YOLOv8改进 更换多层池化操作主干网络PoolFormer

一、多层池化操作主干网络PoolFormer论文

论文地址:2111.11418.pdf (arxiv.org)
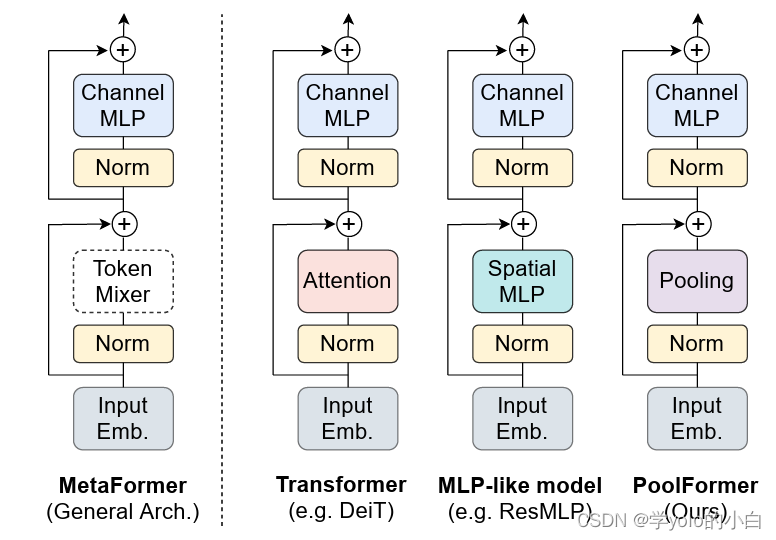
二、PoolFormer的网络结构
PoolFormer采用自注意力机制和池化操作相结合的方式,同时考虑了局部和全局的特征关系。
PoolFormer的网络结构包括以下几个主要组件:
-
输入特征图(Input Feature Map):PoolFormer的输入是一个特征图,它可以是一个图像或其他形式的特征表示。输入特征图包含了原始数据的信息。
-
编码器(Encoder):编码器是PoolFormer的核心组件,用于提取特征并学习特征表示。编码器采用了自注意力机制,通过自注意力头(Self-Attention Heads)对输入特征图进行多尺度的特征提取。自注意力机制能够自动学习输入特征图中不同位置之间的关系,从而捕捉到更丰富的特征信息。
-
位置编码器(Positional Encoder):位置编码器用于将输入特征图的位置信息嵌入到特征表示中。它可以是一个简单的线性映射,也可以是一个更复杂的非线性函数。位置编码器的作用是引入位置信息,使得特征表示具有空间上的连续性。
-
高级编码器(High-Level Encoder):高级编码器用于进一步提取输入特征图的高级语义信息。它可以是一个或多个卷积层,用于对编码器的输出进行细化和抽象。高级编码器的作用是提高特征表示的表达能力,使得模型能够更好地理解输入数据。
-
池化操作(Pooling Operation):PoolFormer还采用了池化操作,用于进一步减少特征图的尺寸和维度。池化操作可以是平均池化或最大池化,它通过对输入特征图的局部区域进行汇聚,得到特征图的下采样表示。池化操作的作用是降低特征图的维度,提高计算效率。
-
全局特征(Global Features):在PoolFormer中,全局特征指的是对整个输入特征图进行池化操作得到的特征表示。全局特征可以捕捉到整个输入的整体信息,对于图像分类等任务非常重要。
-
分类器(Classifier):分类器用于将池化操作得到的特征表示映射到类别概率分布。分类器可以是一个全连接层或其他类型的线性映射函数。它的作用是将深层特征映射为对应的类别概率,从而进行分类任务。
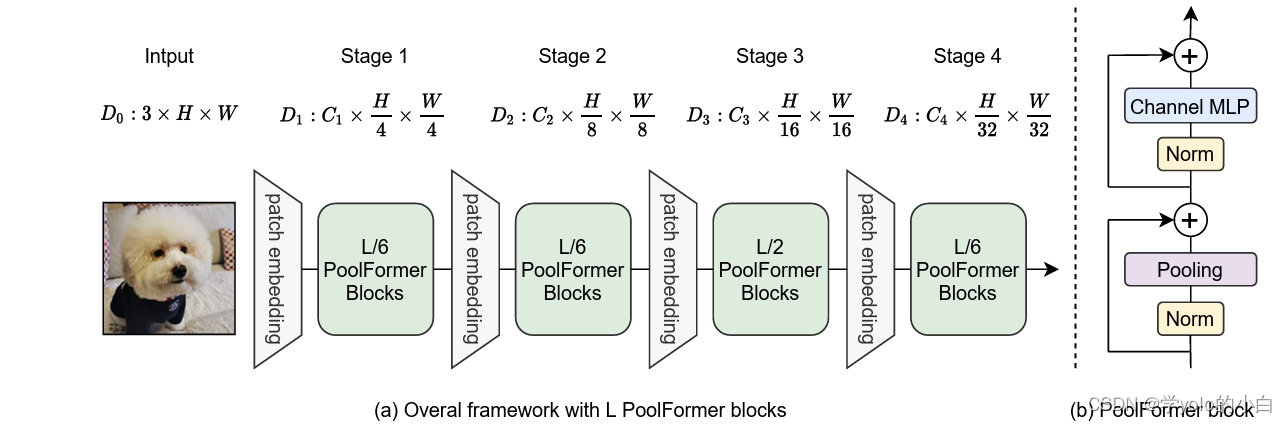
PoolFormer的优点包括模型复杂度低、计算速度快,特别适用于实时图像分割任务。此外,通过适当调整分块大小和池化操作的参数,PoolFormer还能够在不同的图像分辨率下保持较好的分割性能。?
三、代码实现
1、在ultralytics\ultralytics\nn路径下新建一个文件夹命名为backbone,用于存放网络结构修改的代码。
并在该?backbone文件夹路径下新建py文件PoolFormer.py,并在该文件里添加PoolFormer网络结构的代码:
"""
PoolFormer implementation
"""
import os
import copy
import torch
import torch.nn as nn
import numpy as np
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.layers import DropPath, trunc_normal_, to_2tuple
from timm.models.registry import register_model
__all__ = ['poolformer_s12', 'poolformer_s24', 'poolformer_s36', 'poolformer_m48', 'poolformer_m36']
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'pool_size': None,
'crop_pct': .95, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'classifier': 'head',
**kwargs
}
default_cfgs = {
'poolformer_s': _cfg(crop_pct=0.9),
'poolformer_m': _cfg(crop_pct=0.95),
}
class PatchEmbed(nn.Module):
"""
