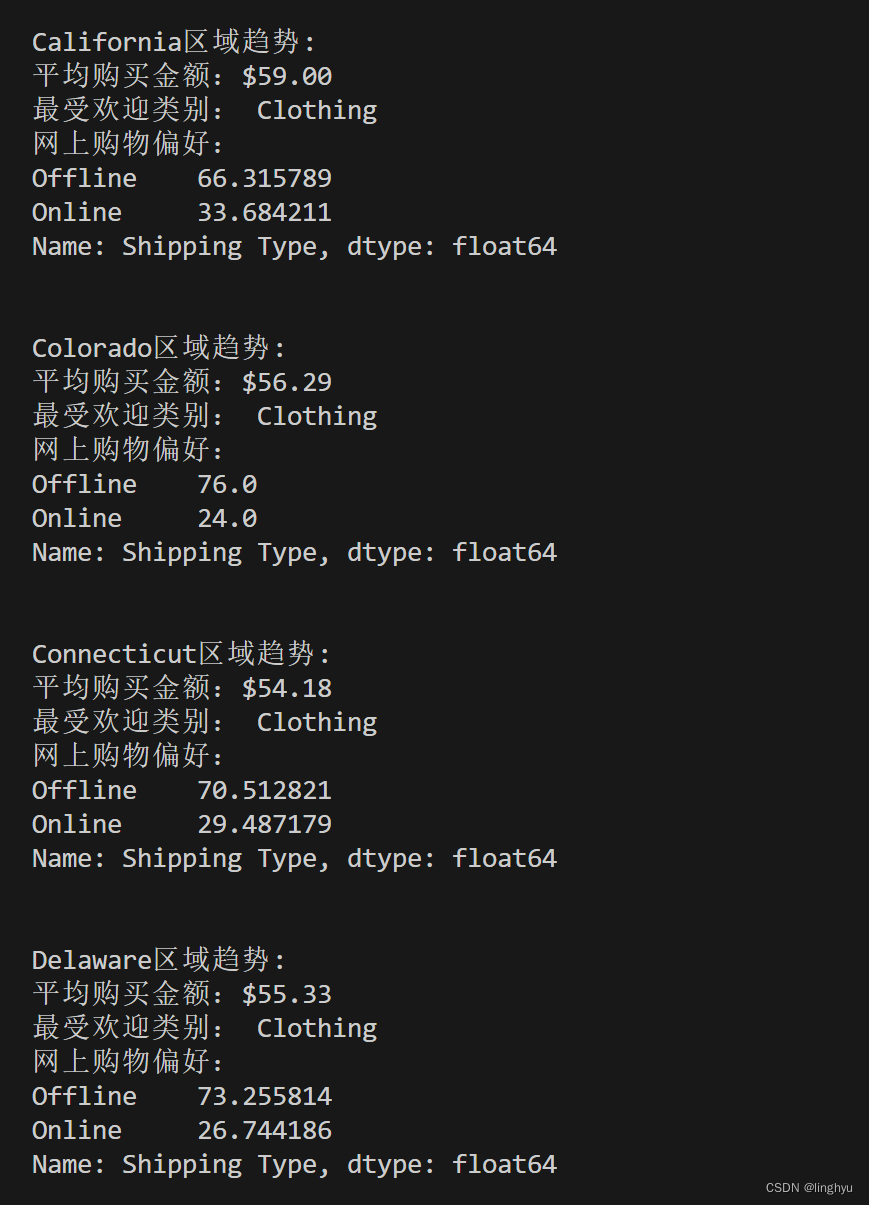 ?
