ResNet
目录
一、ResNet介绍
???????残差神经网络(ResNet)是由微软研究院的何恺明、张祥雨、任少卿、孙剑等人提出的。ResNet在2015 年的ILSVRC(ImageNet Large Scale Visual Recognition Challenge)中取得了冠军。
???????残差神经网络的主要贡献是解决了模型退化问题(Degradation),注意这里是模型退化而不是过拟合(模型退化是在训练和验证集效果都差,而模型过拟合是只在验证集效果差)。并针对退化现象发明了快捷连接(Shortcut connection),极大的消除了深度过大的神经网络训练困难问题。神经网络的深度首次突破了100层、最大的神经网络甚至超过了1000层。
1、深度网络的退化问题
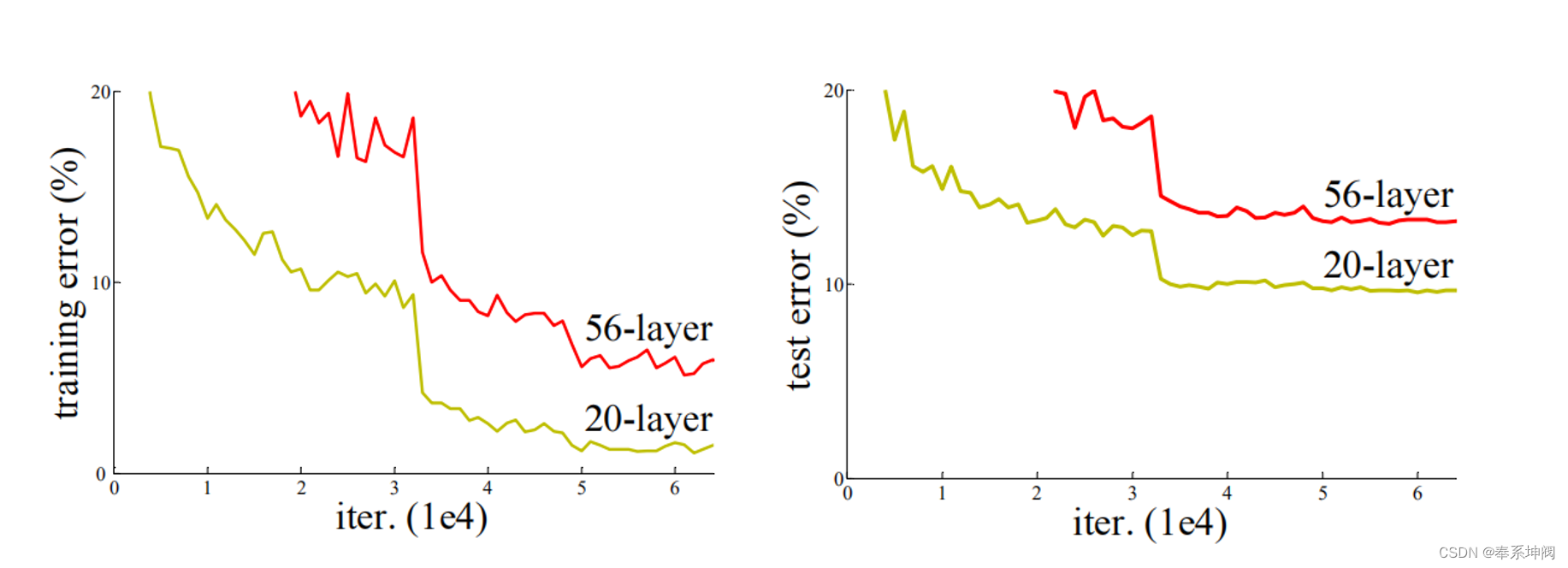
???????从经验来看,网络的深度对模型的性能至关重要,当增加网络层数后,网络可以进行更加复杂的特征模式的提取,所以当模型更深时理论上可以取得更好的结果。但是更深的网络其性能一定会更好吗?实验发现深度网络出现了退化问题(Degradation problem):网络深度增加时,网络准确度出现饱和,甚至出现下降。这个现象可以在下图中直观看出来:56层的网络比20层网络效果还要差。这不会是过拟合问题,因为56层网络的训练误差同样高。我们知道深层网络存在着梯度消失或者爆炸的问题,这使得深度学习模型很难训练。但是现在已经存在一些技术手段如BatchNorm来缓解这个问题。因此,出现深度网络的退化问题是非常令人诧异的。
2、退化问题的应对方式(残差学习)
?在ResNet网络中有如下几个亮点:
- ?????提出residual结构(残差结构),并搭建超深的网络结构(突破1000层)
- 使用批量归一化(BN层)加速训练(丢弃dropout)