Patch Embedding that is implemented by a layer of conv.
Input: tensor in shape [B, C, H, W]
Output: tensor in shape [B, C, H/stride, W/stride]
"""
def __init__(self, patch_size=16, stride=16, padding=0,
in_chans=3, embed_dim=768, norm_layer=None):
super().__init__()
patch_size = to_2tuple(patch_size)
stride = to_2tuple(stride)
padding = to_2tuple(padding)
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size,
stride=stride, padding=padding)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
x = self.proj(x)
x = self.norm(x)
return x
class LayerNormChannel(nn.Module):
"""
LayerNorm only for Channel Dimension.
Input: tensor in shape [B, C, H, W]
"""
def __init__(self, num_channels, eps=1e-05):
super().__init__()
self.weight = nn.Parameter(torch.ones(num_channels))
self.bias = nn.Parameter(torch.zeros(num_channels))
self.eps = eps
def forward(self, x):
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight.unsqueeze(-1).unsqueeze(-1) * x \
+ self.bias.unsqueeze(-1).unsqueeze(-1)
return x
class GroupNorm(nn.GroupNorm):
"""
Group Normalization with 1 group.
Input: tensor in shape [B, C, H, W]
"""
def __init__(self, num_channels, **kwargs):
super().__init__(1, num_channels, **kwargs)
class Pooling(nn.Module):
"""
Implementation of pooling for PoolFormer
--pool_size: pooling size
"""
def __init__(self, pool_size=3):
super().__init__()
self.pool = nn.AvgPool2d(
pool_size, stride=1, padding=pool_size//2, count_include_pad=False)
def forward(self, x):
return self.pool(x) - x
class Mlp(nn.Module):
"""
Implementation of MLP with 1*1 convolutions.
Input: tensor with shape [B, C, H, W]
"""
def __init__(self, in_features, hidden_features=None,
out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Conv2d(in_features, hidden_features, 1)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, 1)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Conv2d):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class PoolFormerBlock(nn.Module):
"""
Implementation of one PoolFormer block.