?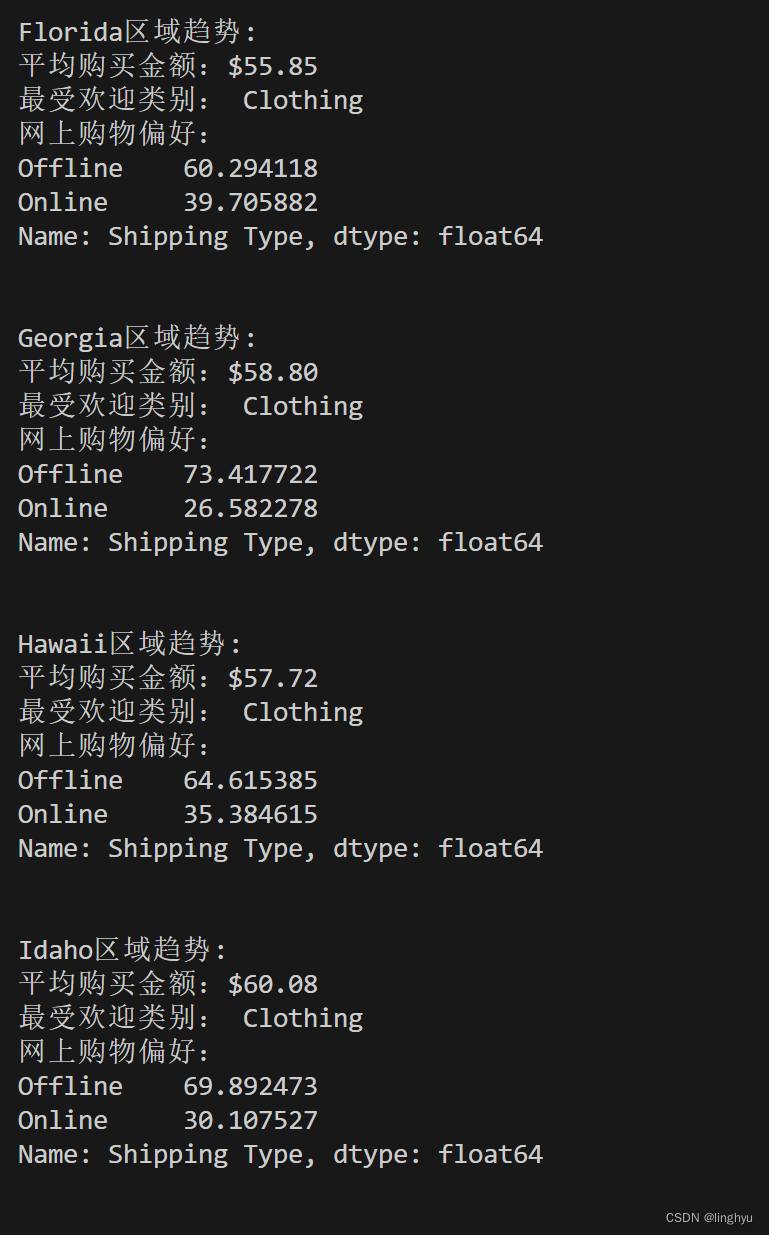 ?
?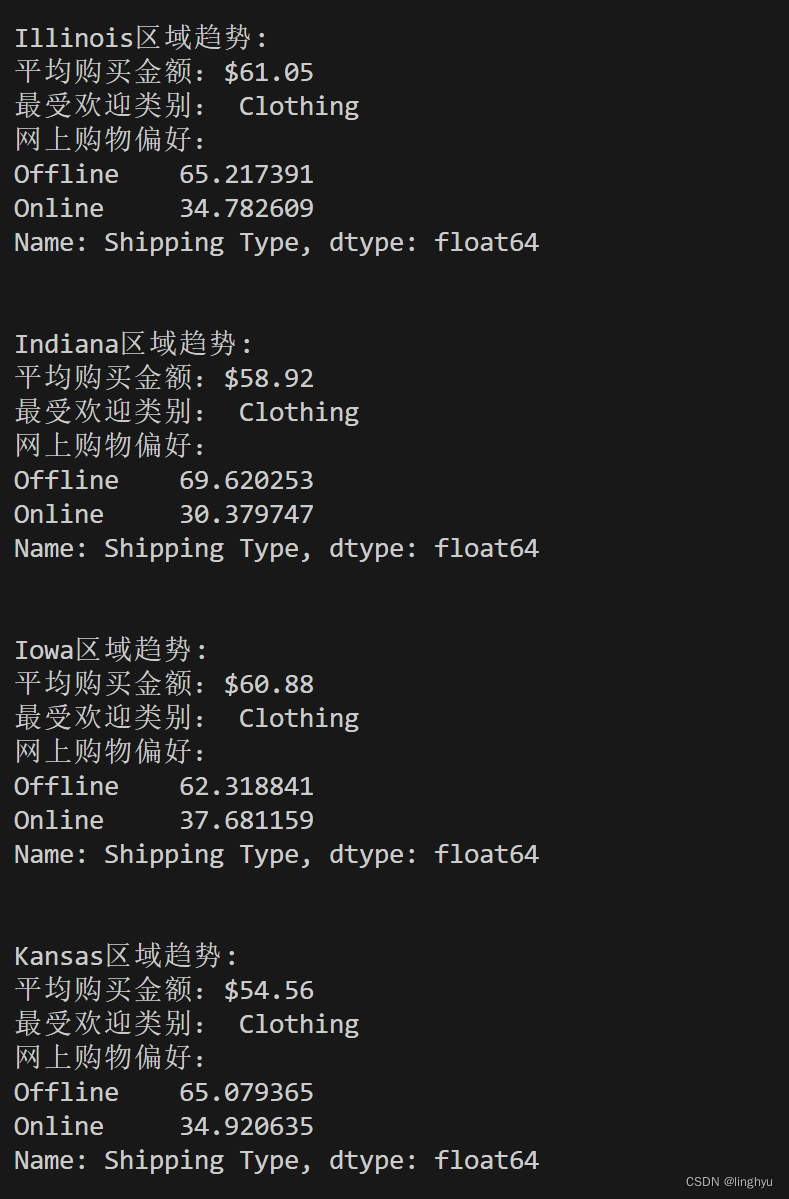
从结果上我们可以看到,在阿拉斯加,购物者对服装表现出强烈的偏好,平均支出为67美元,在服装类别中是最高的。这表明他们对质量和风格有明显的偏好,反映了阿拉斯加独特的消费者行为和市场趋势。
6. 数据可视化
我们可以通过可视化来看看各种因素的影响,比如季节性,商品属性(尺寸和颜色)和促销活动(折扣和促销代码)对客户购买决策的影响。
(1)季节对购买的影响