???????在ResNet网络提出之前,传统的卷积神经网络都是通过将一系列卷积层与下采样层进行堆叠得到的。但是当堆叠到一定网络深度时,就会出现两个问题。
- 梯度消失或梯度爆炸
- 退化问题(degradation problem)
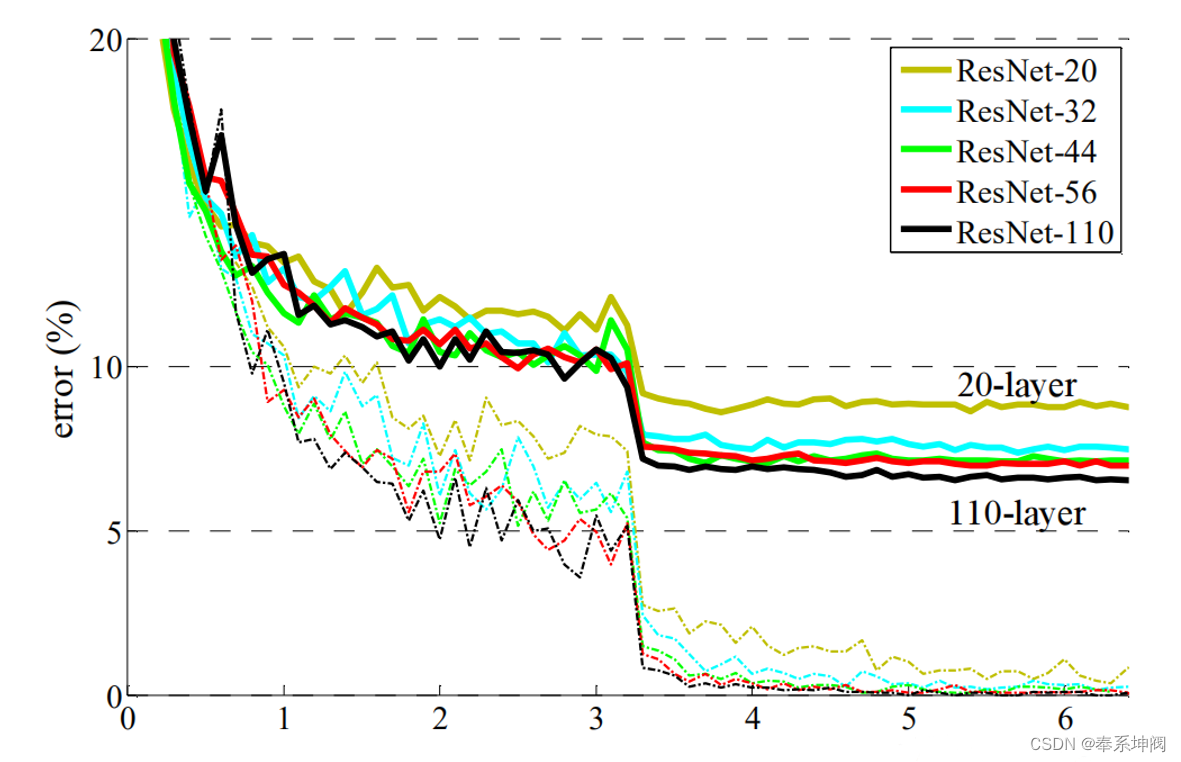
???????在ResNet论文中说通过数据的预处理以及在网络中使用BN(Batch Normalization)层能够解决梯度消失或者梯度爆炸问题。对于退化问题论文提出了residual结构(残差结构)来减轻退化问题。下图是使用residual结构的卷积网络,可以看到随着网络的不断加深,效果并没有变差,反而变的更好了。
???????深度网络的退化问题至少说明深度网络不容易训练。但是我们考虑这样一个事实:现在你有一个浅层网络,你想通过向上堆积新层来建立深层网络,一个极端情况是这些增加的层什么也不学习,仅仅复制浅层网络的特征,即这样新层是恒等映射(Identity mapping)。在这种情况下,深层网络应该至少和浅层网络性能一样,也不应该出现退化现象。
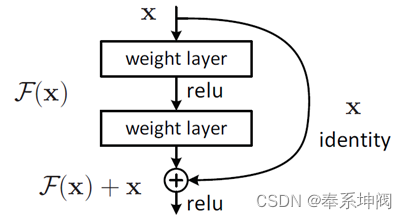
???????这个有趣的假设让何博士灵感爆发,他提出了残差学习来解决退化问题。当残差为0时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。残差学习的结构如下图所示。这有点类似与电路中的短路,所以是一种短路连接(shortcut connection)。
???????其中ResNet提出了两种映射(mapping):一种是恒等映射(identity mapping),指的就是 ,另一种residual mapping,指的就是
,所以最后的输出是?