--dim: embedding dim
--pool_size: pooling size
--mlp_ratio: mlp expansion ratio
--act_layer: activation
--norm_layer: normalization
--drop: dropout rate
--drop path: Stochastic Depth,
refer to https://arxiv.org/abs/1603.09382
--use_layer_scale, --layer_scale_init_value: LayerScale,
refer to https://arxiv.org/abs/2103.17239
"""
def __init__(self, dim, pool_size=3, mlp_ratio=4.,
act_layer=nn.GELU, norm_layer=GroupNorm,
drop=0., drop_path=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
super().__init__()
self.norm1 = norm_layer(dim)
self.token_mixer = Pooling(pool_size=pool_size)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
# The following two techniques are useful to train deep PoolFormers.
self.drop_path = DropPath(drop_path) if drop_path > 0. \
else nn.Identity()
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(
self.layer_scale_1.unsqueeze(-1).unsqueeze(-1)
* self.token_mixer(self.norm1(x)))
x = x + self.drop_path(
self.layer_scale_2.unsqueeze(-1).unsqueeze(-1)
* self.mlp(self.norm2(x)))
else:
x = x + self.drop_path(self.token_mixer(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def basic_blocks(dim, index, layers,
pool_size=3, mlp_ratio=4.,
act_layer=nn.GELU, norm_layer=GroupNorm,
drop_rate=.0, drop_path_rate=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
"""
generate PoolFormer blocks for a stage
return: PoolFormer blocks
"""
blocks = []
for block_idx in range(layers[index]):
block_dpr = drop_path_rate * (
block_idx + sum(layers[:index])) / (sum(layers) - 1)
blocks.append(PoolFormerBlock(
dim, pool_size=pool_size, mlp_ratio=mlp_ratio,
act_layer=act_layer, norm_layer=norm_layer,
drop=drop_rate, drop_path=block_dpr,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value,
))
blocks = nn.Sequential(*blocks)
return blocks
class PoolFormer(nn.Module):
"""
PoolFormer, the main class of our model
--layers: [x,x,x,x], number of blocks for the 4 stages
--embed_dims, --mlp_ratios, --pool_size: the embedding dims, mlp ratios and
pooling size for the 4 stages
--downsamples: flags to apply downsampling or not
--norm_layer, --act_layer: define the types of normalization and activation
--num_classes: number of classes for the image classification
--in_patch_size, --in_stride, --in_pad: specify the patch embedding
for the input image
--down_patch_size --down_stride --down_pad:
specify the downsample (patch embed.)
--fork_feat: whether output features of the 4 stages, for dense prediction
--init_cfg, --pretrained:
for mmdetection and mmsegmentation to load pretrained weights
"""
def __init__(self, layers, embed_dims=None,
mlp_ratios=None, downsamples=None,
pool_size=3,
norm_layer=GroupNorm, act_layer=nn.GELU,
num_classes=1000,
in_patch_size=7, in_stride=4, in_pad=2,
down_patch_size=3, down_stride=2, down_pad=1,
drop_rate=0., drop_path_rate=0.,
use_layer_scale=True, layer_scale_init_value=1e-5,
fork_feat=True,
init_cfg=None,
pretrained=None,
**kwargs):
super().__init__()
if not fork_feat:
self.num_classes = num_classes
self.fork_feat = fork_feat
self.patch_embed = PatchEmbed(
patch_size=in_patch_size, stride=in_stride, padding=in_pad,
in_chans=3, embed_dim=embed_dims[0])
# set the main block in network
network = []
for i in range(len(layers)):
stage = basic_blocks(embed_dims[i], i, layers,
pool_size=pool_size, mlp_ratio=mlp_ratios[i],
act_layer=act_layer, norm_layer=norm_layer,
drop_rate=drop_rate,
drop_path_rate=drop_path_rate,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value)
network.append(stage)
if i >= len(layers) - 1:
break
if downsamples[i] or embed_dims[i] != embed_dims[i+1]:
# downsampling between two stages
network.append(
PatchEmbed(
patch_size=down_patch_size, stride=down_stride,
padding=down_pad,
in_chans=embed_dims[i], embed_dim=embed_dims[i+1]
)
)
self.network = nn.ModuleList(network)
if self.fork_feat:
# add a norm layer for each output
self.out_indices = [0, 2, 4, 6]
for i_emb, i_layer in enumerate(self.out_indices):
if i_emb == 0 and os.environ.get('FORK_LAST3', None):
# TODO: more elegant way
"""For RetinaNet, `start_level=1`. The first norm layer will not used.