图表如下所示:
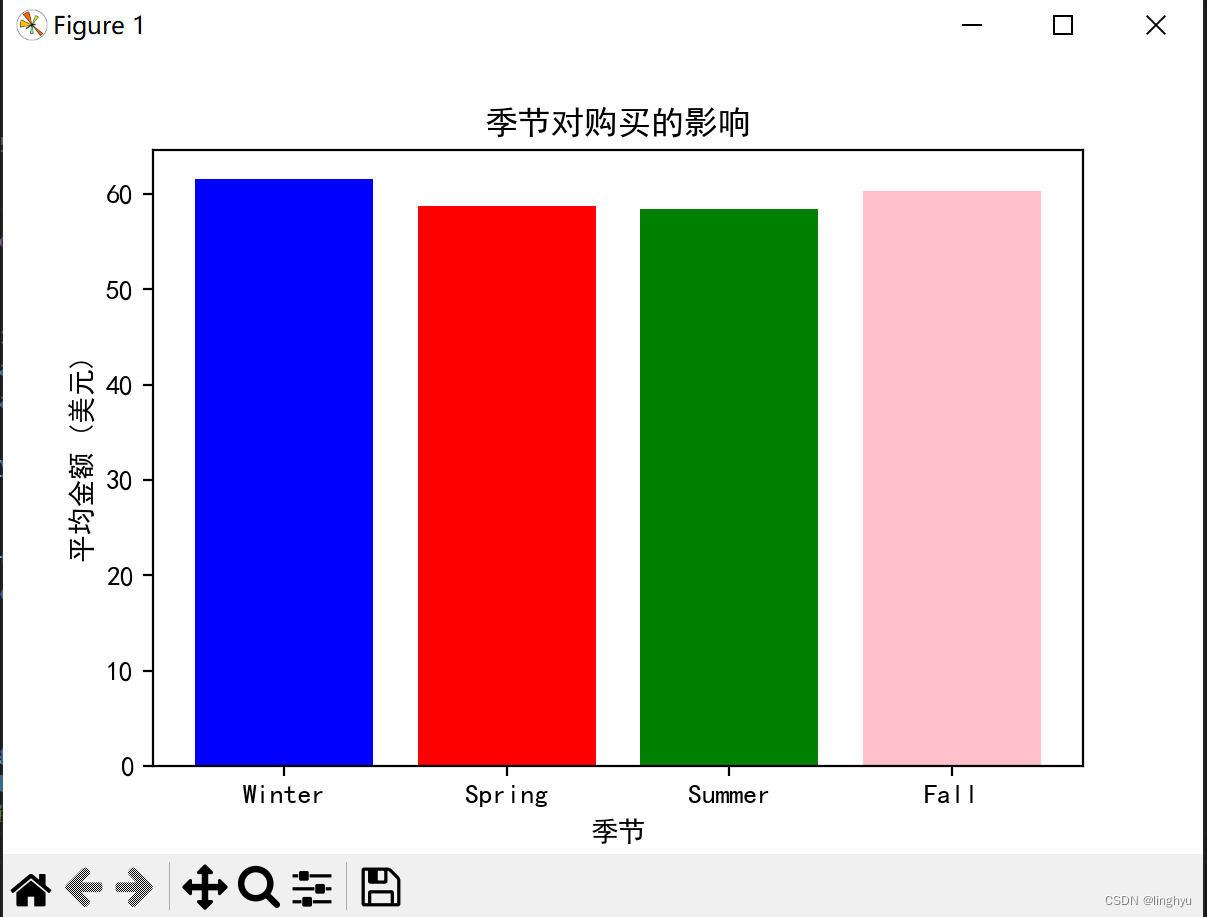
从视觉上我们可以看出,消费者在冬季和秋季的购买量比春季和夏季的购买量要多,但差距并不明显。
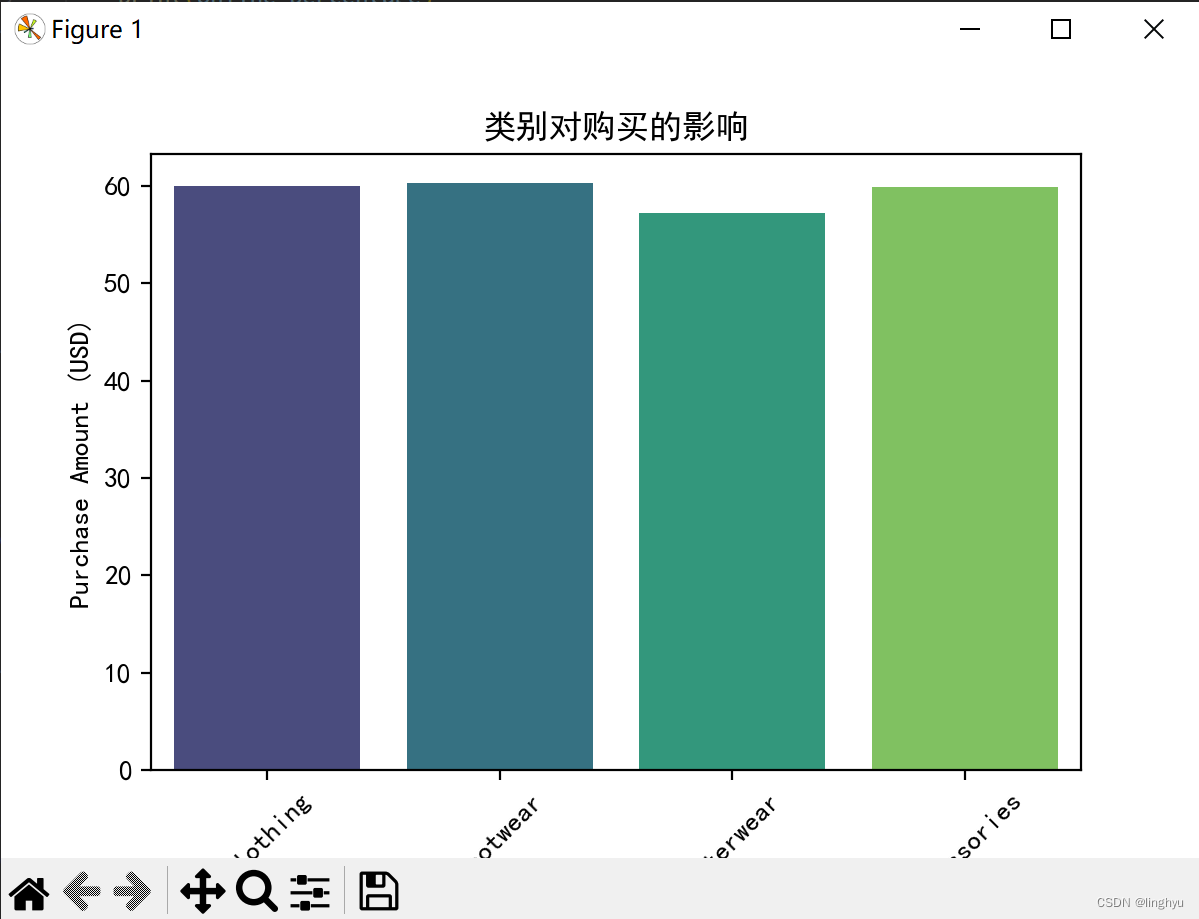
(2)类别对购买的影响
图表显示,外套类别比其他类别略低:
(3)性别对购买的影响

饼图如下所示:

从饼图中我们可以得知相比之下,男性更愿意花钱(67%),而女性更不愿意花钱(32%)。
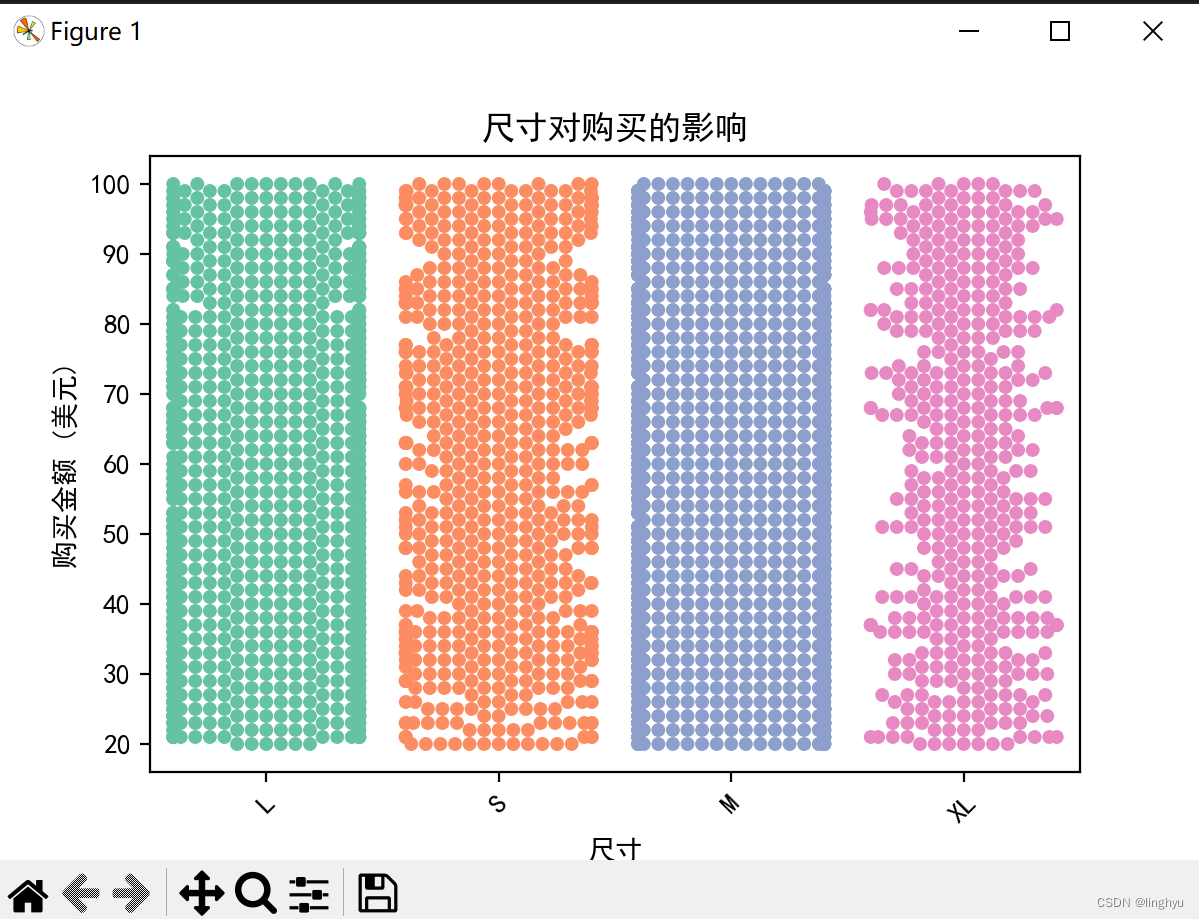