。
???????为什么残差学习相对更容易,从直观上看残差学习需要学习的内容少,因为残差一般会比较小,学习难度小点。不过我们可以从数学的角度来分析这个问题,首先残差单元可以表示为:
???????-?:第?
?个残差单元的输入,注意每个残差单元一般包含多层结构。
???????-?:第?
?个残差单元的输出,注意每个残差单元一般包含多层结构。
???????-?:
,表示恒等映射。
???????-?:残差函数,表示学习到的残差。
???????-?:ReLU激活函数。
???????基于上式,我们求得从浅层??到深层
?的学习特征为:
???????利用链式规则,可以求得反向过程的梯度:
???????式子的第一个因子??表示的损失函数到达?
?的梯度,小括号中的
?表明短路机制可以无损地传播梯度,而另外一项残差梯度则需要经过带有weights的层,梯度不是直接传递过来的。残差梯度不会那么巧全为-1,而且就算其比较小,有?
?的存在也不会导致梯度消失。所以残差学习会更容易。要注意上面的推导并不是严格的证明。
3、ResNet的网络结构
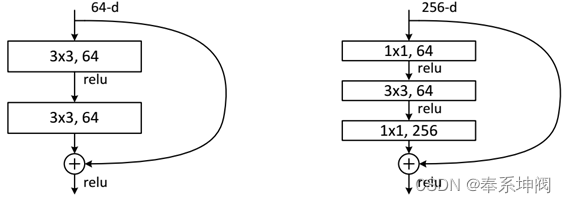
???????ResNet网络是参考了VGG19网络,在其基础上进行了修改,并通过短路机制加入了残差单元。ResNet使用两种残差单元:对于18-layer和34-layer的浅层网络,其进行的两层间的残差学习;当网络更深时,其进行的是三层间的残差学习,三层卷积核分别是1x1,3x3和1x1。如下图所示,左图对应的是浅层网络,而右图对应的是深层网络。对于短路连接,当输入和输出维度一致时,可以直接将输入加到输出上。但是当维度不一致时(对应的是维度增加一倍),这就不能直接相加。有两种策略:
???????(1)采用zero-padding增加维度:此时一般要先做一个downsample,可以采用stride=2的pooling,这样不会增加参数;
???????(2)采用新的映射(projection shortcut):一般采用1x1的卷积,这样会增加参数,也会增加计算量。短路连接除了直接使用恒等映射,当然也可以采用projection shortcut。
二、代码实现
1、ResNet块
???????ResNet沿用了VGG完整的 ?卷积层设计。残差块里首先有2个有相同输出通道数的
?卷积层。每个卷积层后接一个批量规范化层和ReLU激活函数。然后我们通过跨层数据通路,跳过这2个卷积运算,将输入直接加在最后的ReLU激活函数前。这样的设计要求2个卷积层的输出与输入形状一样,从而使它们可以相加。如果想改变通道数,就需要引入一个额外的
?卷积层来将输入变换成需要的形状后再做相加运算。残差块的实现如下:
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Residual(nn.Module):
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv: # 保证identity mapping的与residual mapping的输出形状相同(包括channel,height、width)
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
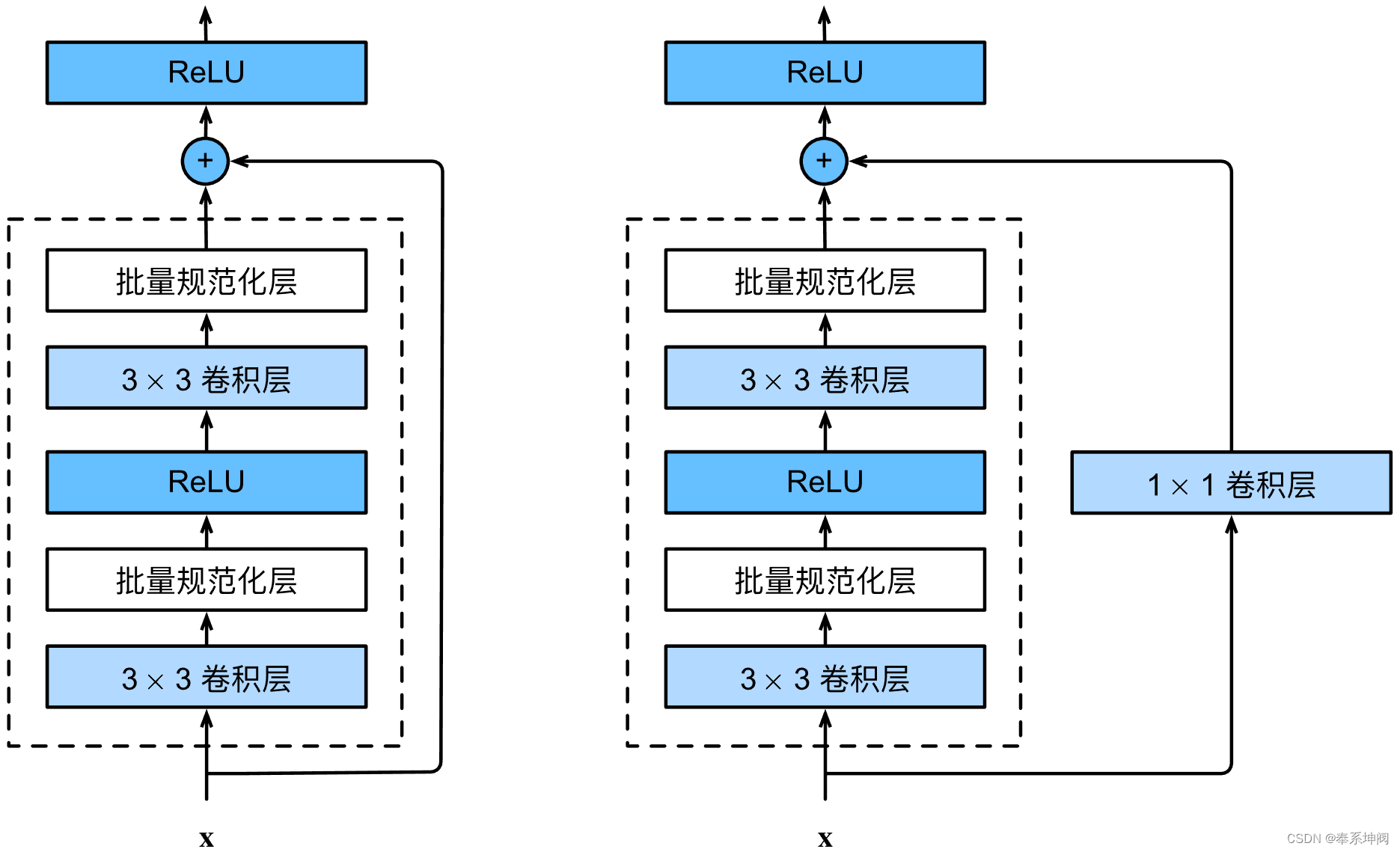
return F.relu(Y)???????此代码生成两种类型的网络:一种是当“use_1x1conv=False”时,应用ReLU非线性函数之前,将输入添加到输出。另一种是当“use_1x1conv=True”时,添加通过 ?卷积调整通道和分辨率。如下图:
???????下面我们来查看输入和输出形状一致的情况。
blk = Residual(3, 3)
X = torch.rand(4, 3, 6, 6)
Y = blk(X)
Y.shapetorch.Size([4, 3, 6, 6])???????我们也可以在增加输出通道数的同时,减半输出的高和宽。?
blk = Residual(3, 6, use_1x1conv=True, strides=2)
blk(X).shapetorch.Size([4, 6, 3, 3])2、ResNet-18模型
???????ResNet的前两层跟之前介绍的GoogLeNet中的一样:在输出通道数为64、步幅为2的 ?卷积层后,接步幅为2的
?的最大池化层。不同之处在于ResNet每个卷积层后增加了批量规范化层。
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))???????GoogLeNet在后面接了4个由Inception块组成的模块。ResNet则使用4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。第一个模块的通道数同输入通道数一致。由于之前已经使用了步幅为2的卷积层和最大池化层,所以无须减小高和宽。之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。下面我们来实现这个模块。注意,我们对第一个模块做了特别处理。
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk???????接着在ResNet加入所有残差块,这里每个模块使用2个残差块。?