cmd: `FORK_LAST3=1 python -m torch.distributed.launch ...`
"""
layer = nn.Identity()
else:
layer = norm_layer(embed_dims[i_emb])
layer_name = f'norm{i_layer}'
self.add_module(layer_name, layer)
else:
# Classifier head
self.norm = norm_layer(embed_dims[-1])
self.head = nn.Linear(
embed_dims[-1], num_classes) if num_classes > 0 \
else nn.Identity()
self.init_cfg = copy.deepcopy(init_cfg)
self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 224, 224))]
def reset_classifier(self, num_classes):
self.num_classes = num_classes
self.head = nn.Linear(
self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_embeddings(self, x):
x = self.patch_embed(x)
return x
def forward_tokens(self, x):
outs = []
for idx, block in enumerate(self.network):
x = block(x)
if self.fork_feat and idx in self.out_indices:
norm_layer = getattr(self, f'norm{idx}')
x_out = norm_layer(x)
outs.append(x_out)
return outs
def forward(self, x):
# input embedding
x = self.forward_embeddings(x)
# through backbone
x = self.forward_tokens(x)
return x
model_urls = {
"poolformer_s12": "https://github.com/sail-sg/poolformer/releases/download/v1.0/poolformer_s12.pth.tar",
"poolformer_s24": "https://github.com/sail-sg/poolformer/releases/download/v1.0/poolformer_s24.pth.tar",
"poolformer_s36": "https://github.com/sail-sg/poolformer/releases/download/v1.0/poolformer_s36.pth.tar",
"poolformer_m36": "https://github.com/sail-sg/poolformer/releases/download/v1.0/poolformer_m36.pth.tar",
"poolformer_m48": "https://github.com/sail-sg/poolformer/releases/download/v1.0/poolformer_m48.pth.tar",
}
def update_weight(model_dict, weight_dict):
idx, temp_dict = 0, {}
for k, v in weight_dict.items():
if k in model_dict.keys() and np.shape(model_dict[k]) == np.shape(v):
temp_dict[k] = v
idx += 1
model_dict.update(temp_dict)
print(f'loading weights... {idx}/{len(model_dict)} items')
return model_dict
def poolformer_s12(pretrained=False, **kwargs):
"""
PoolFormer-S12 model, Params: 12M
--layers: [x,x,x,x], numbers of layers for the four stages
--embed_dims, --mlp_ratios:
embedding dims and mlp ratios for the four stages
--downsamples: flags to apply downsampling or not in four blocks
"""
layers = [2, 2, 6, 2]
embed_dims = [64, 128, 320, 512]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
model = PoolFormer(
layers, embed_dims=embed_dims,
mlp_ratios=mlp_ratios, downsamples=downsamples,
**kwargs)
model.default_cfg = default_cfgs['poolformer_s']
if pretrained:
url = model_urls['poolformer_s12']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(update_weight(model.state_dict(), checkpoint))
return model
def poolformer_s24(pretrained=False, **kwargs):
"""
PoolFormer-S24 model, Params: 21M
"""
layers = [4, 4, 12, 4]
embed_dims = [64, 128, 320, 512]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
model = PoolFormer(
layers, embed_dims=embed_dims,
mlp_ratios=mlp_ratios, downsamples=downsamples,
**kwargs)
model.default_cfg = default_cfgs['poolformer_s']
if pretrained:
url = model_urls['poolformer_s24']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(update_weight(model.state_dict(), checkpoint))
return model
def poolformer_s36(pretrained=False, **kwargs):
"""
PoolFormer-S36 model, Params: 31M
"""
layers = [6, 6, 18, 6]
embed_dims = [64, 128, 320, 512]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
model = PoolFormer(
layers, embed_dims=embed_dims,
mlp_ratios=mlp_ratios, downsamples=downsamples,