(4)尺寸对购买的影响

如图所示,小号、加大号的购买量低于大号和中号的购买量。
(5)产品类别分布
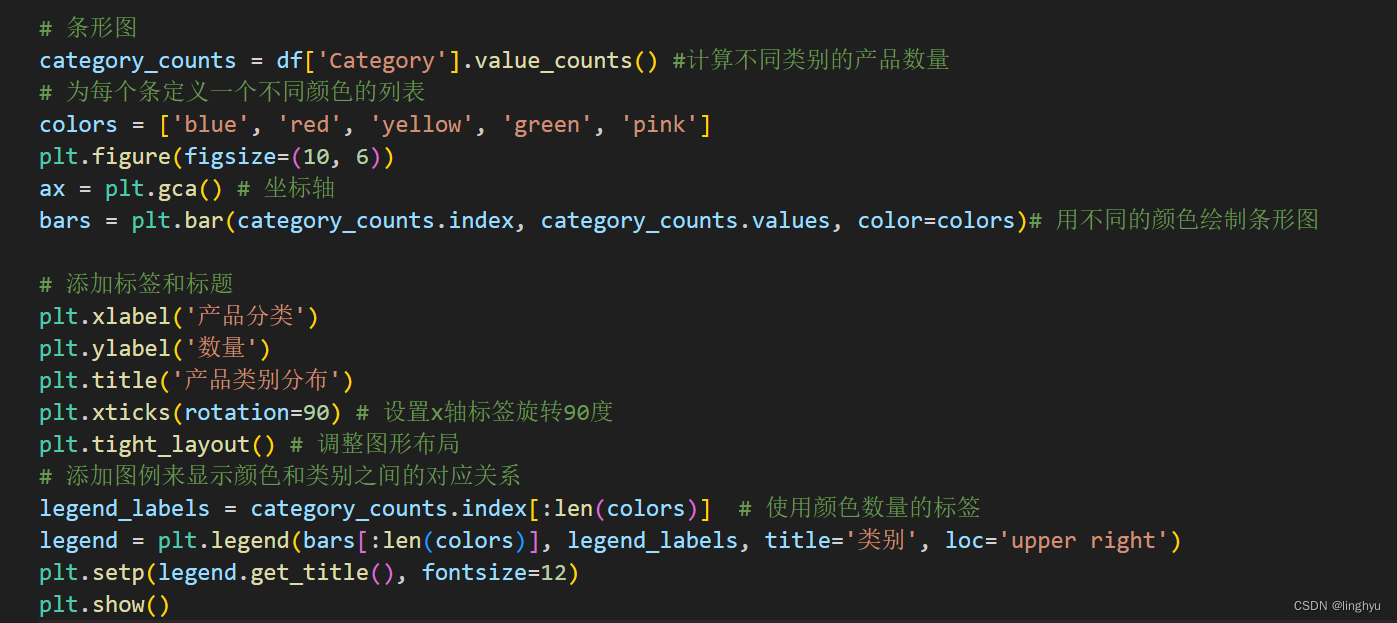
如下图所示:

可以看到,服装类是最受消费者欢迎的。
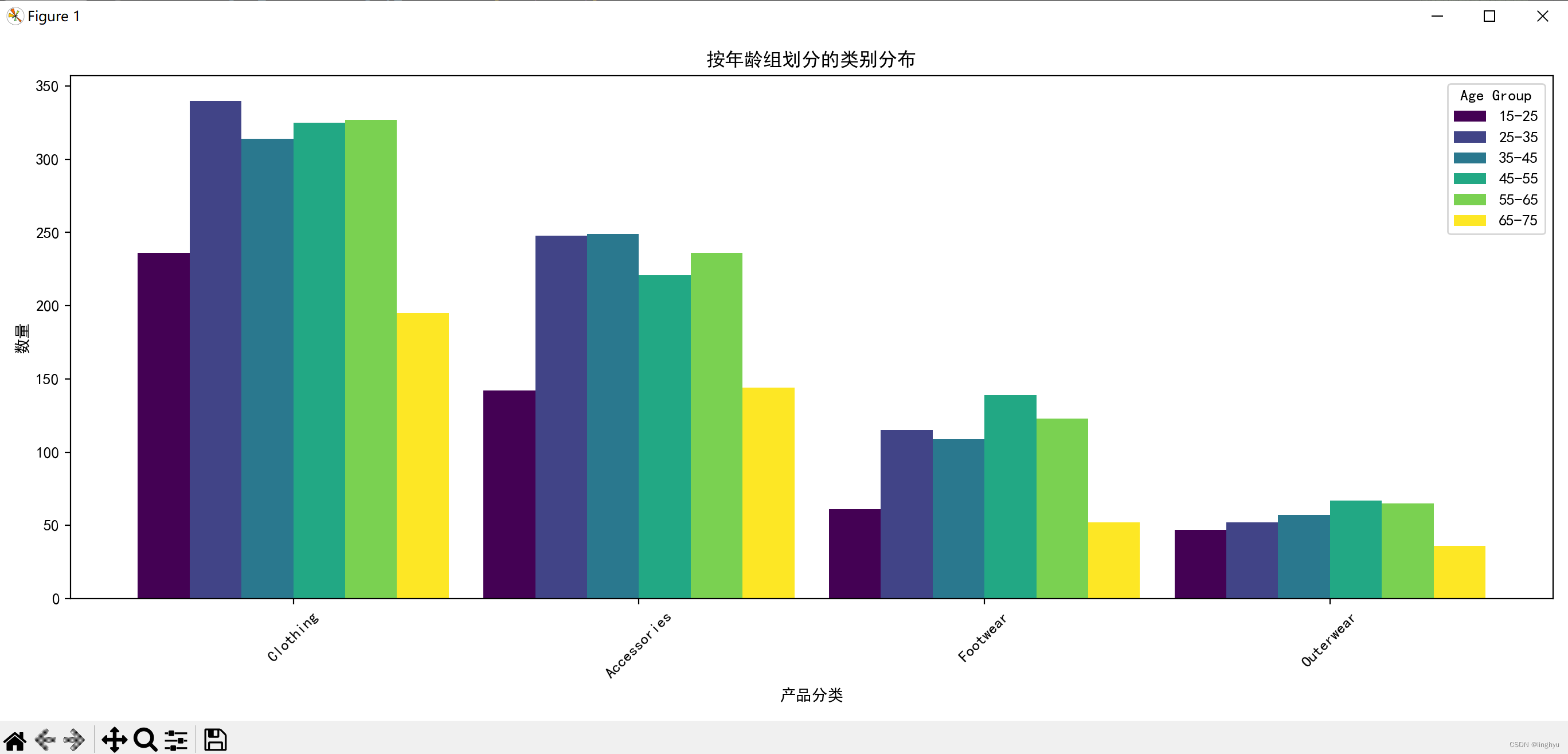
(6)不同年龄的类别分布情况

可以从图表看出年龄分布在各类产品中都呈现两边低中间高的情况,即15~25和65~75的人们相比之下比较少购物。
正如我们所看到的,服装是所有年龄组中最受欢迎的类别。