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True)) # 第一个模块包含两个残差块,通道数不变,高和宽不变
b3 = nn.Sequential(*resnet_block(64, 128, 2)) # 第二个模块包含两个残差块,通道数翻倍,高和宽减半
b4 = nn.Sequential(*resnet_block(128, 256, 2)) # 第三个模块包含两个残差块,通道数翻倍,高和宽减半
b5 = nn.Sequential(*resnet_block(256, 512, 2)) # 第四个模块包含两个残差块,通道数翻倍,高和宽减半???????最后,与GoogLeNet一样,在ResNet中加入全局平均池化层,以及全连接层输出。?
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 10))???????每个模块有4个卷积层(不包括恒等映射的 ?卷积层)。加上第一个
?卷积层和最后一个全连接层,共有18层。因此,这种模型通常被称为ResNet-18。通过配置不同的通道数和模块里的残差块数可以得到不同的ResNet模型,例如更深的含152层的ResNet-152。
???????虽然ResNet的主体架构跟GoogLeNet类似,但ResNet架构更简单,修改也更方便。这些因素都导致了ResNet迅速被广泛使用。下图描述了完整的ResNet-18。
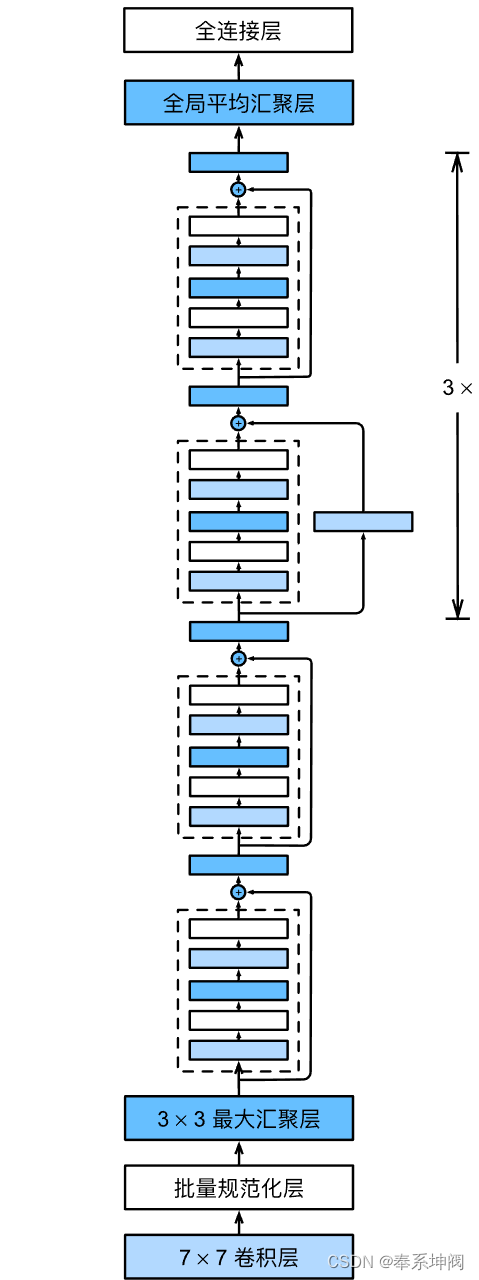
???????在训练ResNet之前,让我们观察一下ResNet中不同模块的输入形状是如何变化的。在之前所有架构中,分辨率降低,通道数量增加,直到全局平均池化层聚集所有特征。
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 128, 28, 28])