layer_scale_init_value=1e-6,
**kwargs)
model.default_cfg = default_cfgs['poolformer_s']
if pretrained:
url = model_urls['poolformer_s36']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(update_weight(model.state_dict(), checkpoint))
return model
def poolformer_m36(pretrained=False, **kwargs):
"""
PoolFormer-M36 model, Params: 56M
"""
layers = [6, 6, 18, 6]
embed_dims = [96, 192, 384, 768]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
model = PoolFormer(
layers, embed_dims=embed_dims,
mlp_ratios=mlp_ratios, downsamples=downsamples,
layer_scale_init_value=1e-6,
**kwargs)
model.default_cfg = default_cfgs['poolformer_m']
if pretrained:
url = model_urls['poolformer_m36']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(update_weight(model.state_dict(), checkpoint))
return model
@register_model
def poolformer_m48(pretrained=False, **kwargs):
"""
PoolFormer-M48 model, Params: 73M
"""
layers = [8, 8, 24, 8]
embed_dims = [96, 192, 384, 768]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
model = PoolFormer(
layers, embed_dims=embed_dims,
mlp_ratios=mlp_ratios, downsamples=downsamples,
layer_scale_init_value=1e-6,
**kwargs)
model.default_cfg = default_cfgs['poolformer_m']
if pretrained:
url = model_urls['poolformer_m48']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(update_weight(model.state_dict(), checkpoint))
return model
if __name__ == '__main__':
model = poolformer_s12(pretrained=True)
inputs = torch.randn((1, 3, 640, 640))
for i in model(inputs):
print(i.size())2、在ultralytics\ultralytics\nn\tasks.py文件中加入PoolFormer模块
开头先从新建的文件夹引入PoolFormer的包:
from ultralytics.nn.backbone.PoolFormer import *并且文件的def _predict_once函数模块要替换为更换网络结构后的预测模块:

替换为:
def _predict_once(self, x, profile=False, visualize=False):
"""
Perform a forward pass through the network.
Args:
x (torch.Tensor): The input tensor to the model.
profile (bool): Print the computation time of each layer if True, defaults to False.
visualize (bool): Save the feature maps of the model if True, defaults to False.
Returns:
(torch.Tensor): The last output of the model.
"""
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
if hasattr(m, 'backbone'):
x = m(x)
for _ in range(5 - len(x)):
x.insert(0, None)
for i_idx, i in enumerate(x):
if i_idx in self.save:
y.append(i)
else:
y.append(None)
# for i in x:
# if i is not None:
# print(i.size())
x = x[-1]
else:
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
return x然后在def parse_model函数模块中进行修改:
由于是更换yolov8原始的网路结构,所以需要在该parse_model函数模块中加入更改网络模块的代码,更改后完整的def parse_model模块代码为:
def parse_model(d, ch, verbose=True, warehouse_manager=None): # model_dict, input_channels(3)
"""Parse a YOLO model.yaml dictionary into a PyTorch model."""
import ast
# Args
max_channels = float('inf')
nc, act, scales = (d.get(x) for x in ('nc', 'activation', 'scales'))
depth, width, kpt_shape = (d.get(x, 1.0) for x in ('depth_multiple', 'width_multiple', 'kpt_shape'))
if scales:
scale = d.get('scale')
if not scale:
scale = tuple(scales.keys())[0]
LOGGER.warning(f"WARNING ?? no model scale passed. Assuming scale='{scale}'.")
depth, width, max_channels = scales[scale]
if act:
Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()
if verbose:
LOGGER.info(f"{colorstr('activation:')} {act}") # print
if verbose:
LOGGER.info(f"\n{'':>3}{'from':>20}{'n':>3}{'params':>10} {'module':<45}{'arguments':<30}")
ch = [ch]