除了15-25岁和65-75岁年龄段外,所有年龄段的配饰都居多。然而,我们已经看到,在鞋类类别中,45-55岁年龄组的人最多。外套在所有年龄组中几乎同样多。
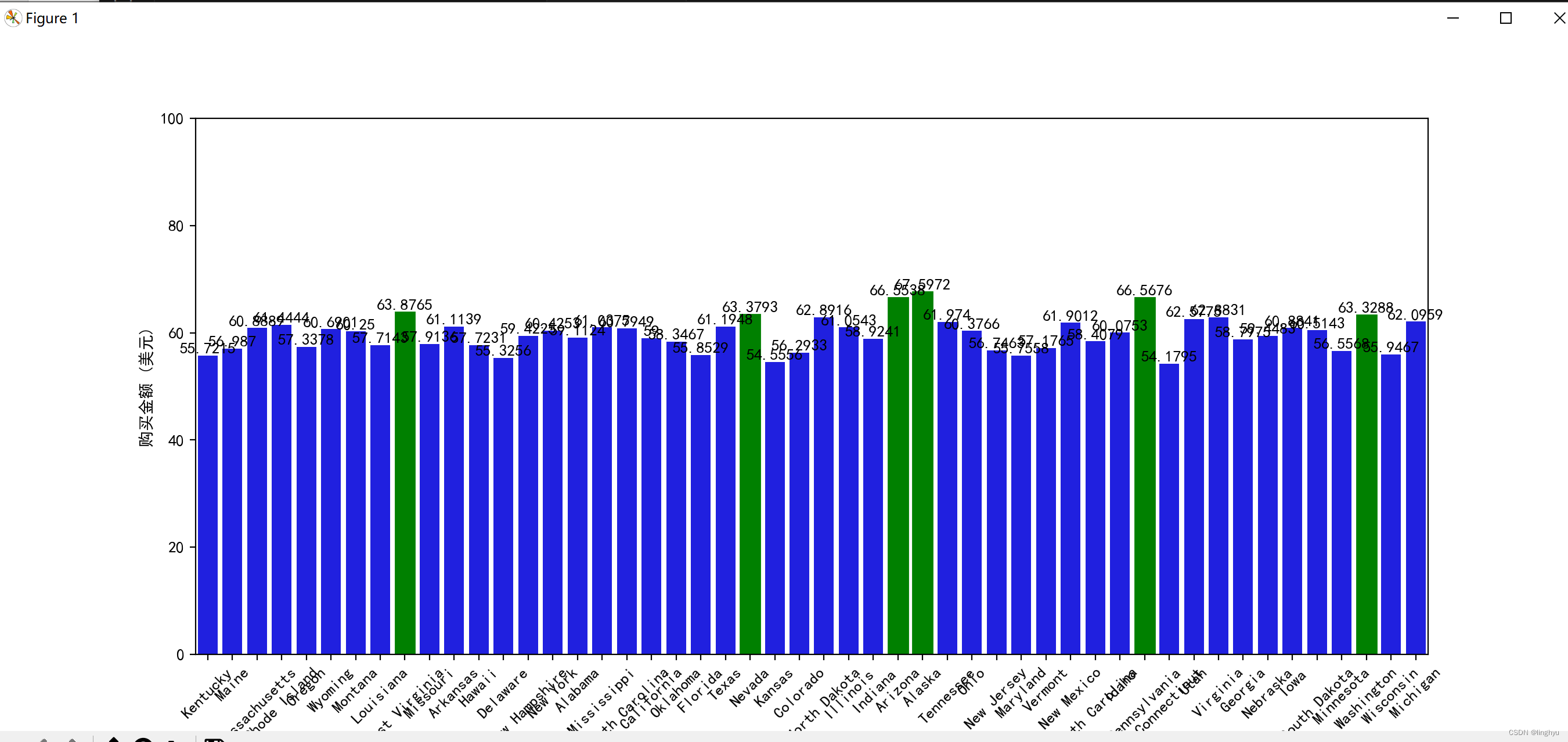
(7)不同地理位置的购买金额分布
使用seaborn库的barplot函数绘制柱状图,其中x轴表示地理位置,y轴表示购买金额,errorbar参数设置为None表示不显示误差条,颜色设置为蓝色。

执行图表如下:
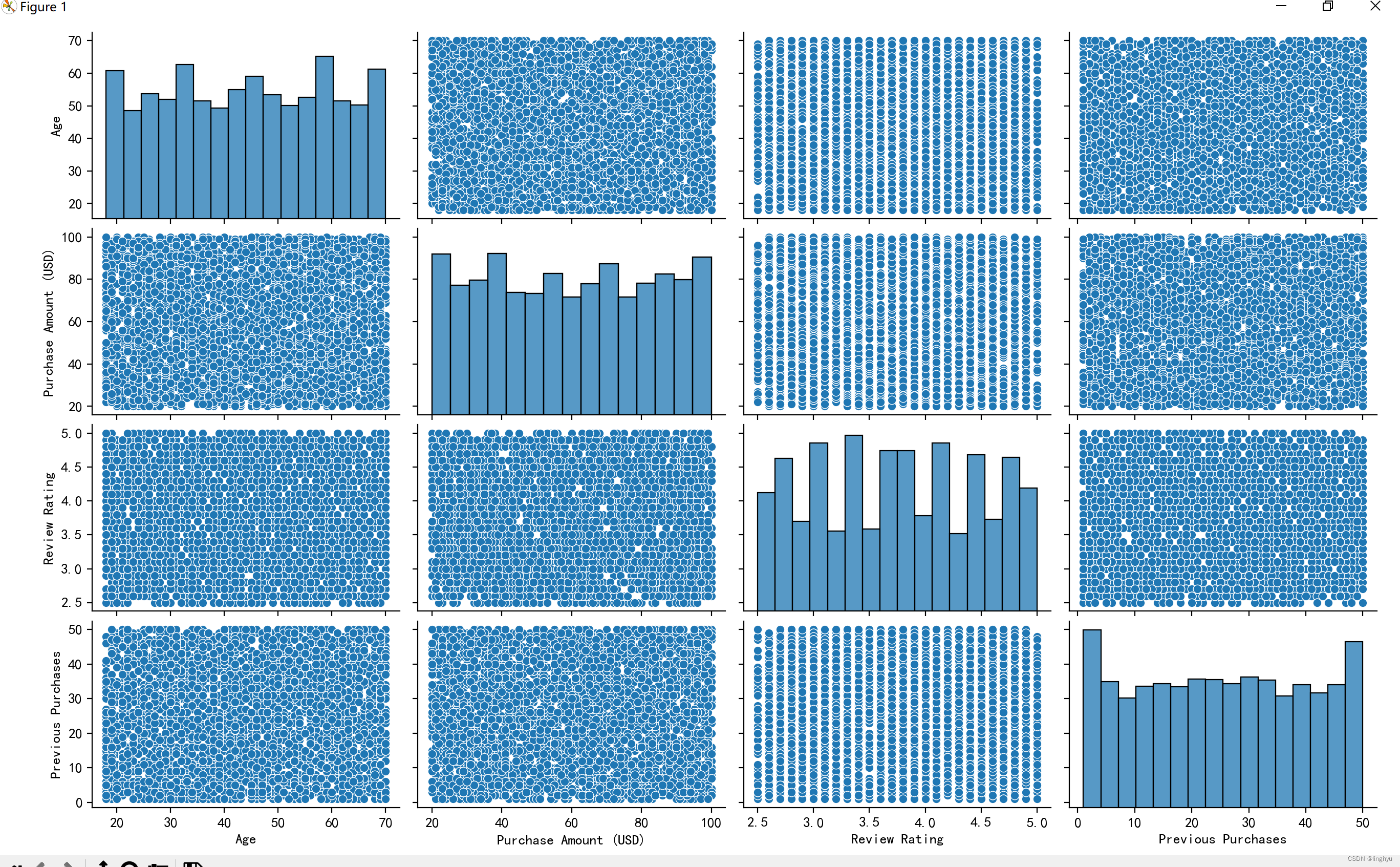