Sequential output shape: torch.Size([1, 256, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
AdaptiveAvgPool2d output shape: torch.Size([1, 512, 1, 1])
Flatten output shape: torch.Size([1, 512])
Linear output shape: torch.Size([1, 10])3、训练模型
???????我们在Fashion-MNIST数据集上训练ResNet。
lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
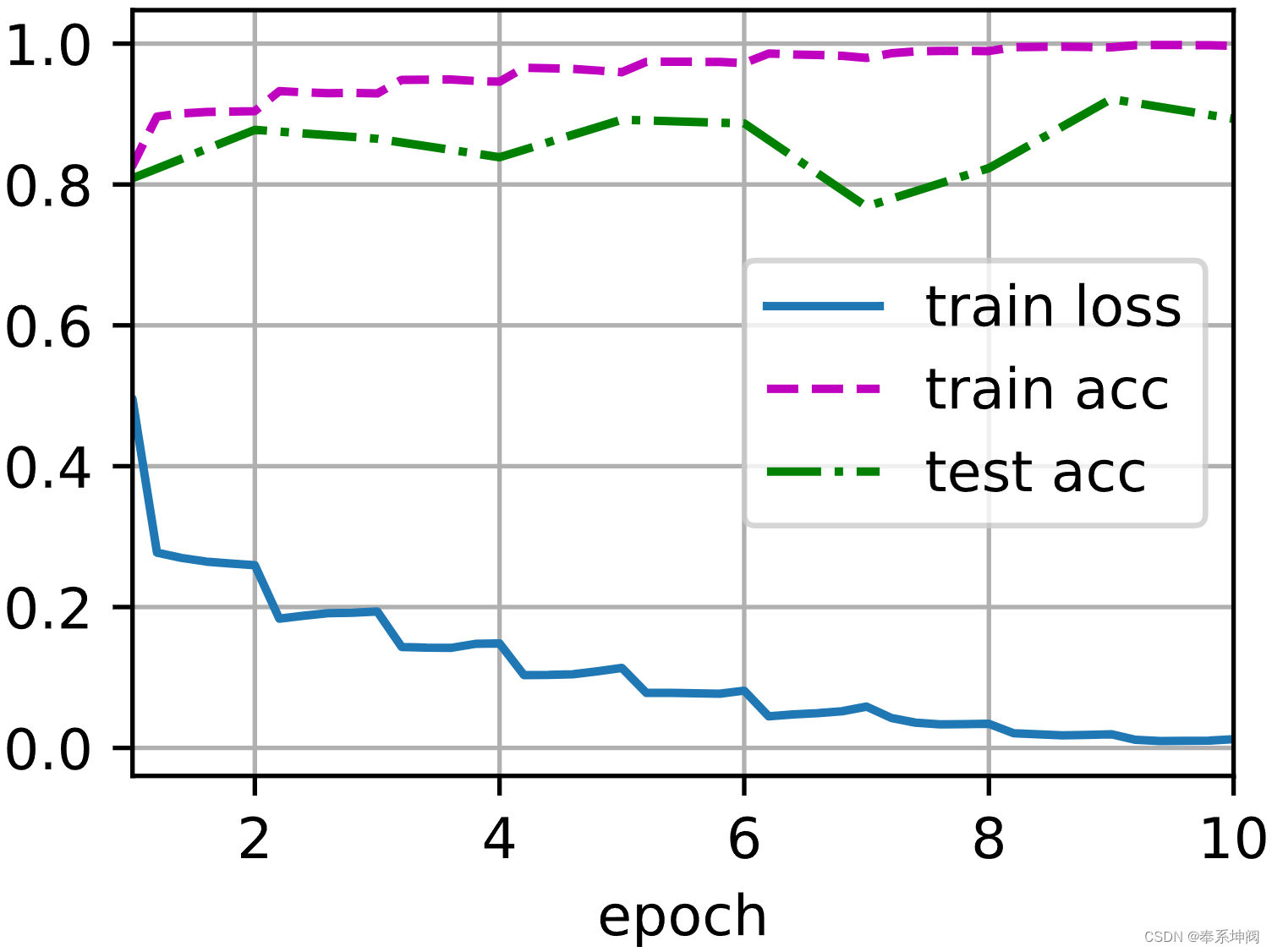
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())loss 0.012, train acc 0.997, test acc 0.893
5032.7 examples/sec on cuda:0?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:veading@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于YOLOv4开发构建道路交通场景下CCTSDB2021交通标识检测识别系统
- 钕铁硼磁钢的镀层怎么选?
- 网络舆论传播分析:自然语言处理与图分析相融合
- 嵌入式(一)嵌入式系统介绍 | 嵌入式微处理器,嵌入式系统开发流程,嵌入式系统应用
- Salesforce Optimizer
- Java关键字(1)
- 弹跳豆豆&
- 【Java基础】 一个空的Object对象到底占多少内存
- 一年百模大战下来,有哪些技术趋势和行业真相逐渐浮出水面?
- 【Docker】数据卷容器