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
is_backbone = False
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
try:
if m == 'node_mode':
m = d[m]
if len(args) > 0:
if args[0] == 'head_channel':
args[0] = int(d[args[0]])
t = m
m = getattr(torch.nn, m[3:]) if 'nn.' in m else globals()[m] # get module
except:
pass
for j, a in enumerate(args):
if isinstance(a, str):
with contextlib.suppress(ValueError):
try:
args[j] = locals()[a] if a in locals() else ast.literal_eval(a)
except:
args[j] = a
n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
if m in (Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, Focus,
BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, RepC3,
C2f_DBB,C2f_DySnakeConv):
if args[0] == 'head_channel':
args[0] = d[args[0]]
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]
if m in (
BottleneckCSP, C1, C2, C2f, C3, C3TR, C3Ghost, C3x, RepC3, C2f_DBB,C2f_DySnakeConv):
args.insert(2, n) # number of repeats
n = 1
elif m is AIFI:
args = [ch[f], *args]
##### 更换网络lsknet ####
elif m in {lsknet_s, lsknet_t}:
m = m(*args)
c2 = m.channel
elif m in (HGStem, HGBlock):
c1, cm, c2 = ch[f], args[0], args[1]
args = [c1, cm, c2, *args[2:]]
if m is HGBlock:
args.insert(4, n) # number of repeats
n = 1
elif m in {GAM_Attention}:
c1, c2 = ch[f], args[0]
if c2 != nc: # if not output
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]
elif m in {ShuffleAttention}:
c1, c2 = ch[f], args[0]
if c2 != nc: # if not output
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]
elif m in (
Detect, DetectAux, Pose,Detect_DyHead):
args.append([ch[x] for x in f])
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
elif m in (Detect, Segment, Pose):
args.append([ch[x] for x in f])
if m is Segment:
args[2] = make_divisible(min(args[2], max_channels) * width, 8)
elif m is RTDETRDecoder: # special case, channels arg must be passed in index 1
args.insert(1, [ch[x] for x in f])
elif m in {poolformer_s12, poolformer_s12, poolformer_s36, poolformer_m36, poolformer_m48}:
m = m(*args)
c2 = m.channel
else:
c2 = ch[f]
if isinstance(c2, list):
is_backbone = True
m_ = m
m_.backbone = True
else:
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
m.np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type = i + 4 if is_backbone else i, f, t # attach index, 'from' index, type
if verbose:
LOGGER.info(f'{i:>3}{str(f):>20}{n_:>3}{m.np:10.0f} {t:<45}{str(args):<30}') # print
save.extend(x % (i + 4 if is_backbone else i) for x in ([f] if isinstance(f, int) else f) if
x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
if isinstance(c2, list):
ch.extend(c2)
for _ in range(5 - len(ch)):
ch.insert(0, 0)
else:
ch.append(c2)
return nn.Sequential(*layers), sorted(save)由于我的模型中包含着其他多种改进,所以该?parse_model函数模块中也包含其他改进的代码,如果出现标红,把标红的改进模块删除即可。
3、创建yolov8+PoolFormer.yaml文件:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 2 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, SegNext_Attention, []] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
四、运行验证
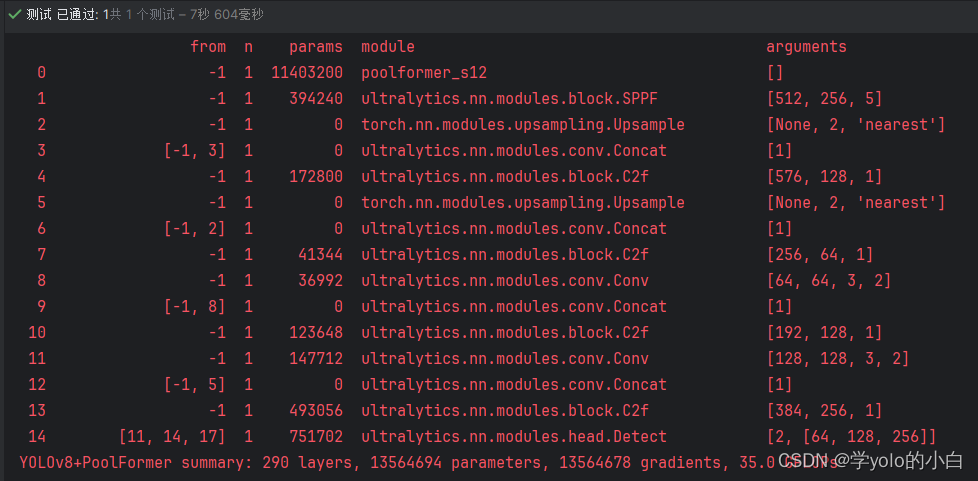
可以看出模型结构已经变成PoolFormer的主干网络。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【YOLO系列】yolo V1 ,V3,V5,V8 解释
- TDL: 十分钟讲完 60 个你需要的 Linux 命令,60 Linux Commands you NEED to know GPT
- RT-Thread入门笔记3-线程的创建
- 二维码地址门牌管理系统:智慧社区新篇章
- 烂土地提权工具
- 【C语言学习疑难杂症】第12期:如何从汇编角度深入理解y = (*--p)++这行代码(易懂版)
- 项目管理的细节-平衡
- vue中引入路径@的用法及说明
- IMX6ULL|libgpiod控制IO
- Vision Transformer原理