(8)购买金额(美元)与各种变量
购买金额(美元)与其他变量的可视化,以了解它们之间的关系
使用SNS库的pairplot函数绘制数据集中变量之间的相关性图。该函数会自动计算每个变量之间的皮尔逊相关系数,并将它们显示在图中。
执行图表如下:
7. 异常处理
运行绘画可视化图形时,遇到了异常问题:
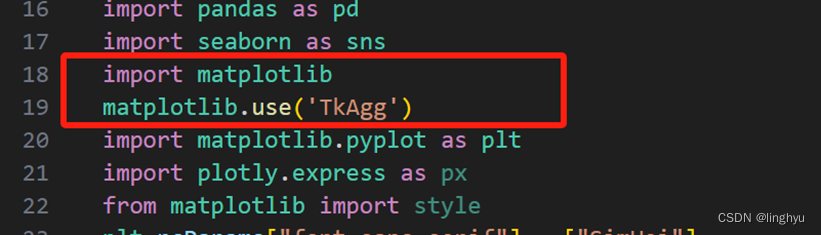
UserWarning: Matplotlib is currently using agg, which is a non-GUI backend
经过检索解决方法发现,agg是一个没有图形显示界面的终端,常用的有图形界面显示的终端有TkAgg等。如下图

找到import matplotlib.pyplot as plt,在这句话前加上两句指定显示终端使用TkAgg,如下:
结果
与春夏相比,消费者往往在冬季和秋季购买更多的东西。
与其他品类相比,外衣品类的购买量略低,这表明有可能改进的领域。
男性占总消费的67%,而女性占32%。
与大号、小号和中号等其他尺码相比,超大号的购买量更低。
服装是所有消费者中最受欢迎的产品类别。
除了15-25岁和65-75岁的人群外,配饰在各个年龄段都同样受欢迎。
鞋类在45-55岁年龄组中特别受欢迎。
外套在所有年龄组中都很受欢迎。
总结
对顾客行为和购买数据的分析揭示了一些有价值的见解。季节变化、产品类别、性别、尺寸和促销码的使用都会影响消费者的购买决策。数据还表明,蒙大拿州拥有强大的消费市场,服装是各个年龄段的首选产品类别。这些发现可以为营销策略、产品供应和促销提供信息,以更好地瞄准和服务不同的客户群。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!